 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Deep Mixture-of-Koopmans Vehicle Dynamics Model with Dual-branch Encoder for Distributed Electric-drive Trucks
Mar 18, 2026Advanced autonomous driving systems require accurate vehicle dynamics modeling. However, identifying a precise dynamics model remains challenging due to strong nonlinearities and the coupled longitudinal and lateral dynamic characteristics. Previous research has employed physics-based analytical models or neural networks to construct vehicle dynamics representations. Nevertheless, these approaches often struggle to simultaneously achieve satisfactory performance in terms of system identification efficiency, modeling accuracy, and compatibility with linear control strategies. In this paper, we propose a fully data-driven dynamics modeling method tailored for complex distributed electric-drive trucks (DETs), leveraging Koopman operator theory to represent highly nonlinear dynamics in a lifted linear embedding space. To achieve high-precision modeling, we first propose a novel dual-branch encoder which encodes dynamic states and provides a powerful basis for the proposed Koopman-based methods entitled KODE. A physics-informed supervision mechanism, grounded in the geometric consistency of temporal vehicle motion, is incorporated into the training process to facilitate effective learning of both the encoder and the Koopman operator. Furthermore, to accommodate the diverse driving patterns of DETs, we extend the vanilla Koopman operator to a mixture-of-Koopman operator framework, enhancing modeling capability. Simulations conducted in a high-fidelity TruckSim environment and real-world experiments demonstrate that the proposed approach achieves state-of-the-art performance in long-term dynamics state estimation.
DTCCL: Disengagement-Triggered Contrastive Continual Learning for Autonomous Bus Planners
Dec 22, 2025Autonomous buses run on fixed routes but must operate in open, dynamic urban environments. Disengagement events on these routes are often geographically concentrated and typically arise from planner failures in highly interactive regions. Such policy-level failures are difficult to correct using conventional imitation learning, which easily overfits to sparse disengagement data. To address this issue, this paper presents a Disengagement-Triggered Contrastive Continual Learning (DTCCL) framework that enables autonomous buses to improve planning policies through real-world operation. Each disengagement triggers cloud-based data augmentation that generates positive and negative samples by perturbing surrounding agents while preserving route context. Contrastive learning refines policy representations to better distinguish safe and unsafe behaviors, and continual updates are applied in a cloud-edge loop without human supervision. Experiments on urban bus routes demonstrate that DTCCL improves overall planning performance by 48.6 percent compared with direct retraining, validating its effectiveness for scalable, closed-loop policy improvement in autonomous public transport.
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
LEGO-Motion: Learning-Enhanced Grids with Occupancy Instance Modeling for Class-Agnostic Motion Prediction
Mar 10, 2025



Accurate and reliable spatial and motion information plays a pivotal role in autonomous driving systems. However, object-level perception models struggle with handling open scenario categories and lack precise intrinsic geometry. On the other hand, occupancy-based class-agnostic methods excel in representing scenes but fail to ensure physics consistency and ignore the importance of interactions between traffic participants, hindering the model's ability to learn accurate and reliable motion. In this paper, we introduce a novel occupancy-instance modeling framework for class-agnostic motion prediction tasks, named LEGO-Motion, which incorporates instance features into Bird's Eye View (BEV) space. Our model comprises (1) a BEV encoder, (2) an Interaction-Augmented Instance Encoder, and (3) an Instance-Enhanced BEV Encoder, improving both interaction relationships and physics consistency within the model, thereby ensuring a more accurate and robust understanding of the environment. Extensive experiments on the nuScenes dataset demonstrate that our method achieves state-of-the-art performance, outperforming existing approaches. Furthermore, the effectiveness of our framework is validated on the advanced FMCW LiDAR benchmark, showcasing its practical applicability and generalization capabilities. The code will be made publicly available to facilitate further research.
Residual Learning towards High-fidelity Vehicle Dynamics Modeling with Transformer
Feb 17, 2025The vehicle dynamics model serves as a vital component of autonomous driving systems, as it describes the temporal changes in vehicle state. In a long period, researchers have made significant endeavors to accurately model vehicle dynamics. Traditional physics-based methods employ mathematical formulae to model vehicle dynamics, but they are unable to adequately describe complex vehicle systems due to the simplifications they entail. Recent advancements in deep learning-based methods have addressed this limitation by directly regressing vehicle dynamics. However, the performance and generalization capabilities still require further enhancement. In this letter, we address these problems by proposing a vehicle dynamics correction system that leverages deep neural networks to correct the state residuals of a physical model instead of directly estimating the states. This system greatly reduces the difficulty of network learning and thus improves the estimation accuracy of vehicle dynamics. Furthermore, we have developed a novel Transformer-based dynamics residual correction network, DyTR. This network implicitly represents state residuals as high-dimensional queries, and iteratively updates the estimated residuals by interacting with dynamics state features. The experiments in simulations demonstrate the proposed system works much better than physics model, and our proposed DyTR model achieves the best performances on dynamics state residual correction task, reducing the state prediction errors of a simple 3 DoF vehicle model by an average of 92.3% and 59.9% in two dataset, respectively.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

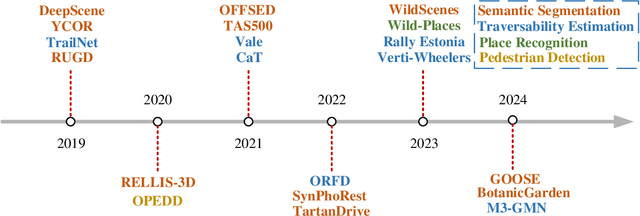

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
A Survey on Monocular Re-Localization: From the Perspective of Scene Map Representation
Nov 27, 2023



Monocular Re-Localization (MRL) is a critical component in numerous autonomous applications, which estimates 6 degree-of-freedom poses with regards to the scene map based on a single monocular image. In recent decades, significant progress has been made in the development of MRL techniques. Numerous landmark algorithms have accomplished extraordinary success in terms of localization accuracy and robustness against visual interference. In MRL research, scene maps are represented in various forms, and they determine how MRL methods work and even how MRL methods perform. However, to the best of our knowledge, existing surveys do not provide systematic reviews of MRL from the respective of map. This survey fills the gap by comprehensively reviewing MRL methods employing monocular cameras as main sensors, promoting further research. 1) We commence by delving into the problem definition of MRL and exploring current challenges, while also comparing ours with with previous published surveys. 2) MRL methods are then categorized into five classes according to the representation forms of utilized map, i.e., geo-tagged frames, visual landmarks, point clouds, and vectorized semantic map, and we review the milestone MRL works of each category. 3) To quantitatively and fairly compare MRL methods with various map, we also review some public datasets and provide the performances of some typical MRL methods. The strengths and weakness of different types of MRL methods are analyzed. 4) We finally introduce some topics of interest in this field and give personal opinions. This survey can serve as a valuable referenced materials for newcomers and researchers interested in MRL, and a continuously updated summary of this survey, including reviewed papers and datasets, is publicly available to the community at: https://github.com/jinyummiao/map-in-mono-reloc.
Poses as Queries: Image-to-LiDAR Map Localization with Transformers
May 07, 2023



High-precision vehicle localization with commercial setups is a crucial technique for high-level autonomous driving tasks. Localization with a monocular camera in LiDAR map is a newly emerged approach that achieves promising balance between cost and accuracy, but estimating pose by finding correspondences between such cross-modal sensor data is challenging, thereby damaging the localization accuracy. In this paper, we address the problem by proposing a novel Transformer-based neural network to register 2D images into 3D LiDAR map in an end-to-end manner. Poses are implicitly represented as high-dimensional feature vectors called pose queries and can be iteratively updated by interacting with the retrieved relevant information from cross-model features using attention mechanism in a proposed POse Estimator Transformer (POET) module. Moreover, we apply a multiple hypotheses aggregation method that estimates the final poses by performing parallel optimization on multiple randomly initialized pose queries to reduce the network uncertainty. Comprehensive analysis and experimental results on public benchmark conclude that the proposed image-to-LiDAR map localization network could achieve state-of-the-art performances in challenging cross-modal localization tasks.
Real-time Local Feature with Global Visual Information Enhancement
Nov 20, 2022



Local feature provides compact and invariant image representation for various visual tasks. Current deep learning-based local feature algorithms always utilize convolution neural network (CNN) architecture with limited receptive field. Besides, even with high-performance GPU devices, the computational efficiency of local features cannot be satisfactory. In this paper, we tackle such problems by proposing a CNN-based local feature algorithm. The proposed method introduces a global enhancement module to fuse global visual clues in a light-weight network, and then optimizes the network by novel deep reinforcement learning scheme from the perspective of local feature matching task. Experiments on the public benchmarks demonstrate that the proposal can achieve considerable robustness against visual interference and meanwhile run in real time.