 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOME: Adding Scene-Centric Forecasting Control to Occupancy World Model
Jun 16, 2025World models are critical for autonomous driving to simulate environmental dynamics and generate synthetic data. Existing methods struggle to disentangle ego-vehicle motion (perspective shifts) from scene evolvement (agent interactions), leading to suboptimal predictions. Instead, we propose to separate environmental changes from ego-motion by leveraging the scene-centric coordinate systems. In this paper, we introduce COME: a framework that integrates scene-centric forecasting Control into the Occupancy world ModEl. Specifically, COME first generates ego-irrelevant, spatially consistent future features through a scene-centric prediction branch, which are then converted into scene condition using a tailored ControlNet. These condition features are subsequently injected into the occupancy world model, enabling more accurate and controllable future occupancy predictions. Experimental results on the nuScenes-Occ3D dataset show that COME achieves consistent and significant improvements over state-of-the-art (SOTA) methods across diverse configurations, including different input sources (ground-truth, camera-based, fusion-based occupancy) and prediction horizons (3s and 8s). For example, under the same settings, COME achieves 26.3% better mIoU metric than DOME and 23.7% better mIoU metric than UniScene. These results highlight the efficacy of disentangled representation learning in enhancing spatio-temporal prediction fidelity for world models. Code and videos will be available at https://github.com/synsin0/COME.
CleanMAP: Distilling Multimodal LLMs for Confidence-Driven Crowdsourced HD Map Updates
Apr 14, 2025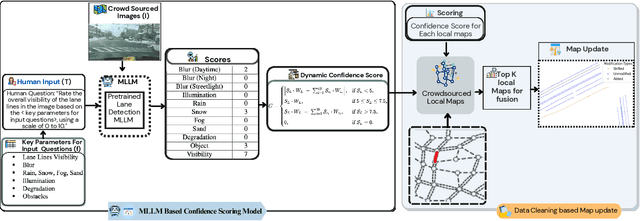
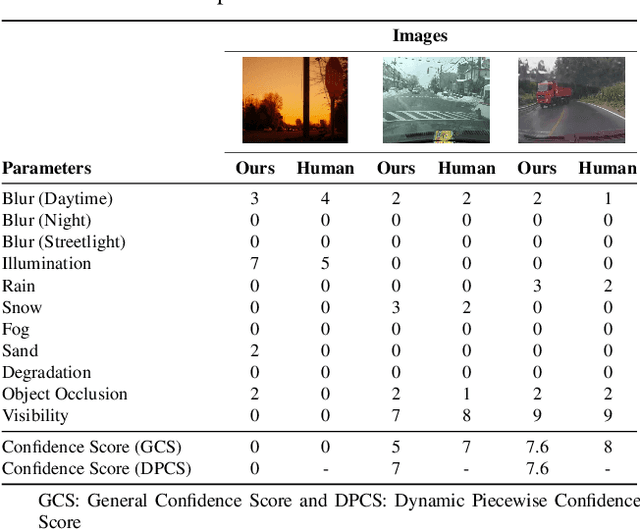
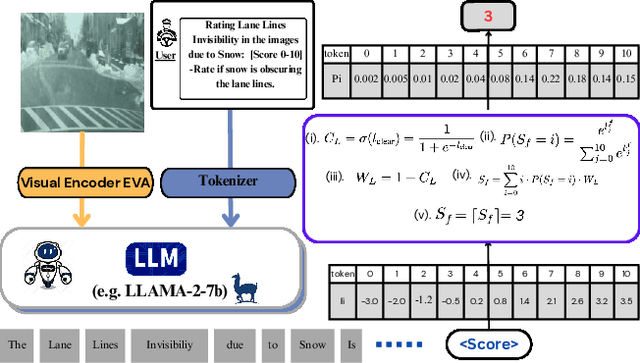

The rapid growth of intelligent connected vehicles (ICVs) and integrated vehicle-road-cloud systems has increased the demand for accurate, real-time HD map updates. However, ensuring map reliability remains challenging due to inconsistencies in crowdsourced data, which suffer from motion blur, lighting variations, adverse weather, and lane marking degradation. This paper introduces CleanMAP, a Multimodal Large Language Model (MLLM)-based distillation framework designed to filter and refine crowdsourced data for high-confidence HD map updates. CleanMAP leverages an MLLM-driven lane visibility scoring model that systematically quantifies key visual parameters, assigning confidence scores (0-10) based on their impact on lane detection. A novel dynamic piecewise confidence-scoring function adapts scores based on lane visibility, ensuring strong alignment with human evaluations while effectively filtering unreliable data. To further optimize map accuracy, a confidence-driven local map fusion strategy ranks and selects the top-k highest-scoring local maps within an optimal confidence range (best score minus 10%), striking a balance between data quality and quantity. Experimental evaluations on a real-world autonomous vehicle dataset validate CleanMAP's effectiveness, demonstrating that fusing the top three local maps achieves the lowest mean map update error of 0.28m, outperforming the baseline (0.37m) and meeting stringent accuracy thresholds (<= 0.32m). Further validation with real-vehicle data confirms 84.88% alignment with human evaluators, reinforcing the model's robustness and reliability. This work establishes CleanMAP as a scalable and deployable solution for crowdsourced HD map updates, ensuring more precise and reliable autonomous navigation. The code will be available at https://Ankit-Zefan.github.io/CleanMap/
POD: Predictive Object Detection with Single-Frame FMCW LiDAR Point Cloud
Apr 08, 2025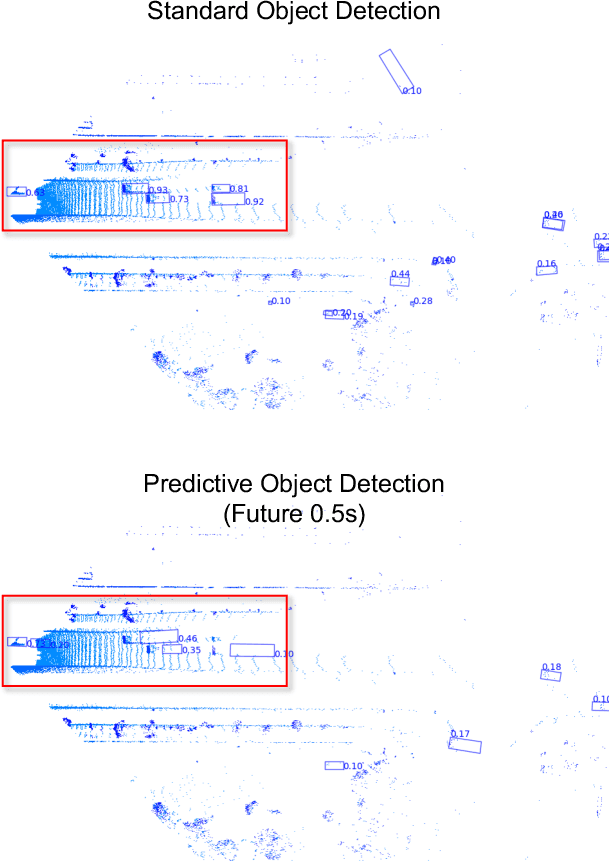
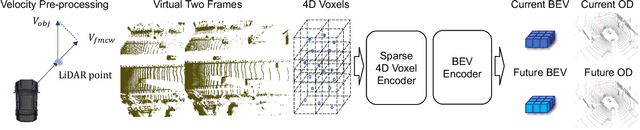
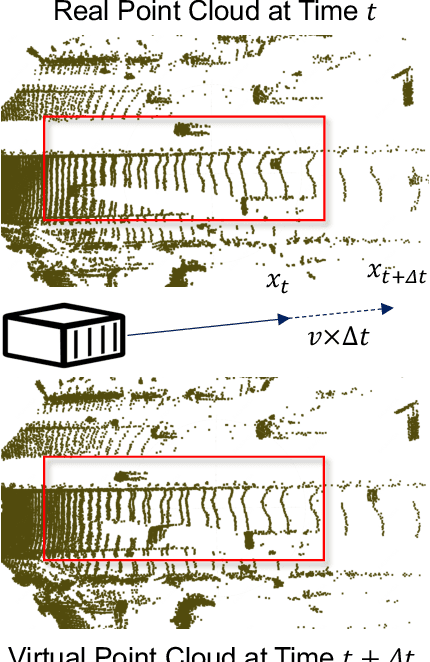
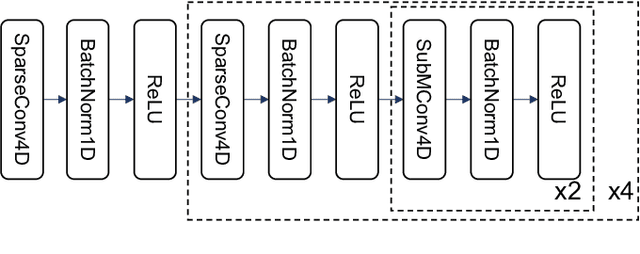
LiDAR-based 3D object detection is a fundamental task in the field of autonomous driving. This paper explores the unique advantage of Frequency Modulated Continuous Wave (FMCW) LiDAR in autonomous perception. Given a single frame FMCW point cloud with radial velocity measurements, we expect that our object detector can detect the short-term future locations of objects using only the current frame sensor data and demonstrate a fast ability to respond to intermediate danger. To achieve this, we extend the standard object detection task to a novel task named predictive object detection (POD), which aims to predict the short-term future location and dimensions of objects based solely on current observations. Typically, a motion prediction task requires historical sensor information to process the temporal contexts of each object, while our detector's avoidance of multi-frame historical information enables a much faster response time to potential dangers. The core advantage of FMCW LiDAR lies in the radial velocity associated with every reflected point. We propose a novel POD framework, the core idea of which is to generate a virtual future point using a ray casting mechanism, create virtual two-frame point clouds with the current and virtual future frames, and encode these two-frame voxel features with a sparse 4D encoder. Subsequently, the 4D voxel features are separated by temporal indices and remapped into two Bird's Eye View (BEV) features: one decoded for standard current frame object detection and the other for future predictive object detection. Extensive experiments on our in-house dataset demonstrate the state-of-the-art standard and predictive detection performance of the proposed POD framework.
Advancing Autonomous Vehicle Intelligence: Deep Learning and Multimodal LLM for Traffic Sign Recognition and Robust Lane Detection
Mar 08, 2025Autonomous vehicles (AVs) require reliable traffic sign recognition and robust lane detection capabilities to ensure safe navigation in complex and dynamic environments. This paper introduces an integrated approach combining advanced deep learning techniques and Multimodal Large Language Models (MLLMs) for comprehensive road perception. For traffic sign recognition, we systematically evaluate ResNet-50, YOLOv8, and RT-DETR, achieving state-of-the-art performance of 99.8% with ResNet-50, 98.0% accuracy with YOLOv8, and achieved 96.6% accuracy in RT-DETR despite its higher computational complexity. For lane detection, we propose a CNN-based segmentation method enhanced by polynomial curve fitting, which delivers high accuracy under favorable conditions. Furthermore, we introduce a lightweight, Multimodal, LLM-based framework that directly undergoes instruction tuning using small yet diverse datasets, eliminating the need for initial pretraining. This framework effectively handles various lane types, complex intersections, and merging zones, significantly enhancing lane detection reliability by reasoning under adverse conditions. Despite constraints in available training resources, our multimodal approach demonstrates advanced reasoning capabilities, achieving a Frame Overall Accuracy (FRM) of 53.87%, a Question Overall Accuracy (QNS) of 82.83%, lane detection accuracies of 99.6% in clear conditions and 93.0% at night, and robust performance in reasoning about lane invisibility due to rain (88.4%) or road degradation (95.6%). The proposed comprehensive framework markedly enhances AV perception reliability, thus contributing significantly to safer autonomous driving across diverse and challenging road scenarios.
Residual Learning towards High-fidelity Vehicle Dynamics Modeling with Transformer
Feb 17, 2025The vehicle dynamics model serves as a vital component of autonomous driving systems, as it describes the temporal changes in vehicle state. In a long period, researchers have made significant endeavors to accurately model vehicle dynamics. Traditional physics-based methods employ mathematical formulae to model vehicle dynamics, but they are unable to adequately describe complex vehicle systems due to the simplifications they entail. Recent advancements in deep learning-based methods have addressed this limitation by directly regressing vehicle dynamics. However, the performance and generalization capabilities still require further enhancement. In this letter, we address these problems by proposing a vehicle dynamics correction system that leverages deep neural networks to correct the state residuals of a physical model instead of directly estimating the states. This system greatly reduces the difficulty of network learning and thus improves the estimation accuracy of vehicle dynamics. Furthermore, we have developed a novel Transformer-based dynamics residual correction network, DyTR. This network implicitly represents state residuals as high-dimensional queries, and iteratively updates the estimated residuals by interacting with dynamics state features. The experiments in simulations demonstrate the proposed system works much better than physics model, and our proposed DyTR model achieves the best performances on dynamics state residual correction task, reducing the state prediction errors of a simple 3 DoF vehicle model by an average of 92.3% and 59.9% in two dataset, respectively.
Enhancing Lane Segment Perception and Topology Reasoning with Crowdsourcing Trajectory Priors
Nov 26, 2024In autonomous driving, recent advances in lane segment perception provide autonomous vehicles with a comprehensive understanding of driving scenarios. Moreover, incorporating prior information input into such perception model represents an effective approach to ensure the robustness and accuracy. However, utilizing diverse sources of prior information still faces three key challenges: the acquisition of high-quality prior information, alignment between prior and online perception, efficient integration. To address these issues, we investigate prior augmentation from a novel perspective of trajectory priors. In this paper, we initially extract crowdsourcing trajectory data from Argoverse2 motion forecasting dataset and encode trajectory data into rasterized heatmap and vectorized instance tokens, then we incorporate such prior information into the online mapping model through different ways. Besides, with the purpose of mitigating the misalignment between prior and online perception, we design a confidence-based fusion module that takes alignment into account during the fusion process. We conduct extensive experiments on OpenLane-V2 dataset. The results indicate that our method's performance significantly outperforms the current state-of-the-art methods.
High Definition Map Mapping and Update: A General Overview and Future Directions
Sep 15, 2024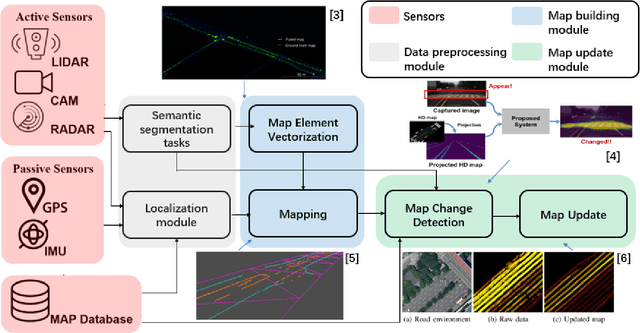
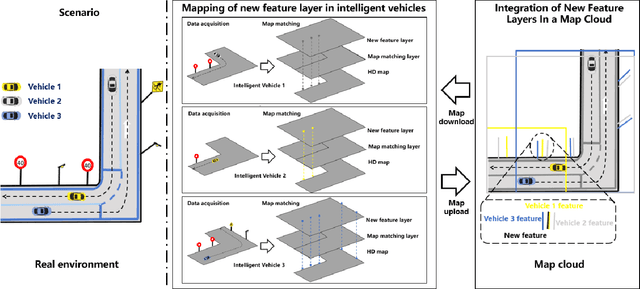
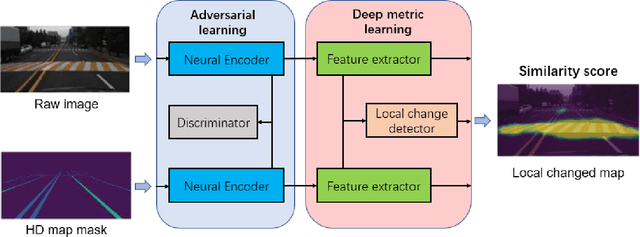
Along with the rapid growth of autonomous vehicles (AVs), more and more demands are required for environment perception technology. Among others, HD mapping has become one of the more prominent roles in helping the vehicle realize essential tasks such as localization and path planning. While increasing research efforts have been directed toward HD Map development. However, a comprehensive overview of the overall HD map mapping and update framework is still lacking. This article introduces the development and current state of the algorithm involved in creating HD map mapping and its maintenance. As part of this study, the primary data preprocessing approach of processing raw data to information ready to feed for mapping and update purposes, semantic segmentation, and localization are also briefly reviewed. Moreover, the map taxonomy, ontology, and quality assessment are extensively discussed, the map data's general representation method is presented, and the mapping algorithm ranging from SLAM to transformers learning-based approaches are also discussed. The development of the HD map update algorithm, from change detection to the update methods, is also presented. Finally, the authors discuss possible future developments and the remaining challenges in HD map mapping and update technology. This paper simultaneously serves as a position paper and tutorial to those new to HD map mapping and update domains.
EFFOcc: A Minimal Baseline for EFficient Fusion-based 3D Occupancy Network
Jun 11, 2024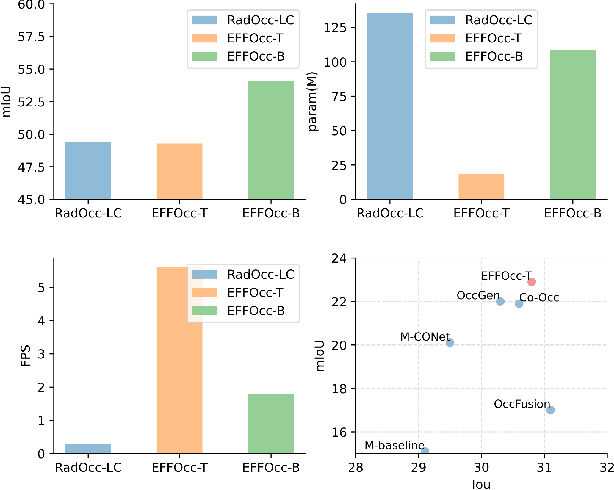
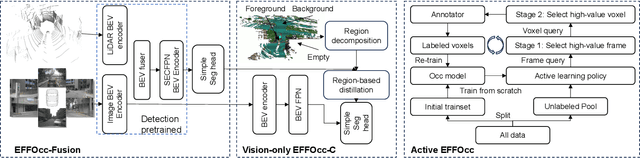
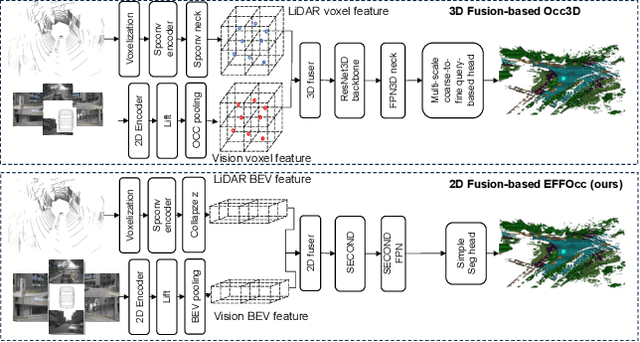

3D occupancy prediction (Occ) is a rapidly rising challenging perception task in the field of autonomous driving which represents the driving scene as uniformly partitioned 3D voxel grids with semantics. Compared to 3D object detection, grid perception has great advantage of better recognizing irregularly shaped, unknown category, or partially occluded general objects. However, existing 3D occupancy networks (occnets) are both computationally heavy and label-hungry. In terms of model complexity, occnets are commonly composed of heavy Conv3D modules or transformers on the voxel level. In terms of label annotations requirements, occnets are supervised with large-scale expensive dense voxel labels. Model and data inefficiency, caused by excessive network parameters and label annotations requirement, severely hinder the onboard deployment of occnets. This paper proposes an efficient 3d occupancy network (EFFOcc), that targets the minimal network complexity and label requirement while achieving state-of-the-art accuracy. EFFOcc only uses simple 2D operators, and improves Occ accuracy to the state-of-the-art on multiple large-scale benchmarks: Occ3D-nuScenes, Occ3D-Waymo, and OpenOccupancy-nuScenes. On Occ3D-nuScenes benchmark, EFFOcc has only 18.4M parameters, and achieves 50.46 in terms of mean IoU (mIoU), to our knowledge, it is the occnet with minimal parameters compared with related occnets. Moreover, we propose a two-stage active learning strategy to reduce the requirements of labelled data. Active EFFOcc trained with 6\% labelled voxels achieves 47.19 mIoU, which is 95.7% fully supervised performance. The proposed EFFOcc also supports improved vision-only occupancy prediction with the aid of region-decomposed distillation. Code and demo videos will be available at https://github.com/synsin0/EFFOcc.
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
May 03, 2024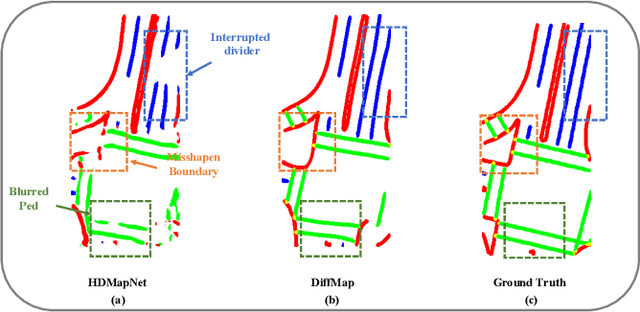
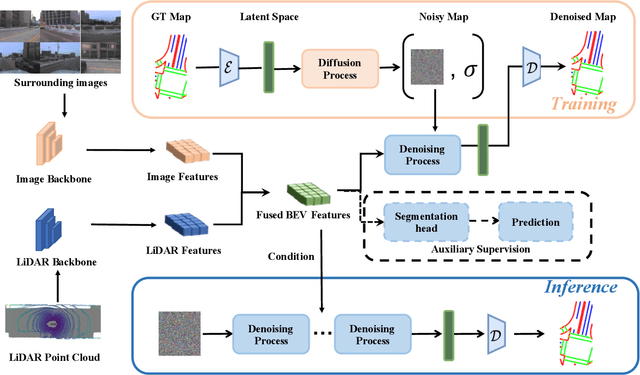
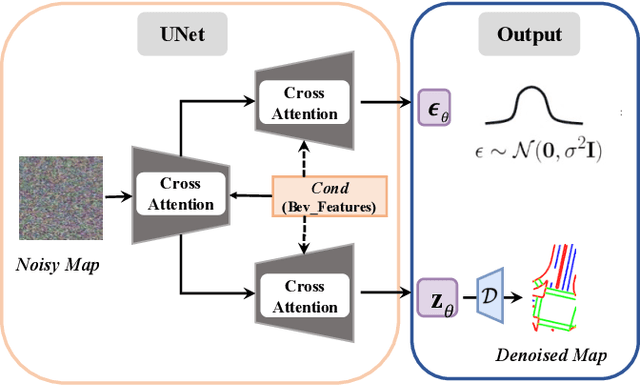

Constructing high-definition (HD) maps is a crucial requirement for enabling autonomous driving. In recent years, several map segmentation algorithms have been developed to address this need, leveraging advancements in Bird's-Eye View (BEV) perception. However, existing models still encounter challenges in producing realistic and consistent semantic map layouts. One prominent issue is the limited utilization of structured priors inherent in map segmentation masks. In light of this, we propose DiffMap, a novel approach specifically designed to model the structured priors of map segmentation masks using latent diffusion model. By incorporating this technique, the performance of existing semantic segmentation methods can be significantly enhanced and certain structural errors present in the segmentation outputs can be effectively rectified. Notably, the proposed module can be seamlessly integrated into any map segmentation model, thereby augmenting its capability to accurately delineate semantic information. Furthermore, through extensive visualization analysis, our model demonstrates superior proficiency in generating results that more accurately reflect real-world map layouts, further validating its efficacy in improving the quality of the generated maps.
A Survey on Monocular Re-Localization: From the Perspective of Scene Map Representation
Nov 27, 2023



Monocular Re-Localization (MRL) is a critical component in numerous autonomous applications, which estimates 6 degree-of-freedom poses with regards to the scene map based on a single monocular image. In recent decades, significant progress has been made in the development of MRL techniques. Numerous landmark algorithms have accomplished extraordinary success in terms of localization accuracy and robustness against visual interference. In MRL research, scene maps are represented in various forms, and they determine how MRL methods work and even how MRL methods perform. However, to the best of our knowledge, existing surveys do not provide systematic reviews of MRL from the respective of map. This survey fills the gap by comprehensively reviewing MRL methods employing monocular cameras as main sensors, promoting further research. 1) We commence by delving into the problem definition of MRL and exploring current challenges, while also comparing ours with with previous published surveys. 2) MRL methods are then categorized into five classes according to the representation forms of utilized map, i.e., geo-tagged frames, visual landmarks, point clouds, and vectorized semantic map, and we review the milestone MRL works of each category. 3) To quantitatively and fairly compare MRL methods with various map, we also review some public datasets and provide the performances of some typical MRL methods. The strengths and weakness of different types of MRL methods are analyzed. 4) We finally introduce some topics of interest in this field and give personal opinions. This survey can serve as a valuable referenced materials for newcomers and researchers interested in MRL, and a continuously updated summary of this survey, including reviewed papers and datasets, is publicly available to the community at: https://github.com/jinyummiao/map-in-mono-reloc.