 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataLadder: A Simulation-Enabled Interconversion Toolchain for the Embodied Data Pyramid
Jun 15, 2026Generalist robot policies require trustworthy evaluation and robot-usable training data, but both are difficult to scale with physical robots alone. Real-robot trials and demonstrations remain the most faithful source of deployment signals, yet they are slow, costly, and hard to reproduce. We present DataLadder, a simulation-enabled interconversion toolchain for human-robot aligned model evaluation and data generation, denoted as Robot $\rightleftharpoons$ Simulation $\rightleftharpoons$ Human. On the one hand, the Robot $\rightarrow$ Simulation $\rightarrow$ Human pathway supports human-robot aligned model evaluation by reconstructing real-robot tabletop organization tasks as calibrated digital twins for scalable evaluation, while using human embodied feedback to inspect and refine the naturalness of simulated motions. On the other hand, the Human $\rightarrow$ Simulation $\rightarrow$ Robot pathway supports human-robot aligned data generation: it lifts ego-centric human demonstrations into simulation, checks them under robot physical constraints, and converts them into robot-centered trajectories, annotations, and visual observations. Together, these pathways use the JoySim simulator as both a scalable evaluation layer and a physical consistency filter for robot data generation. We further package the core reconstruction, simulation, rendering, and realism-augmentation modules as cloud services on JD Cloud, turning the system into reusable infrastructure for robot data generation and model evaluation.
JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
Apr 22, 2026Robotic autonomy in open-world environments is fundamentally limited by insufficient data diversity and poor cross-embodiment generalization. Existing robotic datasets are often limited in scale and task coverage, while relatively large differences across robot embodiments impede effective behavior knowledge transfer. To address these challenges, we propose JoyAI-RA, a vision-language-action (VLA) embodied foundation model tailored for generalizable robotic manipulation. JoyAI-RA presents a multi-source multi-level pretraining framework that integrates web data, large-scale egocentric human manipulation videos, simulation-generated trajectories, and real-robot data. Through training on heterogeneous multi-source data with explicit action-space unification, JoyAI-RA effectively bridges embodiment gaps, particularly between human manipulation and robotic control, thereby enhancing cross-embodiment behavior learning. JoyAI-RA outperforms state-of-the-art methods in both simulation and real-world benchmarks, especially on diverse tasks with generalization demands.
OmniEVA: Embodied Versatile Planner via Task-Adaptive 3D-Grounded and Embodiment-aware Reasoning
Sep 11, 2025Recent advances in multimodal large language models (MLLMs) have opened new opportunities for embodied intelligence, enabling multimodal understanding, reasoning, and interaction, as well as continuous spatial decision-making. Nevertheless, current MLLM-based embodied systems face two critical limitations. First, Geometric Adaptability Gap: models trained solely on 2D inputs or with hard-coded 3D geometry injection suffer from either insufficient spatial information or restricted 2D generalization, leading to poor adaptability across tasks with diverse spatial demands. Second, Embodiment Constraint Gap: prior work often neglects the physical constraints and capacities of real robots, resulting in task plans that are theoretically valid but practically infeasible.To address these gaps, we introduce OmniEVA -- an embodied versatile planner that enables advanced embodied reasoning and task planning through two pivotal innovations: (1) a Task-Adaptive 3D Grounding mechanism, which introduces a gated router to perform explicit selective regulation of 3D fusion based on contextual requirements, enabling context-aware 3D grounding for diverse embodied tasks. (2) an Embodiment-Aware Reasoning framework that jointly incorporates task goals and embodiment constraints into the reasoning loop, resulting in planning decisions that are both goal-directed and executable. Extensive experimental results demonstrate that OmniEVA not only achieves state-of-the-art general embodied reasoning performance, but also exhibits a strong ability across a wide range of downstream scenarios. Evaluations of a suite of proposed embodied benchmarks, including both primitive and composite tasks, confirm its robust and versatile planning capabilities. Project page: https://omnieva.github.io
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning
Jan 17, 2025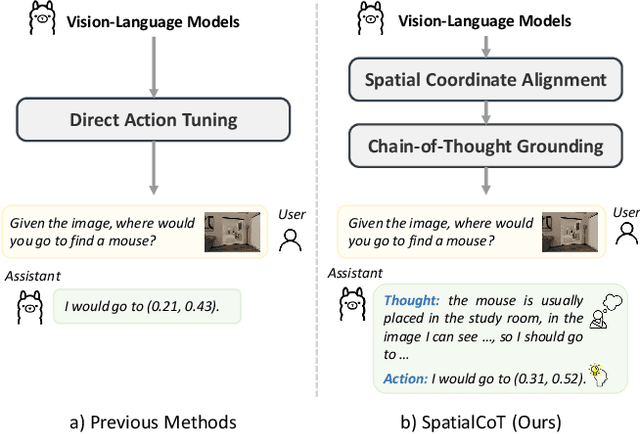
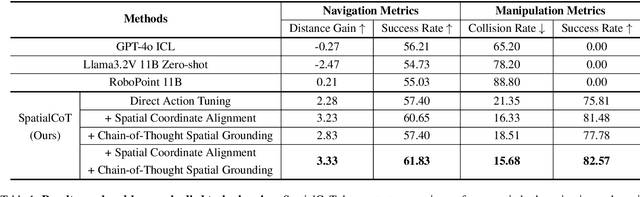
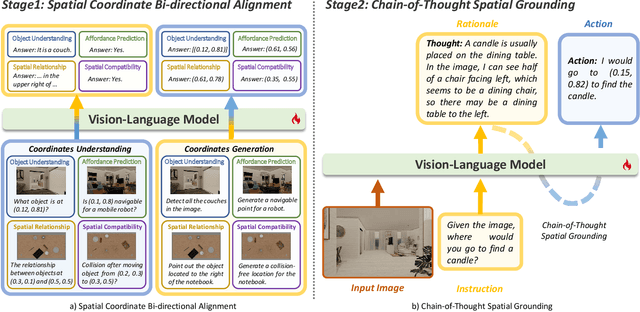
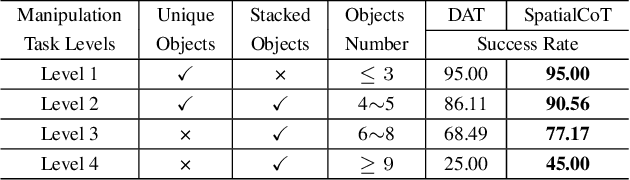
Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs). To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
Actra: Optimized Transformer Architecture for Vision-Language-Action Models in Robot Learning
Aug 02, 2024Vision-language-action models have gained significant attention for their ability to model trajectories in robot learning. However, most existing models rely on Transformer models with vanilla causal attention, which we find suboptimal for processing segmented multi-modal sequences. Additionally, the autoregressive generation approach falls short in generating multi-dimensional actions. In this paper, we introduce Actra, an optimized Transformer architecture featuring trajectory attention and learnable action queries, designed for effective encoding and decoding of segmented vision-language-action trajectories in robot imitation learning. Furthermore, we devise a multi-modal contrastive learning objective to explicitly align different modalities, complementing the primary behavior cloning objective. Through extensive experiments conducted across various environments, Actra exhibits substantial performance improvement when compared to state-of-the-art models in terms of generalizability, dexterity, and precision.
VOLTA: Diverse and Controllable Question-Answer Pair Generation with Variational Mutual Information Maximizing Autoencoder
Jul 03, 2023
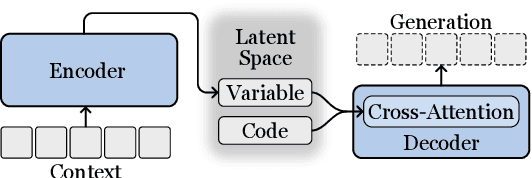

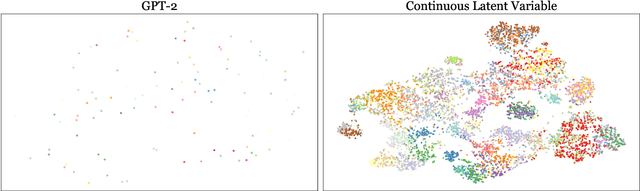
Previous question-answer pair generation methods aimed to produce fluent and meaningful question-answer pairs but tend to have poor diversity. Recent attempts addressing this issue suffer from either low model capacity or overcomplicated architecture. Furthermore, they overlooked the problem where the controllability of their models is highly dependent on the input. In this paper, we propose a model named VOLTA that enhances generative diversity by leveraging the Variational Autoencoder framework with a shared backbone network as its encoder and decoder. In addition, we propose adding InfoGAN-style latent codes to enable input-independent controllability over the generation process. We perform comprehensive experiments and the results show that our approach can significantly improve diversity and controllability over state-of-the-art models.