 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoSSC: Exploring Monocular Panoptic 3D Scene Reconstruction for Autonomous Driving
Jun 11, 2024



Vision-centric occupancy networks, which represent the surrounding environment with uniform voxels with semantics, have become a new trend for safe driving of camera-only autonomous driving perception systems, as they are able to detect obstacles regardless of their shape and occlusion. Modern occupancy networks mainly focus on reconstructing visible voxels from object surfaces with voxel-wise semantic prediction. Usually, they suffer from inconsistent predictions of one object and mixed predictions for adjacent objects. These confusions may harm the safety of downstream planning modules. To this end, we investigate panoptic segmentation on 3D voxel scenarios and propose an instance-aware occupancy network, PanoSSC. We predict foreground objects and backgrounds separately and merge both in post-processing. For foreground instance grouping, we propose a novel 3D instance mask decoder that can efficiently extract individual objects. we unify geometric reconstruction, 3D semantic segmentation, and 3D instance segmentation into PanoSSC framework and propose new metrics for evaluating panoptic voxels. Extensive experiments show that our method achieves competitive results on SemanticKITTI semantic scene completion benchmark.
EFFOcc: A Minimal Baseline for EFficient Fusion-based 3D Occupancy Network
Jun 11, 2024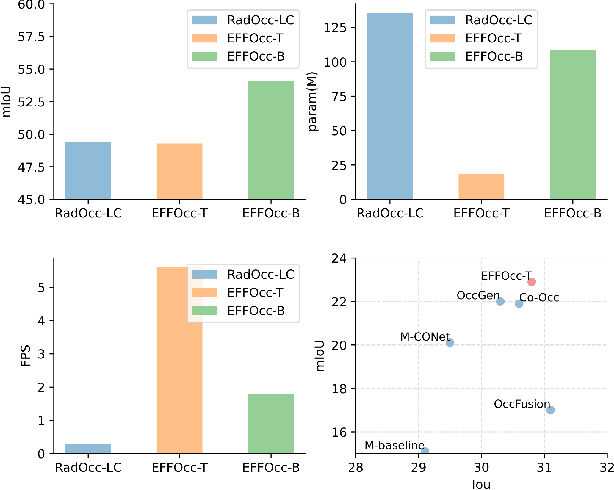
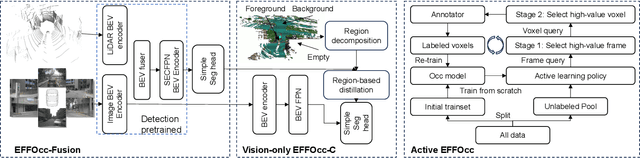
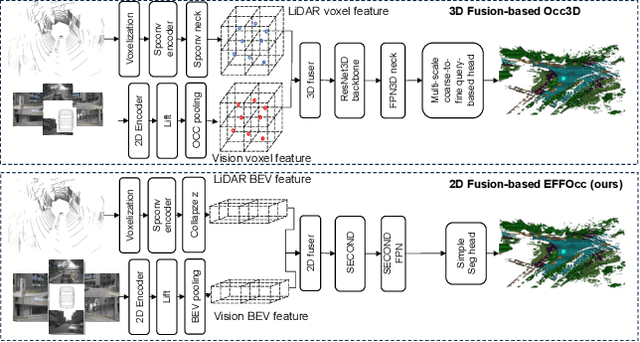

3D occupancy prediction (Occ) is a rapidly rising challenging perception task in the field of autonomous driving which represents the driving scene as uniformly partitioned 3D voxel grids with semantics. Compared to 3D object detection, grid perception has great advantage of better recognizing irregularly shaped, unknown category, or partially occluded general objects. However, existing 3D occupancy networks (occnets) are both computationally heavy and label-hungry. In terms of model complexity, occnets are commonly composed of heavy Conv3D modules or transformers on the voxel level. In terms of label annotations requirements, occnets are supervised with large-scale expensive dense voxel labels. Model and data inefficiency, caused by excessive network parameters and label annotations requirement, severely hinder the onboard deployment of occnets. This paper proposes an efficient 3d occupancy network (EFFOcc), that targets the minimal network complexity and label requirement while achieving state-of-the-art accuracy. EFFOcc only uses simple 2D operators, and improves Occ accuracy to the state-of-the-art on multiple large-scale benchmarks: Occ3D-nuScenes, Occ3D-Waymo, and OpenOccupancy-nuScenes. On Occ3D-nuScenes benchmark, EFFOcc has only 18.4M parameters, and achieves 50.46 in terms of mean IoU (mIoU), to our knowledge, it is the occnet with minimal parameters compared with related occnets. Moreover, we propose a two-stage active learning strategy to reduce the requirements of labelled data. Active EFFOcc trained with 6\% labelled voxels achieves 47.19 mIoU, which is 95.7% fully supervised performance. The proposed EFFOcc also supports improved vision-only occupancy prediction with the aid of region-decomposed distillation. Code and demo videos will be available at https://github.com/synsin0/EFFOcc.
Grid-Centric Traffic Scenario Perception for Autonomous Driving: A Comprehensive Review
Mar 02, 2023



Grid-centric perception is a crucial field for mobile robot perception and navigation. Nonetheless, grid-centric perception is less prevalent than object-centric perception for autonomous driving as autonomous vehicles need to accurately perceive highly dynamic, large-scale outdoor traffic scenarios and the complexity and computational costs of grid-centric perception are high. The rapid development of deep learning techniques and hardware gives fresh insights into the evolution of grid-centric perception and enables the deployment of many real-time algorithms. Current industrial and academic research demonstrates the great advantages of grid-centric perception, such as comprehensive fine-grained environmental representation, greater robustness to occlusion, more efficient sensor fusion, and safer planning policies. Given the lack of current surveys for this rapidly expanding field, we present a hierarchically-structured review of grid-centric perception for autonomous vehicles. We organize previous and current knowledge of occupancy grid techniques and provide a systematic in-depth analysis of algorithms in terms of three aspects: feature representation, data utility, and applications in autonomous driving systems. Lastly, we present a summary of the current research trend and provide some probable future outlooks.
FusionMotion: Multi-Sensor Asynchronous Fusion for Continuous Occupancy Prediction via Neural-ODE
Feb 19, 2023



Occupancy maps are widely recognized as an efficient method for facilitating robot motion planning in static environments. However, for intelligent vehicles, occupancy of both the present and future moments is required to ensure safe driving. In the automotive industry, the accurate and continuous prediction of future occupancy maps in traffic scenarios remains a formidable challenge. This paper investigates multi-sensor spatio-temporal fusion strategies for continuous occupancy prediction in a systematic manner. This paper presents FusionMotion, a novel bird's eye view (BEV) occupancy predictor which is capable of achieving the fusion of asynchronous multi-sensor data and predicting the future occupancy map with variable time intervals and temporal horizons. Remarkably, FusionMotion features the adoption of neural ordinary differential equations on recurrent neural networks for occupancy prediction. FusionMotion learns derivatives of BEV features over temporal horizons, updates the implicit sensor's BEV feature measurements and propagates future states for each ODE step. Extensive experiments on large-scale nuScenes and Lyft L5 datasets demonstrate that FusionMotion significantly outperforms previous methods. In addition, it outperforms the BEVFusion-style fusion strategy on the Lyft L5 dataset while reducing synchronization requirements. Codes and models will be made available.