 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEmbodied: A Foundation Model with Enhanced Geometric and Physical Cues for Large-Scale Embodied Environments
Apr 20, 2026Vision-Language-Action (VLA) models drive next-generation autonomous systems, but training them requires scalable, high-quality annotations from complex environments. Current cloud pipelines rely on generic vision-language models (VLMs) that lack geometric reasoning and domain semantics due to their 2D image-text pretraining. To address this mismatch, we propose XEmbodied, a cloud-side foundation model that endows VLMs with intrinsic 3D geometric awareness and interaction with physical cues (e.g., occupancy grids, 3D boxes). Instead of treating geometry as auxiliary input, XEmbodied integrates geometric representations via a structured 3D Adapter and distills physical signals into context tokens using an Efficient Image-Embodied Adapter. Through progressive domain curriculum and reinforcement learning post-training, XEmbodied preserves general capabilities while demonstrating robust performance across 18 public benchmarks. It significantly improves spatial reasoning, traffic semantics, embodied affordance, and out-of-distribution generalization for large-scale scenario mining and embodied VQA.
SwiftGS: Episodic Priors for Immediate Satellite Surface Recovery
Mar 19, 2026Rapid, large-scale 3D reconstruction from multi-date satellite imagery is vital for environmental monitoring, urban planning, and disaster response, yet remains difficult due to illumination changes, sensor heterogeneity, and the cost of per-scene optimization. We introduce SwiftGS, a meta-learned system that reconstructs 3D surfaces in a single forward pass by predicting geometry-radiation-decoupled Gaussian primitives together with a lightweight SDF, replacing expensive per-scene fitting with episodic training that captures transferable priors. The model couples a differentiable physics graph for projection, illumination, and sensor response with spatial gating that blends sparse Gaussian detail and global SDF structure, and incorporates semantic-geometric fusion, conditional lightweight task heads, and multi-view supervision from a frozen geometric teacher under an uncertainty-aware multi-task loss. At inference, SwiftGS operates zero-shot with optional compact calibration and achieves accurate DSM reconstruction and view-consistent rendering at significantly reduced computational cost, with ablations highlighting the benefits of the hybrid representation, physics-aware rendering, and episodic meta-training.
Missing-by-Design: Certifiable Modality Deletion for Revocable Multimodal Sentiment Analysis
Feb 18, 2026As multimodal systems increasingly process sensitive personal data, the ability to selectively revoke specific data modalities has become a critical requirement for privacy compliance and user autonomy. We present Missing-by-Design (MBD), a unified framework for revocable multimodal sentiment analysis that combines structured representation learning with a certifiable parameter-modification pipeline. Revocability is critical in privacy-sensitive applications where users or regulators may request removal of modality-specific information. MBD learns property-aware embeddings and employs generator-based reconstruction to recover missing channels while preserving task-relevant signals. For deletion requests, the framework applies saliency-driven candidate selection and a calibrated Gaussian update to produce a machine-verifiable Modality Deletion Certificate. Experiments on benchmark datasets show that MBD achieves strong predictive performance under incomplete inputs and delivers a practical privacy-utility trade-off, positioning surgical unlearning as an efficient alternative to full retraining.
Smooth Operator: Smooth Verifiable Reward Activates Spatial Reasoning Ability of Vision-Language Model
Jan 12, 2026Vision-Language Models (VLMs) face a critical bottleneck in achieving precise numerical prediction for 3D scene understanding. Traditional reinforcement learning (RL) approaches, primarily based on relative ranking, often suffer from severe reward sparsity and gradient instability, failing to effectively exploit the verifiable signals provided by 3D physical constraints. Notably, in standard GRPO frameworks, relative normalization causes "near-miss" samples (characterized by small but non-zero errors) to suffer from advantage collapse. This leads to a severe data utilization bottleneck where valuable boundary samples are discarded during optimization. To address this, we introduce the Smooth Numerical Reward Activation (SNRA) operator and the Absolute-Preserving GRPO (AP-GRPO) framework. SNRA employs a dynamically parameterized Sigmoid function to transform raw feedback into a dense, continuous reward continuum. Concurrently, AP-GRPO integrates absolute scalar gradients to mitigate the numerical information loss inherent in conventional relative-ranking mechanisms. By leveraging this approach, we constructed Numerical3D-50k, a dataset comprising 50,000 verifiable 3D subtasks. Empirical results indicate that AP-GRPO achieves performance parity with large-scale supervised methods while maintaining higher data efficiency, effectively activating latent 3D reasoning in VLMs without requiring architectural modifications.
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
POD: Predictive Object Detection with Single-Frame FMCW LiDAR Point Cloud
Apr 08, 2025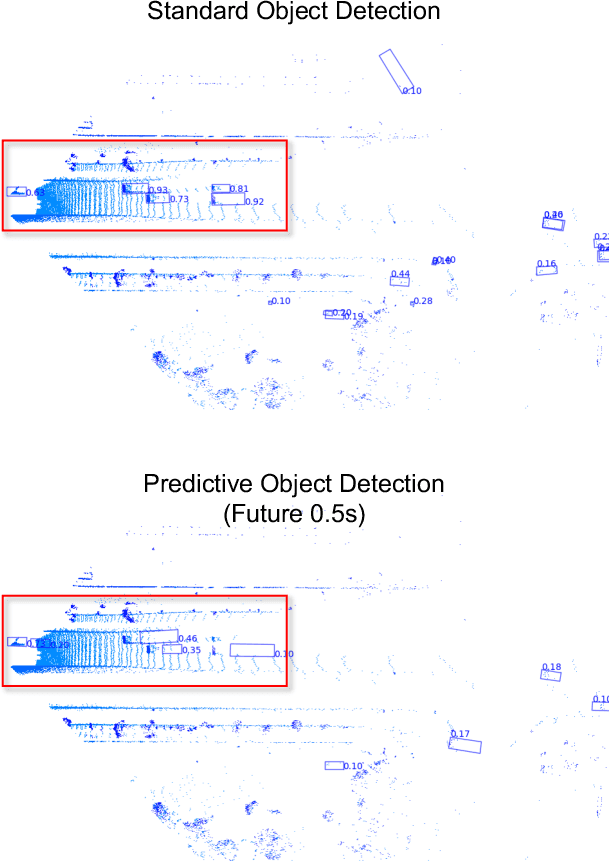
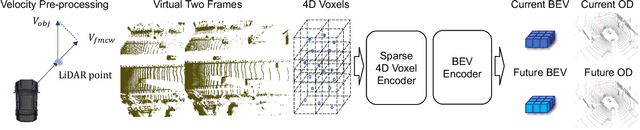
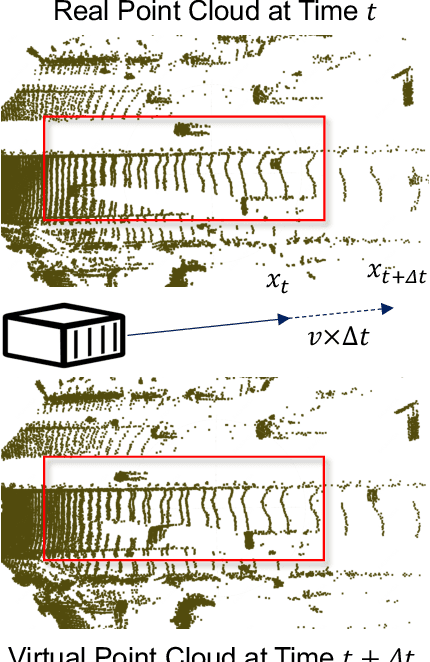
LiDAR-based 3D object detection is a fundamental task in the field of autonomous driving. This paper explores the unique advantage of Frequency Modulated Continuous Wave (FMCW) LiDAR in autonomous perception. Given a single frame FMCW point cloud with radial velocity measurements, we expect that our object detector can detect the short-term future locations of objects using only the current frame sensor data and demonstrate a fast ability to respond to intermediate danger. To achieve this, we extend the standard object detection task to a novel task named predictive object detection (POD), which aims to predict the short-term future location and dimensions of objects based solely on current observations. Typically, a motion prediction task requires historical sensor information to process the temporal contexts of each object, while our detector's avoidance of multi-frame historical information enables a much faster response time to potential dangers. The core advantage of FMCW LiDAR lies in the radial velocity associated with every reflected point. We propose a novel POD framework, the core idea of which is to generate a virtual future point using a ray casting mechanism, create virtual two-frame point clouds with the current and virtual future frames, and encode these two-frame voxel features with a sparse 4D encoder. Subsequently, the 4D voxel features are separated by temporal indices and remapped into two Bird's Eye View (BEV) features: one decoded for standard current frame object detection and the other for future predictive object detection. Extensive experiments on our in-house dataset demonstrate the state-of-the-art standard and predictive detection performance of the proposed POD framework.
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
LEGO-Motion: Learning-Enhanced Grids with Occupancy Instance Modeling for Class-Agnostic Motion Prediction
Mar 10, 2025



Accurate and reliable spatial and motion information plays a pivotal role in autonomous driving systems. However, object-level perception models struggle with handling open scenario categories and lack precise intrinsic geometry. On the other hand, occupancy-based class-agnostic methods excel in representing scenes but fail to ensure physics consistency and ignore the importance of interactions between traffic participants, hindering the model's ability to learn accurate and reliable motion. In this paper, we introduce a novel occupancy-instance modeling framework for class-agnostic motion prediction tasks, named LEGO-Motion, which incorporates instance features into Bird's Eye View (BEV) space. Our model comprises (1) a BEV encoder, (2) an Interaction-Augmented Instance Encoder, and (3) an Instance-Enhanced BEV Encoder, improving both interaction relationships and physics consistency within the model, thereby ensuring a more accurate and robust understanding of the environment. Extensive experiments on the nuScenes dataset demonstrate that our method achieves state-of-the-art performance, outperforming existing approaches. Furthermore, the effectiveness of our framework is validated on the advanced FMCW LiDAR benchmark, showcasing its practical applicability and generalization capabilities. The code will be made publicly available to facilitate further research.
PriorMotion: Generative Class-Agnostic Motion Prediction with Raster-Vector Motion Field Priors
Dec 05, 2024



Reliable perception of spatial and motion information is crucial for safe autonomous navigation. Traditional approaches typically fall into two categories: object-centric and class-agnostic methods. While object-centric methods often struggle with missed detections, leading to inaccuracies in motion prediction, many class-agnostic methods focus heavily on encoder design, often overlooking important priors like rigidity and temporal consistency, leading to suboptimal performance, particularly with sparse LiDAR data at distant region. To address these issues, we propose $\textbf{PriorMotion}$, a generative framework that extracts rasterized and vectorized scene representations to model spatio-temporal priors. Our model comprises a BEV encoder, an Raster-Vector prior Encoder, and a Spatio-Temporal prior Generator, improving both spatial and temporal consistency in motion prediction. Additionally, we introduce a standardized evaluation protocol for class-agnostic motion prediction. Experiments on the nuScenes dataset show that PriorMotion achieves state-of-the-art performance, with further validation on advanced FMCW LiDAR confirming its robustness.
FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback
Nov 27, 2024



Ensuring safe, comfortable, and efficient navigation is a critical goal for autonomous driving systems. While end-to-end models trained on large-scale datasets excel in common driving scenarios, they often struggle with rare, long-tail events. Recent progress in large language models (LLMs) has introduced enhanced reasoning capabilities, but their computational demands pose challenges for real-time decision-making and precise planning. This paper presents FASIONAD, a novel dual-system framework inspired by the cognitive model "Thinking, Fast and Slow." The fast system handles routine navigation tasks using rapid, data-driven path planning, while the slow system focuses on complex reasoning and decision-making in challenging or unfamiliar situations. A dynamic switching mechanism based on score distribution and feedback allows seamless transitions between the two systems. Visual prompts generated by the fast system enable human-like reasoning in the slow system, which provides high-quality feedback to enhance the fast system's decision-making. To evaluate FASIONAD, we introduce a new benchmark derived from the nuScenes dataset, specifically designed to differentiate fast and slow scenarios. FASIONAD achieves state-of-the-art performance on this benchmark, establishing a new standard for frameworks integrating fast and slow cognitive processes in autonomous driving. This approach paves the way for more adaptive, human-like autonomous driving systems.