 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEmbodied: A Foundation Model with Enhanced Geometric and Physical Cues for Large-Scale Embodied Environments
Apr 20, 2026Vision-Language-Action (VLA) models drive next-generation autonomous systems, but training them requires scalable, high-quality annotations from complex environments. Current cloud pipelines rely on generic vision-language models (VLMs) that lack geometric reasoning and domain semantics due to their 2D image-text pretraining. To address this mismatch, we propose XEmbodied, a cloud-side foundation model that endows VLMs with intrinsic 3D geometric awareness and interaction with physical cues (e.g., occupancy grids, 3D boxes). Instead of treating geometry as auxiliary input, XEmbodied integrates geometric representations via a structured 3D Adapter and distills physical signals into context tokens using an Efficient Image-Embodied Adapter. Through progressive domain curriculum and reinforcement learning post-training, XEmbodied preserves general capabilities while demonstrating robust performance across 18 public benchmarks. It significantly improves spatial reasoning, traffic semantics, embodied affordance, and out-of-distribution generalization for large-scale scenario mining and embodied VQA.
A Graph Foundation Model for Wireless Resource Allocation
Apr 08, 2026The aggressive densification of modern wireless networks necessitates judicious resource allocation to mitigate severe mutual interference. However, classical iterative algorithms remain computationally prohibitive for real-time applications requiring rapid responsiveness. While recent deep learning-based methods show promise, they typically function as task-specific solvers lacking the flexibility to adapt to different objectives and scenarios without expensive retraining. To address these limitations, we propose a graph foundation model for resource allocation (GFM-RA) based on a pre-training and fine-tuning paradigm to extract unified representations, thereby enabling rapid adaptation to different objectives and scenarios. Specifically, we introduce an interference-aware Transformer architecture with a bias projector that injects interference topologies into global attention mechanisms. Furthermore, we develop a hybrid self-supervised pre-training strategy that synergizes masked edge prediction with negative-free Teacher-Student contrastive learning, enabling the model to capture transferable structural representations from massive unlabeled datasets. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art performance and scales effectively with increased model capacity. Crucially, leveraging its unified representations, the foundation model exhibits exceptional sample efficiency, enabling robust few-shot adaptation to diverse and unsupervised downstream objectives in out-of-distribution (OOD) scenarios. These results demonstrate the promise of pre-trained foundation models for adaptable wireless resource allocation and provide a strong foundation for future research on generalizable learning-based wireless optimization.
Wireless Power Control Based on Large Language Models
Feb 28, 2026This paper investigates the power control problem in wireless networks by repurposing pre-trained large language models (LLMs) as relational reasoning backbones. In hyper-connected interference environments, traditional optimization methods face high computational cost, while standard message passing neural networks suffer from aggregation bottlenecks that can obscure critical high-interference structures. In response, we propose PC-LLM, a physics-informed framework that augments a pre-trained Transformer with an interference-aware attention bias. The proposed bias tuning mechanism injects the physical channel gain matrix directly into the self-attention logits, enabling explicit fusion of wireless topology with pre-trained relational priors without retraining the backbone from scratch. Extensive experiments demonstrate that PC-LLM consistently outperforms both traditional optimization methods and state-of-the-art graph neural network baselines, while exhibiting exceptional zero-shot generalization to unseen environments. We further observe a structural-semantic decoupling phenomenon: Topology-relevant relational reasoning is concentrated in shallow layers, whereas deeper layers encode task-irrelevant semantic noise. Motivated by this finding, we develop a lightweight adaptation strategy that reduces model depth by 50\%, significantly lowering inference cost while preserving state-of-the-art spectral efficiency.
Reducing Pilots in Channel Estimation With Predictive Foundation Models
Dec 17, 2025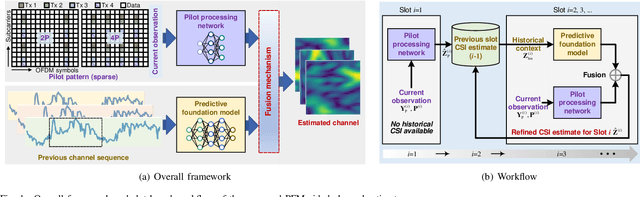
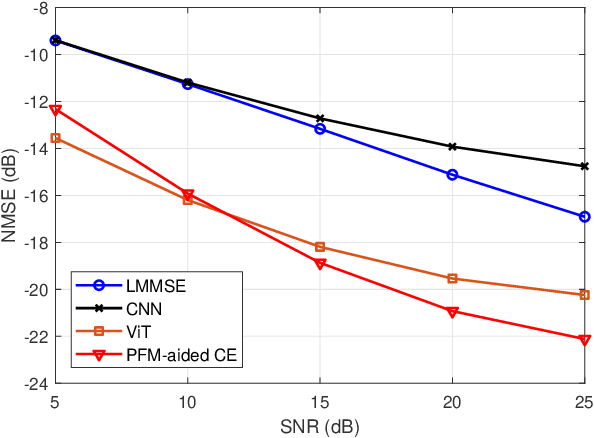
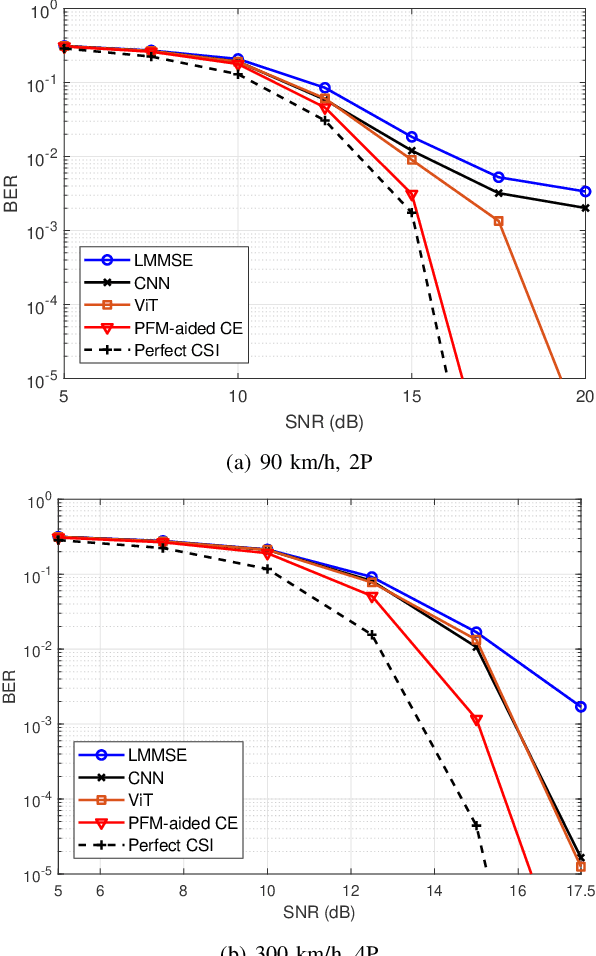
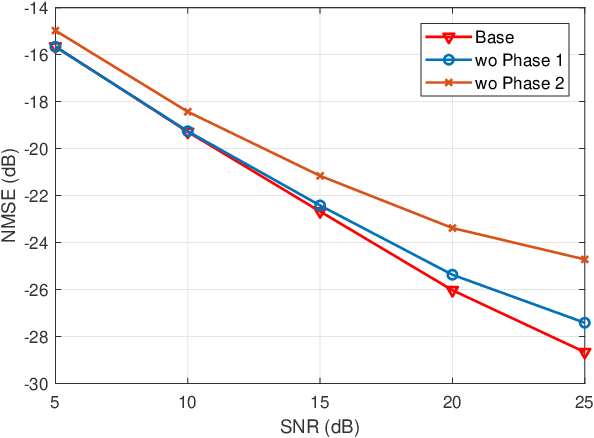
Accurate channel state information (CSI) acquisition is essential for modern wireless systems, which becomes increasingly difficult under large antenna arrays, strict pilot overhead constraints, and diverse deployment environments. Existing artificial intelligence-based solutions often lack robustness and fail to generalize across scenarios. To address this limitation, this paper introduces a predictive-foundation-model-based channel estimation framework that enables accurate, low-overhead, and generalizable CSI acquisition. The proposed framework employs a predictive foundation model trained on large-scale cross-domain CSI data to extract universal channel representations and provide predictive priors with strong cross-scenario transferability. A pilot processing network based on a vision transformer architecture is further designed to capture spatial, temporal, and frequency correlations from pilot observations. An efficient fusion mechanism integrates predictive priors with real-time measurements, enabling reliable CSI reconstruction even under sparse or noisy conditions. Extensive evaluations across diverse configurations demonstrate that the proposed estimator significantly outperforms both classical and data-driven baselines in accuracy, robustness, and generalization capability.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
SComCP: Task-Oriented Semantic Communication for Collaborative Perception
Jul 01, 2025Reliable detection of surrounding objects is critical for the safe operation of connected automated vehicles (CAVs). However, inherent limitations such as the restricted perception range and occlusion effects compromise the reliability of single-vehicle perception systems in complex traffic environments. Collaborative perception has emerged as a promising approach by fusing sensor data from surrounding CAVs with diverse viewpoints, thereby improving environmental awareness. Although collaborative perception holds great promise, its performance is bottlenecked by wireless communication constraints, as unreliable and bandwidth-limited channels hinder the transmission of sensor data necessary for real-time perception. To address these challenges, this paper proposes SComCP, a novel task-oriented semantic communication framework for collaborative perception. Specifically, SComCP integrates an importance-aware feature selection network that selects and transmits semantic features most relevant to the perception task, significantly reducing communication overhead without sacrificing accuracy. Furthermore, we design a semantic codec network based on a joint source and channel coding (JSCC) architecture, which enables bidirectional transformation between semantic features and noise-tolerant channel symbols, thereby ensuring stable perception under adverse wireless conditions. Extensive experiments demonstrate the effectiveness of the proposed framework. In particular, compared to existing approaches, SComCP can maintain superior perception performance across various channel conditions, especially in low signal-to-noise ratio (SNR) scenarios. In addition, SComCP exhibits strong generalization capability, enabling the framework to maintain high performance across diverse channel conditions, even when trained with a specific channel model.
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Power Allocation for Delay Optimization in Device-to-Device Networks: A Graph Reinforcement Learning Approach
May 19, 2025The pursuit of rate maximization in wireless communication frequently encounters substantial challenges associated with user fairness. This paper addresses these challenges by exploring a novel power allocation approach for delay optimization, utilizing graph neural networks (GNNs)-based reinforcement learning (RL) in device-to-device (D2D) communication. The proposed approach incorporates not only channel state information but also factors such as packet delay, the number of backlogged packets, and the number of transmitted packets into the components of the state information. We adopt a centralized RL method, where a central controller collects and processes the state information. The central controller functions as an agent trained using the proximal policy optimization (PPO) algorithm. To better utilize topology information in the communication network and enhance the generalization of the proposed method, we embed GNN layers into both the actor and critic networks of the PPO algorithm. This integration allows for efficient parameter updates of GNNs and enables the state information to be parameterized as a low-dimensional embedding, which is leveraged by the agent to optimize power allocation strategies. Simulation results demonstrate that the proposed method effectively reduces average delay while ensuring user fairness, outperforms baseline methods, and exhibits scalability and generalization capability.
Small-Scale-Fading-Aware Resource Allocation in Wireless Federated Learning
May 06, 2025



Judicious resource allocation can effectively enhance federated learning (FL) training performance in wireless networks by addressing both system and statistical heterogeneity. However, existing strategies typically rely on block fading assumptions, which overlooks rapid channel fluctuations within each round of FL gradient uploading, leading to a degradation in FL training performance. Therefore, this paper proposes a small-scale-fading-aware resource allocation strategy using a multi-agent reinforcement learning (MARL) framework. Specifically, we establish a one-step convergence bound of the FL algorithm and formulate the resource allocation problem as a decentralized partially observable Markov decision process (Dec-POMDP), which is subsequently solved using the QMIX algorithm. In our framework, each client serves as an agent that dynamically determines spectrum and power allocations within each coherence time slot, based on local observations and a reward derived from the convergence analysis. The MARL setting reduces the dimensionality of the action space and facilitates decentralized decision-making, enhancing the scalability and practicality of the solution. Experimental results demonstrate that our QMIX-based resource allocation strategy significantly outperforms baseline methods across various degrees of statistical heterogeneity. Additionally, ablation studies validate the critical importance of incorporating small-scale fading dynamics, highlighting its role in optimizing FL performance.