 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround4D: Spatially-Grounded Feedforward 4D Reconstruction for Unstructured Off-Road Scenes
May 06, 2026Feedforward Gaussian Splatting has recently emerged as an efficient paradigm for 4D reconstruction in autonomous driving. However, in unstructured off-road scenes, its performance degrades due to high-frequency geometry, ego-motion jitter, and increased non-rigid dynamics. These factors introduce conflicting Gaussian observations across timestamps, leading to either over-smoothed renderings or structural artifacts. To address this issue, we propose Ground4D, a spatially-grounded 4D feedforward framework for pose-free off-road reconstruction. The key idea is to resolve temporal conflicts through spatially localized conditioning. Specifically, we introduce voxel-grounded temporal Gaussian aggregation, which partitions the canonical Gaussian space into spatial voxels and performs query-conditioned temporal attention within each voxel. Intra-voxel softmax normalization ensures that temporal selectivity and spatial occupancy become mutually reinforcing rather than conflicting. We furthermore introduce surface normal cues as auxiliary geometric guidance to regularize the geometry of Gaussian primitives. Extensive experiments on ORAD-3D and RELLIS-3D demonstrate that Ground4D consistently outperforms existing feedforward methods in reconstruction quality and generalizes zero-shot to unseen off-road domains. Project page and code:https://github.com/wsnbws/Ground4D.
Interpreting Emergent Extreme Events in Multi-Agent Systems
Jan 28, 2026Large language model-powered multi-agent systems have emerged as powerful tools for simulating complex human-like systems. The interactions within these systems often lead to extreme events whose origins remain obscured by the black box of emergence. Interpreting these events is critical for system safety. This paper proposes the first framework for explaining emergent extreme events in multi-agent systems, aiming to answer three fundamental questions: When does the event originate? Who drives it? And what behaviors contribute to it? Specifically, we adapt the Shapley value to faithfully attribute the occurrence of extreme events to each action taken by agents at different time steps, i.e., assigning an attribution score to the action to measure its influence on the event. We then aggregate the attribution scores along the dimensions of time, agent, and behavior to quantify the risk contribution of each dimension. Finally, we design a set of metrics based on these contribution scores to characterize the features of extreme events. Experiments across diverse multi-agent system scenarios (economic, financial, and social) demonstrate the effectiveness of our framework and provide general insights into the emergence of extreme phenomena.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
The Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution
Jan 21, 2026Large Language Model (LLM)-based agents are widely used in real-world applications such as customer service, web navigation, and software engineering. As these systems become more autonomous and are deployed at scale, understanding why an agent takes a particular action becomes increasingly important for accountability and governance. However, existing research predominantly focuses on \textit{failure attribution} to localize explicit errors in unsuccessful trajectories, which is insufficient for explaining the reasoning behind agent behaviors. To bridge this gap, we propose a novel framework for \textbf{general agentic attribution}, designed to identify the internal factors driving agent actions regardless of the task outcome. Our framework operates hierarchically to manage the complexity of agent interactions. Specifically, at the \textit{component level}, we employ temporal likelihood dynamics to identify critical interaction steps; then at the \textit{sentence level}, we refine this localization using perturbation-based analysis to isolate the specific textual evidence. We validate our framework across a diverse suite of agentic scenarios, including standard tool use and subtle reliability risks like memory-induced bias. Experimental results demonstrate that the proposed framework reliably pinpoints pivotal historical events and sentences behind the agent behavior, offering a critical step toward safer and more accountable agentic systems.
Beyond Endpoints: Path-Centric Reasoning for Vectorized Off-Road Network Extraction
Dec 12, 2025Deep learning has advanced vectorized road extraction in urban settings, yet off-road environments remain underexplored and challenging. A significant domain gap causes advanced models to fail in wild terrains due to two key issues: lack of large-scale vectorized datasets and structural weakness in prevailing methods. Models such as SAM-Road employ a node-centric paradigm that reasons at sparse endpoints, making them fragile to occlusions and ambiguous junctions in off-road scenes, leading to topological errors. This work addresses these limitations in two complementary ways. First, we release WildRoad, a global off-road road network dataset constructed efficiently with a dedicated interactive annotation tool tailored for road-network labeling. Second, we introduce MaGRoad (Mask-aware Geodesic Road network extractor), a path-centric framework that aggregates multi-scale visual evidence along candidate paths to infer connectivity robustly. Extensive experiments show that MaGRoad achieves state-of-the-art performance on our challenging WildRoad benchmark while generalizing well to urban datasets. A streamlined pipeline also yields roughly 2.5x faster inference, improving practical applicability. Together, the dataset and path-centric paradigm provide a stronger foundation for mapping roads in the wild. We release both the dataset and code at https://github.com/xiaofei-guan/MaGRoad.
UNIV: Unified Foundation Model for Infrared and Visible Modalities
Sep 19, 2025The demand for joint RGB-visible and infrared perception is growing rapidly, particularly to achieve robust performance under diverse weather conditions. Although pre-trained models for RGB-visible and infrared data excel in their respective domains, they often underperform in multimodal scenarios, such as autonomous vehicles equipped with both sensors. To address this challenge, we propose a biologically inspired UNified foundation model for Infrared and Visible modalities (UNIV), featuring two key innovations. First, we introduce Patch-wise Cross-modality Contrastive Learning (PCCL), an attention-guided distillation framework that mimics retinal horizontal cells' lateral inhibition, which enables effective cross-modal feature alignment while remaining compatible with any transformer-based architecture. Second, our dual-knowledge preservation mechanism emulates the retina's bipolar cell signal routing - combining LoRA adapters (2% added parameters) with synchronous distillation to prevent catastrophic forgetting, thereby replicating the retina's photopic (cone-driven) and scotopic (rod-driven) functionality. To support cross-modal learning, we introduce the MVIP dataset, the most comprehensive visible-infrared benchmark to date. It contains 98,992 precisely aligned image pairs spanning diverse scenarios. Extensive experiments demonstrate UNIV's superior performance on infrared tasks (+1.7 mIoU in semantic segmentation and +0.7 mAP in object detection) while maintaining 99%+ of the baseline performance on visible RGB tasks. Our code is available at https://github.com/fangyuanmao/UNIV.
ROD: RGB-Only Fast and Efficient Off-road Freespace Detection
Aug 12, 2025



Off-road freespace detection is more challenging than on-road scenarios because of the blurred boundaries of traversable areas. Previous state-of-the-art (SOTA) methods employ multi-modal fusion of RGB images and LiDAR data. However, due to the significant increase in inference time when calculating surface normal maps from LiDAR data, multi-modal methods are not suitable for real-time applications, particularly in real-world scenarios where higher FPS is required compared to slow navigation. This paper presents a novel RGB-only approach for off-road freespace detection, named ROD, eliminating the reliance on LiDAR data and its computational demands. Specifically, we utilize a pre-trained Vision Transformer (ViT) to extract rich features from RGB images. Additionally, we design a lightweight yet efficient decoder, which together improve both precision and inference speed. ROD establishes a new SOTA on ORFD and RELLIS-3D datasets, as well as an inference speed of 50 FPS, significantly outperforming prior models.
From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
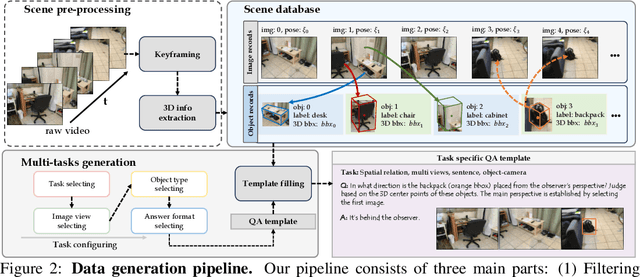
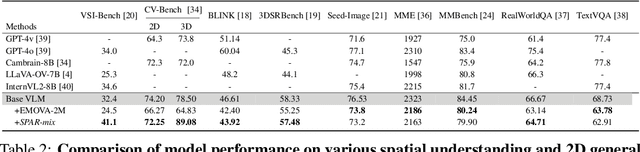

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
MASTER: Multimodal Segmentation with Text Prompts
Mar 06, 2025



RGB-Thermal fusion is a potential solution for various weather and light conditions in challenging scenarios. However, plenty of studies focus on designing complex modules to fuse different modalities. With the widespread application of large language models (LLMs), valuable information can be more effectively extracted from natural language. Therefore, we aim to leverage the advantages of large language models to design a structurally simple and highly adaptable multimodal fusion model architecture. We proposed MultimodAl Segmentation with TExt PRompts (MASTER) architecture, which integrates LLM into the fusion of RGB-Thermal multimodal data and allows complex query text to participate in the fusion process. Our model utilizes a dual-path structure to extract information from different modalities of images. Additionally, we employ LLM as the core module for multimodal fusion, enabling the model to generate learnable codebook tokens from RGB, thermal images, and textual information. A lightweight image decoder is used to obtain semantic segmentation results. The proposed MASTER performs exceptionally well in benchmark tests across various automated driving scenarios, yielding promising results.
WildOcc: A Benchmark for Off-Road 3D Semantic Occupancy Prediction
Oct 21, 20243D semantic occupancy prediction is an essential part of autonomous driving, focusing on capturing the geometric details of scenes. Off-road environments are rich in geometric information, therefore it is suitable for 3D semantic occupancy prediction tasks to reconstruct such scenes. However, most of researches concentrate on on-road environments, and few methods are designed for off-road 3D semantic occupancy prediction due to the lack of relevant datasets and benchmarks. In response to this gap, we introduce WildOcc, to our knowledge, the first benchmark to provide dense occupancy annotations for off-road 3D semantic occupancy prediction tasks. A ground truth generation pipeline is proposed in this paper, which employs a coarse-to-fine reconstruction to achieve a more realistic result. Moreover, we introduce a multi-modal 3D semantic occupancy prediction framework, which fuses spatio-temporal information from multi-frame images and point clouds at voxel level. In addition, a cross-modality distillation function is introduced, which transfers geometric knowledge from point clouds to image features.