 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSI-DM: Singularity Skipping Inversion of Diffusion Models
Feb 02, 2026Inverting real images into the noise space is essential for editing tasks using diffusion models, yet existing methods produce non-Gaussian noise with poor editability due to the inaccuracy in early noising steps. We identify the root cause: a mathematical singularity that renders inversion fundamentally ill-posed. We propose Singularity Skipping Inversion of Diffusion Models (SSI-DM), which bypasses this singular region by adding small noise before standard inversion. This simple approach produces inverted noise with natural Gaussian properties while maintaining reconstruction fidelity. As a plug-and-play technique compatible with general diffusion models, our method achieves superior performance on public image datasets for reconstruction and interpolation tasks, providing a principled and efficient solution to diffusion model inversion.
OT-Drive: Out-of-Distribution Off-Road Traversable Area Segmentation via Optimal Transport
Jan 15, 2026Reliable traversable area segmentation in unstructured environments is critical for planning and decision-making in autonomous driving. However, existing data-driven approaches often suffer from degraded segmentation performance in out-of-distribution (OOD) scenarios, consequently impairing downstream driving tasks. To address this issue, we propose OT-Drive, an Optimal Transport--driven multi-modal fusion framework. The proposed method formulates RGB and surface normal fusion as a distribution transport problem. Specifically, we design a novel Scene Anchor Generator (SAG) to decompose scene information into the joint distribution of weather, time-of-day, and road type, thereby constructing semantic anchors that can generalize to unseen scenarios. Subsequently, we design an innovative Optimal Transport-based multi-modal fusion module (OT Fusion) to transport RGB and surface normal features onto the manifold defined by the semantic anchors, enabling robust traversable area segmentation under OOD scenarios. Experimental results demonstrate that our method achieves 95.16% mIoU on ORFD OOD scenarios, outperforming prior methods by 6.35%, and 89.79% mIoU on cross-dataset transfer tasks, surpassing baselines by 13.99%.These results indicate that the proposed model can attain strong OOD generalization with only limited training data, substantially enhancing its practicality and efficiency for real-world deployment.
GenDet: Painting Colored Bounding Boxes on Images via Diffusion Model for Object Detection
Jan 12, 2026This paper presents GenDet, a novel framework that redefines object detection as an image generation task. In contrast to traditional approaches, GenDet adopts a pioneering approach by leveraging generative modeling: it conditions on the input image and directly generates bounding boxes with semantic annotations in the original image space. GenDet establishes a conditional generation architecture built upon the large-scale pre-trained Stable Diffusion model, formulating the detection task as semantic constraints within the latent space. It enables precise control over bounding box positions and category attributes, while preserving the flexibility of the generative model. This novel methodology effectively bridges the gap between generative models and discriminative tasks, providing a fresh perspective for constructing unified visual understanding systems. Systematic experiments demonstrate that GenDet achieves competitive accuracy compared to discriminative detectors, while retaining the flexibility characteristic of generative methods.
A Vision-Language-Action Model with Visual Prompt for OFF-Road Autonomous Driving
Jan 07, 2026Efficient trajectory planning in off-road terrains presents a formidable challenge for autonomous vehicles, often necessitating complex multi-step pipelines. However, traditional approaches exhibit limited adaptability in dynamic environments. To address these limitations, this paper proposes OFF-EMMA, a novel end-to-end multimodal framework designed to overcome the deficiencies of insufficient spatial perception and unstable reasoning in visual-language-action (VLA) models for off-road autonomous driving scenarios. The framework explicitly annotates input images through the design of a visual prompt block and introduces a chain-of-thought with self-consistency (COT-SC) reasoning strategy to enhance the accuracy and robustness of trajectory planning. The visual prompt block utilizes semantic segmentation masks as visual prompts, enhancing the spatial understanding ability of pre-trained visual-language models for complex terrains. The COT- SC strategy effectively mitigates the error impact of outliers on planning performance through a multi-path reasoning mechanism. Experimental results on the RELLIS-3D off-road dataset demonstrate that OFF-EMMA significantly outperforms existing methods, reducing the average L2 error of the Qwen backbone model by 13.3% and decreasing the failure rate from 16.52% to 6.56%.
UNIV: Unified Foundation Model for Infrared and Visible Modalities
Sep 19, 2025The demand for joint RGB-visible and infrared perception is growing rapidly, particularly to achieve robust performance under diverse weather conditions. Although pre-trained models for RGB-visible and infrared data excel in their respective domains, they often underperform in multimodal scenarios, such as autonomous vehicles equipped with both sensors. To address this challenge, we propose a biologically inspired UNified foundation model for Infrared and Visible modalities (UNIV), featuring two key innovations. First, we introduce Patch-wise Cross-modality Contrastive Learning (PCCL), an attention-guided distillation framework that mimics retinal horizontal cells' lateral inhibition, which enables effective cross-modal feature alignment while remaining compatible with any transformer-based architecture. Second, our dual-knowledge preservation mechanism emulates the retina's bipolar cell signal routing - combining LoRA adapters (2% added parameters) with synchronous distillation to prevent catastrophic forgetting, thereby replicating the retina's photopic (cone-driven) and scotopic (rod-driven) functionality. To support cross-modal learning, we introduce the MVIP dataset, the most comprehensive visible-infrared benchmark to date. It contains 98,992 precisely aligned image pairs spanning diverse scenarios. Extensive experiments demonstrate UNIV's superior performance on infrared tasks (+1.7 mIoU in semantic segmentation and +0.7 mAP in object detection) while maintaining 99%+ of the baseline performance on visible RGB tasks. Our code is available at https://github.com/fangyuanmao/UNIV.
An Efficient Real-Time Planning Method for Swarm Robotics Based on an Optimal Virtual Tube
May 02, 2025Swarm robotics navigating through unknown obstacle environments is an emerging research area that faces challenges. Performing tasks in such environments requires swarms to achieve autonomous localization, perception, decision-making, control, and planning. The limited computational resources of onboard platforms present significant challenges for planning and control. Reactive planners offer low computational demands and high re-planning frequencies but lack predictive capabilities, often resulting in local minima. Long-horizon planners, on the other hand, can perform multi-step predictions to reduce deadlocks but cost much computation, leading to lower re-planning frequencies. This paper proposes a real-time optimal virtual tube planning method for swarm robotics in unknown environments, which generates approximate solutions for optimal trajectories through affine functions. As a result, the computational complexity of approximate solutions is $O(n_t)$, where $n_t$ is the number of parameters in the trajectory, thereby significantly reducing the overall computational burden. By integrating reactive methods, the proposed method enables low-computation, safe swarm motion in unknown environments. The effectiveness of the proposed method is validated through several simulations and experiments.
Semantic Scene Completion Based 3D Traversability Estimation for Off-Road Terrains
Dec 11, 2024Off-road environments present significant challenges for autonomous ground vehicles due to the absence of structured roads and the presence of complex obstacles, such as uneven terrain, vegetation, and occlusions. Traditional perception algorithms, designed primarily for structured environments, often fail under these conditions, leading to inaccurate traversability estimations. In this paper, ORDformer, a novel multimodal method that combines LiDAR point clouds with monocular images, is proposed to generate dense traversable occupancy predictions from a forward-facing perspective. By integrating multimodal data, environmental feature extraction is enhanced, which is crucial for accurate occupancy estimation in complex terrains. Furthermore, RELLIS-OCC, a dataset with 3D traversable occupancy annotations, is introduced, incorporating geometric features such as step height, slope, and unevenness. Through a comprehensive analysis of vehicle obstacle-crossing conditions and the incorporation of vehicle body structure constraints, four traversability cost labels are generated: lethal, medium-cost, low-cost, and free. Experimental results demonstrate that ORDformer outperforms existing approaches in 3D traversable area recognition, particularly in off-road environments with irregular geometries and partial occlusions. Specifically, ORDformer achieves over a 20\% improvement in scene completion IoU compared to other models. The proposed framework is scalable and adaptable to various vehicle platforms, allowing for adjustments to occupancy grid parameters and the integration of advanced dynamic models for traversability cost estimation.
WildOcc: A Benchmark for Off-Road 3D Semantic Occupancy Prediction
Oct 21, 20243D semantic occupancy prediction is an essential part of autonomous driving, focusing on capturing the geometric details of scenes. Off-road environments are rich in geometric information, therefore it is suitable for 3D semantic occupancy prediction tasks to reconstruct such scenes. However, most of researches concentrate on on-road environments, and few methods are designed for off-road 3D semantic occupancy prediction due to the lack of relevant datasets and benchmarks. In response to this gap, we introduce WildOcc, to our knowledge, the first benchmark to provide dense occupancy annotations for off-road 3D semantic occupancy prediction tasks. A ground truth generation pipeline is proposed in this paper, which employs a coarse-to-fine reconstruction to achieve a more realistic result. Moreover, we introduce a multi-modal 3D semantic occupancy prediction framework, which fuses spatio-temporal information from multi-frame images and point clouds at voxel level. In addition, a cross-modality distillation function is introduced, which transfers geometric knowledge from point clouds to image features.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

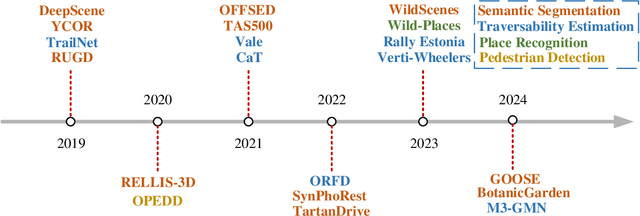

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
May 07, 2024Vision-centric autonomous driving has recently raised wide attention due to its lower cost. Pre-training is essential for extracting a universal representation. However, current vision-centric pre-training typically relies on either 2D or 3D pre-text tasks, overlooking the temporal characteristics of autonomous driving as a 4D scene understanding task. In this paper, we address this challenge by introducing a world model-based autonomous driving 4D representation learning framework, dubbed \emph{DriveWorld}, which is capable of pre-training from multi-camera driving videos in a spatio-temporal fashion. Specifically, we propose a Memory State-Space Model for spatio-temporal modelling, which consists of a Dynamic Memory Bank module for learning temporal-aware latent dynamics to predict future changes and a Static Scene Propagation module for learning spatial-aware latent statics to offer comprehensive scene contexts. We additionally introduce a Task Prompt to decouple task-aware features for various downstream tasks. The experiments demonstrate that DriveWorld delivers promising results on various autonomous driving tasks. When pre-trained with the OpenScene dataset, DriveWorld achieves a 7.5% increase in mAP for 3D object detection, a 3.0% increase in IoU for online mapping, a 5.0% increase in AMOTA for multi-object tracking, a 0.1m decrease in minADE for motion forecasting, a 3.0% increase in IoU for occupancy prediction, and a 0.34m reduction in average L2 error for planning.