 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Revealing Asymmetric Development of Abilities in MLLM Pre-training
Feb 13, 2026Pre-trained Multi-modal Large Language Models (MLLMs) provide a knowledge-rich foundation for post-training by leveraging their inherent perception and reasoning capabilities to solve complex tasks. However, the lack of an efficient evaluation framework impedes the diagnosis of their performance bottlenecks. Current evaluation primarily relies on testing after supervised fine-tuning, which introduces laborious additional training and autoregressive decoding costs. Meanwhile, common pre-training metrics cannot quantify a model's perception and reasoning abilities in a disentangled manner. Furthermore, existing evaluation benchmarks are typically limited in scale or misaligned with pre-training objectives. Thus, we propose RADAR, an efficient ability-centric evaluation framework for Revealing Asymmetric Development of Abilities in MLLM pRe-training. RADAR involves two key components: (1) Soft Discrimination Score, a novel metric for robustly tracking ability development without fine-tuning, based on quantifying nuanced gradations of the model preference for the correct answer over distractors; and (2) Multi-Modal Mixture Benchmark, a new 15K+ sample benchmark for comprehensively evaluating pre-trained MLLMs' perception and reasoning abilities in a 0-shot manner, where we unify authoritative benchmark datasets and carefully collect new datasets, extending the evaluation scope and addressing the critical gaps in current benchmarks. With RADAR, we comprehensively reveal the asymmetric development of perceptual and reasoning capabilities in pretrained MLLMs across diverse factors, including data volume, model size, and pretraining strategy. Our RADAR underscores the need for a decomposed perspective on pre-training ability bottlenecks, informing targeted interventions to advance MLLMs efficiently. Our code is publicly available at https://github.com/Nieysh/RADAR.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
GraphCoT-VLA: A 3D Spatial-Aware Reasoning Vision-Language-Action Model for Robotic Manipulation with Ambiguous Instructions
Aug 11, 2025Vision-language-action models have emerged as a crucial paradigm in robotic manipulation. However, existing VLA models exhibit notable limitations in handling ambiguous language instructions and unknown environmental states. Furthermore, their perception is largely constrained to static two-dimensional observations, lacking the capability to model three-dimensional interactions between the robot and its environment. To address these challenges, this paper proposes GraphCoT-VLA, an efficient end-to-end model. To enhance the model's ability to interpret ambiguous instructions and improve task planning, we design a structured Chain-of-Thought reasoning module that integrates high-level task understanding and planning, failed task feedback, and low-level imaginative reasoning about future object positions and robot actions. Additionally, we construct a real-time updatable 3D Pose-Object graph, which captures the spatial configuration of robot joints and the topological relationships between objects in 3D space, enabling the model to better understand and manipulate their interactions. We further integrates a dropout hybrid reasoning strategy to achieve efficient control outputs. Experimental results across multiple real-world robotic tasks demonstrate that GraphCoT-VLA significantly outperforms existing methods in terms of task success rate and response speed, exhibiting strong generalization and robustness in open environments and under uncertain instructions.
From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
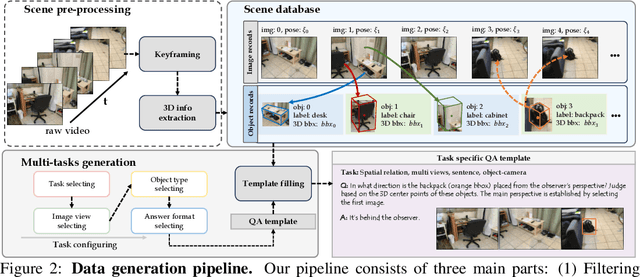
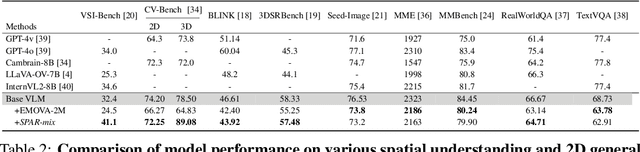

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025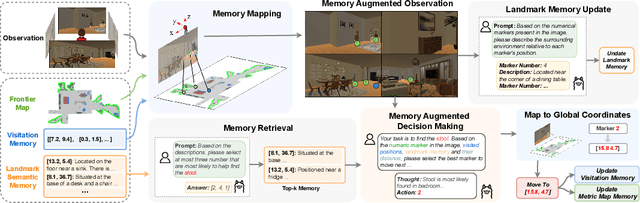
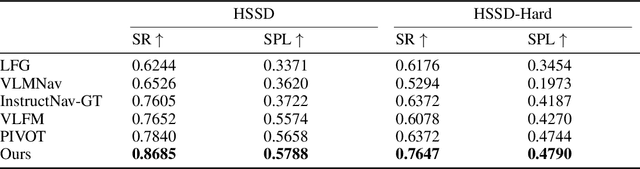

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
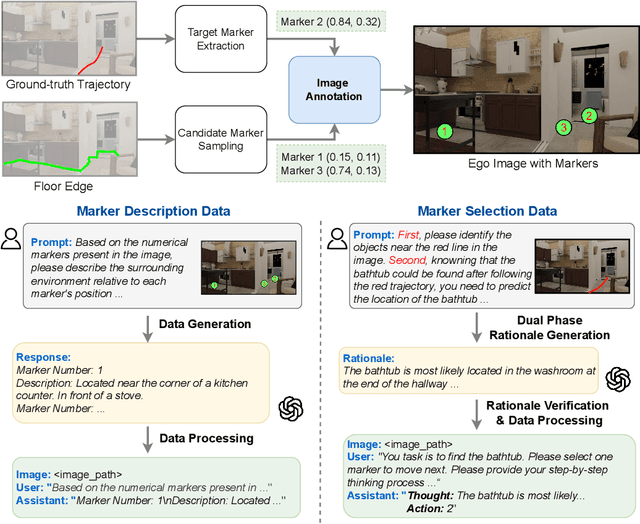
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning
Jan 17, 2025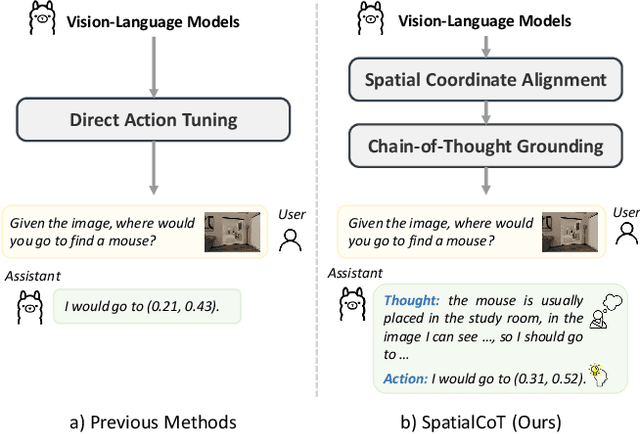
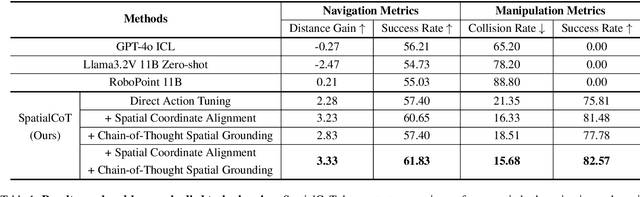
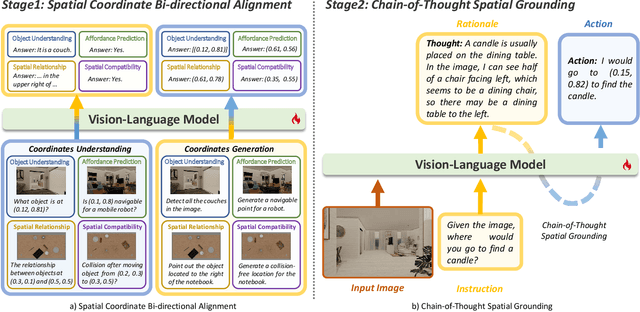
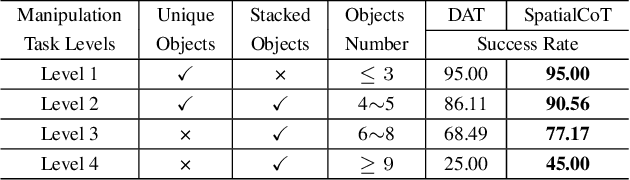
Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs). To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
RoboKeyGen: Robot Pose and Joint Angles Estimation via Diffusion-based 3D Keypoint Generation
Mar 27, 2024



Estimating robot pose and joint angles is significant in advanced robotics, enabling applications like robot collaboration and online hand-eye calibration.However, the introduction of unknown joint angles makes prediction more complex than simple robot pose estimation, due to its higher dimensionality.Previous methods either regress 3D keypoints directly or utilise a render&compare strategy. These approaches often falter in terms of performance or efficiency and grapple with the cross-camera gap problem.This paper presents a novel framework that bifurcates the high-dimensional prediction task into two manageable subtasks: 2D keypoints detection and lifting 2D keypoints to 3D. This separation promises enhanced performance without sacrificing the efficiency innate to keypoint-based techniques.A vital component of our method is the lifting of 2D keypoints to 3D keypoints. Common deterministic regression methods may falter when faced with uncertainties from 2D detection errors or self-occlusions.Leveraging the robust modeling potential of diffusion models, we reframe this issue as a conditional 3D keypoints generation task. To bolster cross-camera adaptability, we introduce theNormalised Camera Coordinate Space (NCCS), ensuring alignment of estimated 2D keypoints across varying camera intrinsics.Experimental results demonstrate that the proposed method outperforms the state-of-the-art render\&compare method and achieves higher inference speed.Furthermore, the tests accentuate our method's robust cross-camera generalisation capabilities.We intend to release both the dataset and code in https://nimolty.github.io/Robokeygen/