 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Two-Stream CNN for Video Classification
Paper and Code
Apr 08, 2015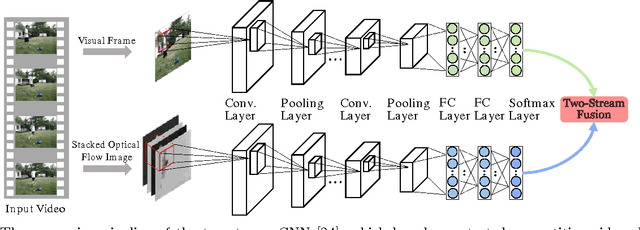
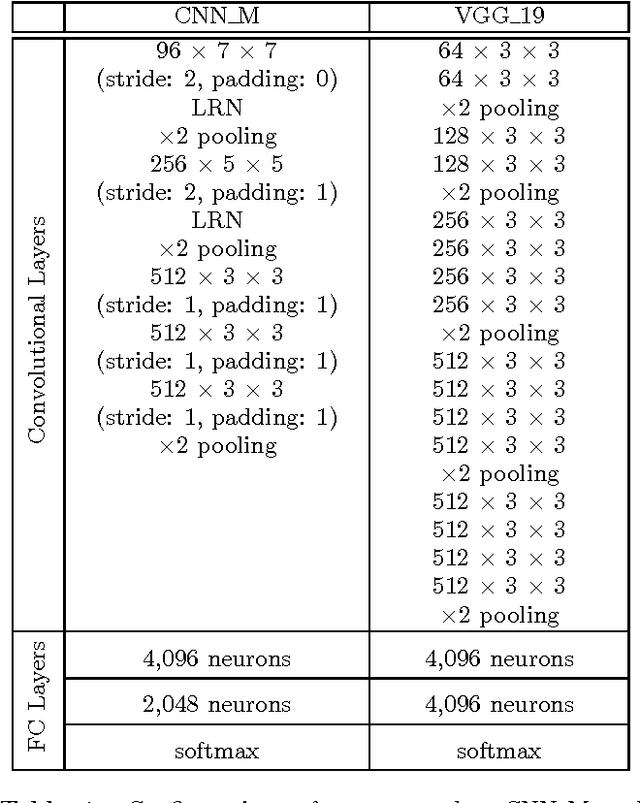
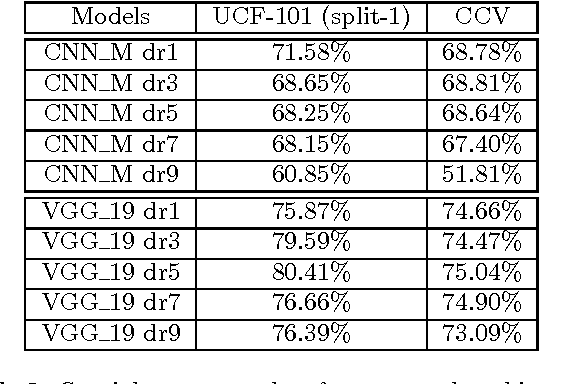
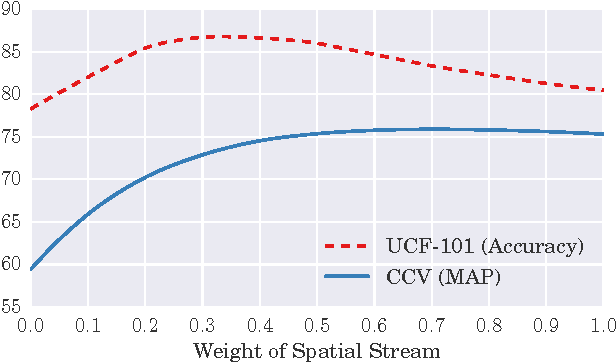
Videos contain very rich semantic information. Traditional hand-crafted features are known to be inadequate in analyzing complex video semantics. Inspired by the huge success of the deep learning methods in analyzing image, audio and text data, significant efforts are recently being devoted to the design of deep nets for video analytics. Among the many practical needs, classifying videos (or video clips) based on their major semantic categories (e.g., "skiing") is useful in many applications. In this paper, we conduct an in-depth study to investigate important implementation options that may affect the performance of deep nets on video classification. Our evaluations are conducted on top of a recent two-stream convolutional neural network (CNN) pipeline, which uses both static frames and motion optical flows, and has demonstrated competitive performance against the state-of-the-art methods. In order to gain insights and to arrive at a practical guideline, many important options are studied, including network architectures, model fusion, learning parameters and the final prediction methods. Based on the evaluations, very competitive results are attained on two popular video classification benchmarks. We hope that the discussions and conclusions from this work can help researchers in related fields to quickly set up a good basis for further investigations along this very promising direction.