 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEF-MAP: Subspace-Decomposed Expert Fusion for Robust Multimodal HD Map Prediction
Feb 25, 2026High-definition (HD) maps are essential for autonomous driving, yet multi-modal fusion often suffers from inconsistency between camera and LiDAR modalities, leading to performance degradation under low-light conditions, occlusions, or sparse point clouds. To address this, we propose SEFMAP, a Subspace-Expert Fusion framework for robust multimodal HD map prediction. The key idea is to explicitly disentangle BEV features into four semantic subspaces: LiDAR-private, Image-private, Shared, and Interaction. Each subspace is assigned a dedicated expert, thereby preserving modality-specific cues while capturing cross-modal consensus. To adaptively combine expert outputs, we introduce an uncertainty-aware gating mechanism at the BEV-cell level, where unreliable experts are down-weighted based on predictive variance, complemented by a usage balance regularizer to prevent expert collapse. To enhance robustness in degraded conditions and promote role specialization, we further propose distribution-aware masking: during training, modality-drop scenarios are simulated using EMA-statistical surrogate features, and a specialization loss enforces distinct behaviors of private, shared, and interaction experts across complete and masked inputs. Experiments on nuScenes and Argoverse2 benchmarks demonstrate that SEFMAP achieves state-of-the-art performance, surpassing prior methods by +4.2% and +4.8% in mAP, respectively. SEF-MAPprovides a robust and effective solution for multi-modal HD map prediction under diverse and degraded conditions.
MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Feb 17, 2026Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.
H-WM: Robotic Task and Motion Planning Guided by Hierarchical World Model
Feb 11, 2026World models are becoming central to robotic planning and control, as they enable prediction of future state transitions. Existing approaches often emphasize video generation or natural language prediction, which are difficult to directly ground in robot actions and suffer from compounding errors over long horizons. Traditional task and motion planning relies on symbolic logic world models, such as planning domains, that are robot-executable and robust for long-horizon reasoning. However, these methods typically operate independently of visual perception, preventing synchronized symbolic and perceptual state prediction. We propose a Hierarchical World Model (H-WM) that jointly predicts logical and visual state transitions within a unified bilevel framework. H-WM combines a high-level logical world model with a low-level visual world model, integrating the robot-executable, long-horizon robustness of symbolic reasoning with perceptual grounding from visual observations. The hierarchical outputs provide stable and consistent intermediate guidance for long-horizon tasks, mitigating error accumulation and enabling robust execution across extended task sequences. To train H-WM, we introduce a robotic dataset that aligns robot motion with symbolic states, actions, and visual observations. Experiments across vision-language-action (VLA) control policies demonstrate the effectiveness and generality of the approach.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
IFFair: Influence Function-driven Sample Reweighting for Fair Classification
Dec 08, 2025
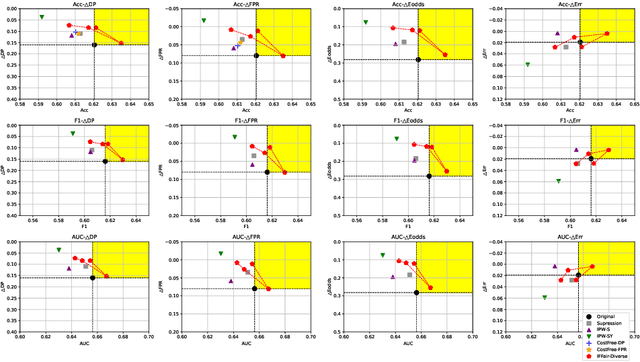
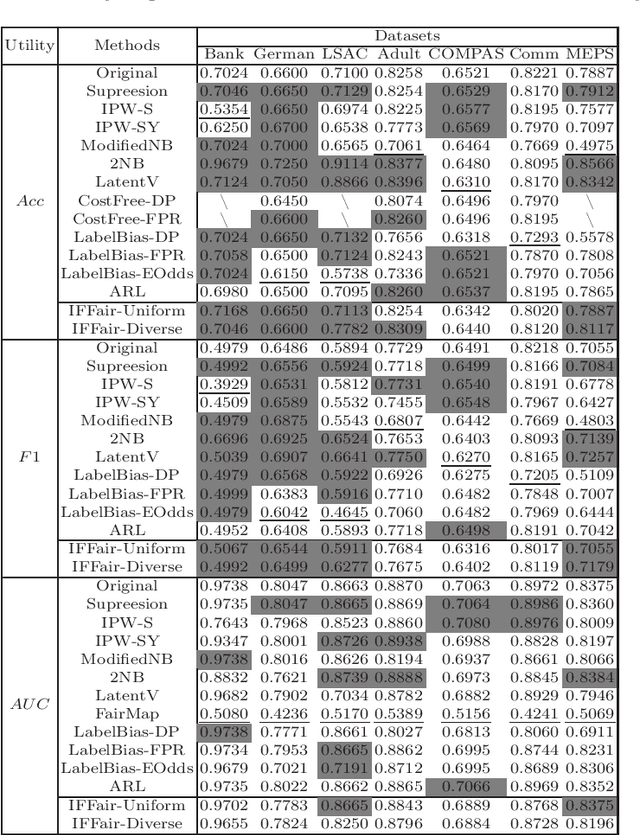
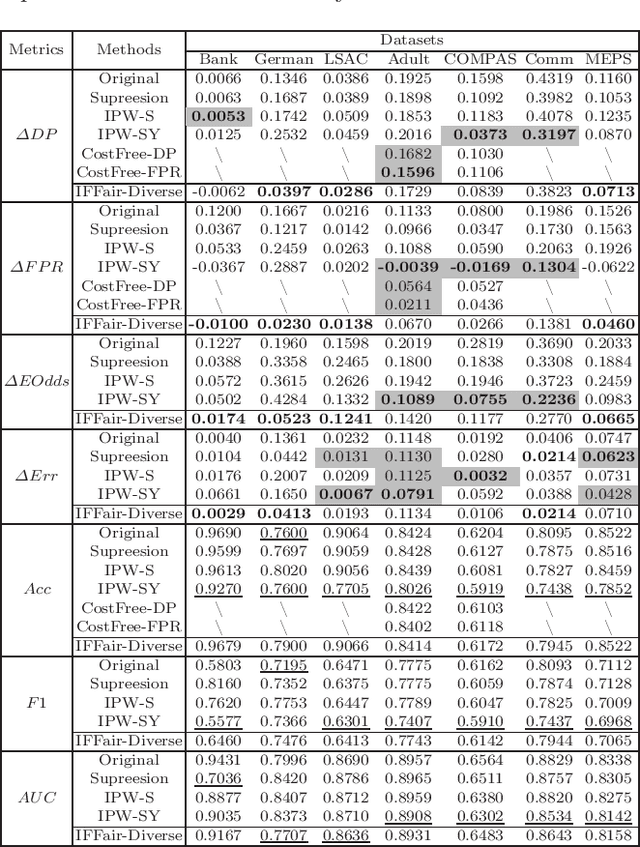
Because machine learning has significantly improved efficiency and convenience in the society, it's increasingly used to assist or replace human decision-making. However, the data-based pattern makes related algorithms learn and even exacerbate potential bias in samples, resulting in discriminatory decisions against certain unprivileged groups, depriving them of the rights to equal treatment, thus damaging the social well-being and hindering the development of related applications. Therefore, we propose a pre-processing method IFFair based on the influence function. Compared with other fairness optimization approaches, IFFair only uses the influence disparity of training samples on different groups as a guidance to dynamically adjust the sample weights during training without modifying the network structure, data features and decision boundaries. To evaluate the validity of IFFair, we conduct experiments on multiple real-world datasets and metrics. The experimental results show that our approach mitigates bias of multiple accepted metrics in the classification setting, including demographic parity, equalized odds, equality of opportunity and error rate parity without conflicts. It also demonstrates that IFFair achieves better trade-off between multiple utility and fairness metrics compared with previous pre-processing methods.
SocialNav-Map: Dynamic Mapping with Human Trajectory Prediction for Zero-Shot Social Navigation
Nov 18, 2025Social navigation in densely populated dynamic environments poses a significant challenge for autonomous mobile robots, requiring advanced strategies for safe interaction. Existing reinforcement learning (RL)-based methods require over 2000+ hours of extensive training and often struggle to generalize to unfamiliar environments without additional fine-tuning, limiting their practical application in real-world scenarios. To address these limitations, we propose SocialNav-Map, a novel zero-shot social navigation framework that combines dynamic human trajectory prediction with occupancy mapping, enabling safe and efficient navigation without the need for environment-specific training. Specifically, SocialNav-Map first transforms the task goal position into the constructed map coordinate system. Subsequently, it creates a dynamic occupancy map that incorporates predicted human movements as dynamic obstacles. The framework employs two complementary methods for human trajectory prediction: history prediction and orientation prediction. By integrating these predicted trajectories into the occupancy map, the robot can proactively avoid potential collisions with humans while efficiently navigating to its destination. Extensive experiments on the Social-HM3D and Social-MP3D datasets demonstrate that SocialNav-Map significantly outperforms state-of-the-art (SOTA) RL-based methods, which require 2,396 GPU hours of training. Notably, it reduces human collision rates by over 10% without necessitating any training in novel environments. By eliminating the need for environment-specific training, SocialNav-Map achieves superior navigation performance, paving the way for the deployment of social navigation systems in real-world environments characterized by diverse human behaviors. The code is available at: https://github.com/linglingxiansen/SocialNav-Map.
Is your VLM Sky-Ready? A Comprehensive Spatial Intelligence Benchmark for UAV Navigation
Nov 17, 2025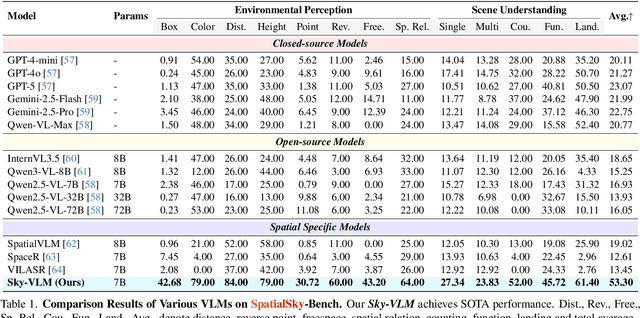
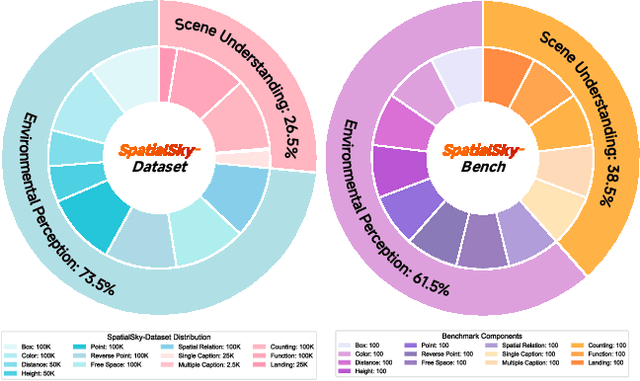
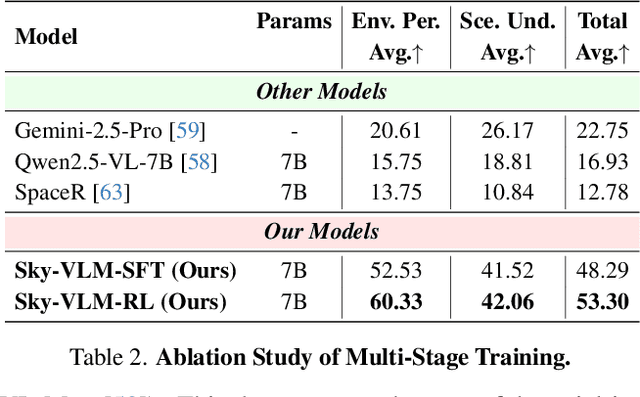
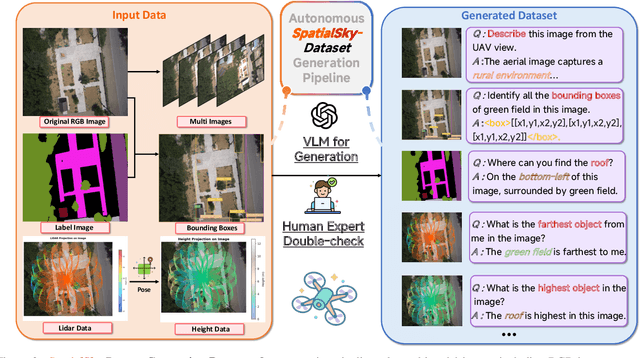
Vision-Language Models (VLMs), leveraging their powerful visual perception and reasoning capabilities, have been widely applied in Unmanned Aerial Vehicle (UAV) tasks. However, the spatial intelligence capabilities of existing VLMs in UAV scenarios remain largely unexplored, raising concerns about their effectiveness in navigating and interpreting dynamic environments. To bridge this gap, we introduce SpatialSky-Bench, a comprehensive benchmark specifically designed to evaluate the spatial intelligence capabilities of VLMs in UAV navigation. Our benchmark comprises two categories-Environmental Perception and Scene Understanding-divided into 13 subcategories, including bounding boxes, color, distance, height, and landing safety analysis, among others. Extensive evaluations of various mainstream open-source and closed-source VLMs reveal unsatisfactory performance in complex UAV navigation scenarios, highlighting significant gaps in their spatial capabilities. To address this challenge, we developed the SpatialSky-Dataset, a comprehensive dataset containing 1M samples with diverse annotations across various scenarios. Leveraging this dataset, we introduce Sky-VLM, a specialized VLM designed for UAV spatial reasoning across multiple granularities and contexts. Extensive experimental results demonstrate that Sky-VLM achieves state-of-the-art performance across all benchmark tasks, paving the way for the development of VLMs suitable for UAV scenarios. The source code is available at https://github.com/linglingxiansen/SpatialSKy.
RoboAfford++: A Generative AI-Enhanced Dataset for Multimodal Affordance Learning in Robotic Manipulation and Navigation
Nov 16, 2025Robotic manipulation and navigation are fundamental capabilities of embodied intelligence, enabling effective robot interactions with the physical world. Achieving these capabilities requires a cohesive understanding of the environment, including object recognition to localize target objects, object affordances to identify potential interaction areas and spatial affordances to discern optimal areas for both object placement and robot movement. While Vision-Language Models (VLMs) excel at high-level task planning and scene understanding, they often struggle to infer actionable positions for physical interaction, such as functional grasping points and permissible placement regions. This limitation stems from the lack of fine-grained annotations for object and spatial affordances in their training datasets. To tackle this challenge, we introduce RoboAfford++, a generative AI-enhanced dataset for multimodal affordance learning for both robotic manipulation and navigation. Our dataset comprises 869,987 images paired with 2.0 million question answering (QA) annotations, covering three critical tasks: object affordance recognition to identify target objects based on attributes and spatial relationships, object affordance prediction to pinpoint functional parts for manipulation, and spatial affordance localization to identify free space for object placement and robot navigation. Complementing this dataset, we propose RoboAfford-Eval, a comprehensive benchmark for assessing affordance-aware prediction in real-world scenarios, featuring 338 meticulously annotated samples across the same three tasks. Extensive experimental results reveal the deficiencies of existing VLMs in affordance learning, while fine-tuning on the RoboAfford++ dataset significantly enhances their ability to reason about object and spatial affordances, validating the dataset's effectiveness.
Team Xiaomi EV-AD VLA: Learning to Navigate Socially Through Proactive Risk Perception - Technical Report for IROS 2025 RoboSense Challenge Social Navigation Track
Oct 09, 2025In this report, we describe the technical details of our submission to the IROS 2025 RoboSense Challenge Social Navigation Track. This track focuses on developing RGBD-based perception and navigation systems that enable autonomous agents to navigate safely, efficiently, and socially compliantly in dynamic human-populated indoor environments. The challenge requires agents to operate from an egocentric perspective using only onboard sensors including RGB-D observations and odometry, without access to global maps or privileged information, while maintaining social norm compliance such as safe distances and collision avoidance. Building upon the Falcon model, we introduce a Proactive Risk Perception Module to enhance social navigation performance. Our approach augments Falcon with collision risk understanding that learns to predict distance-based collision risk scores for surrounding humans, which enables the agent to develop more robust spatial awareness and proactive collision avoidance behaviors. The evaluation on the Social-HM3D benchmark demonstrates that our method improves the agent's ability to maintain personal space compliance while navigating toward goals in crowded indoor scenes with dynamic human agents, achieving 2nd place among 16 participating teams in the challenge.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.