 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Visual Grounding from Event Cameras
Sep 11, 2025Event cameras capture changes in brightness with microsecond precision and remain reliable under motion blur and challenging illumination, offering clear advantages for modeling highly dynamic scenes. Yet, their integration with natural language understanding has received little attention, leaving a gap in multimodal perception. To address this, we introduce Talk2Event, the first large-scale benchmark for language-driven object grounding using event data. Built on real-world driving scenarios, Talk2Event comprises 5,567 scenes, 13,458 annotated objects, and more than 30,000 carefully validated referring expressions. Each expression is enriched with four structured attributes -- appearance, status, relation to the viewer, and relation to surrounding objects -- that explicitly capture spatial, temporal, and relational cues. This attribute-centric design supports interpretable and compositional grounding, enabling analysis that moves beyond simple object recognition to contextual reasoning in dynamic environments. We envision Talk2Event as a foundation for advancing multimodal and temporally-aware perception, with applications spanning robotics, human-AI interaction, and so on.
Talk2Event: Grounded Understanding of Dynamic Scenes from Event Cameras
Jul 23, 2025Event cameras offer microsecond-level latency and robustness to motion blur, making them ideal for understanding dynamic environments. Yet, connecting these asynchronous streams to human language remains an open challenge. We introduce Talk2Event, the first large-scale benchmark for language-driven object grounding in event-based perception. Built from real-world driving data, we provide over 30,000 validated referring expressions, each enriched with four grounding attributes -- appearance, status, relation to viewer, and relation to other objects -- bridging spatial, temporal, and relational reasoning. To fully exploit these cues, we propose EventRefer, an attribute-aware grounding framework that dynamically fuses multi-attribute representations through a Mixture of Event-Attribute Experts (MoEE). Our method adapts to different modalities and scene dynamics, achieving consistent gains over state-of-the-art baselines in event-only, frame-only, and event-frame fusion settings. We hope our dataset and approach will establish a foundation for advancing multimodal, temporally-aware, and language-driven perception in real-world robotics and autonomy.
Stairway to Success: Zero-Shot Floor-Aware Object-Goal Navigation via LLM-Driven Coarse-to-Fine Exploration
May 29, 2025Object-Goal Navigation (OGN) remains challenging in real-world, multi-floor environments and under open-vocabulary object descriptions. We observe that most episodes in widely used benchmarks such as HM3D and MP3D involve multi-floor buildings, with many requiring explicit floor transitions. However, existing methods are often limited to single-floor settings or predefined object categories. To address these limitations, we tackle two key challenges: (1) efficient cross-level planning and (2) zero-shot object-goal navigation (ZS-OGN), where agents must interpret novel object descriptions without prior exposure. We propose ASCENT, a framework that combines a Multi-Floor Spatial Abstraction module for hierarchical semantic mapping and a Coarse-to-Fine Frontier Reasoning module leveraging Large Language Models (LLMs) for context-aware exploration, without requiring additional training on new object semantics or locomotion data. Our method outperforms state-of-the-art ZS-OGN approaches on HM3D and MP3D benchmarks while enabling efficient multi-floor navigation. We further validate its practicality through real-world deployment on a quadruped robot, achieving successful object exploration across unseen floors.
Zero-Shot 3D Visual Grounding from Vision-Language Models
May 28, 2025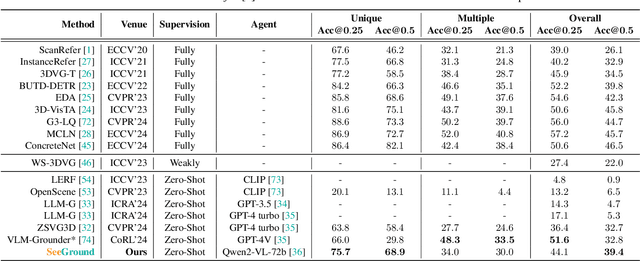
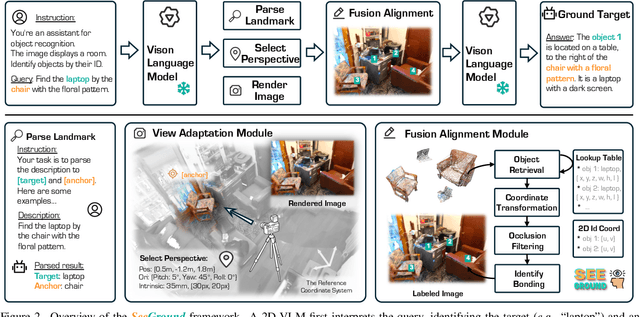
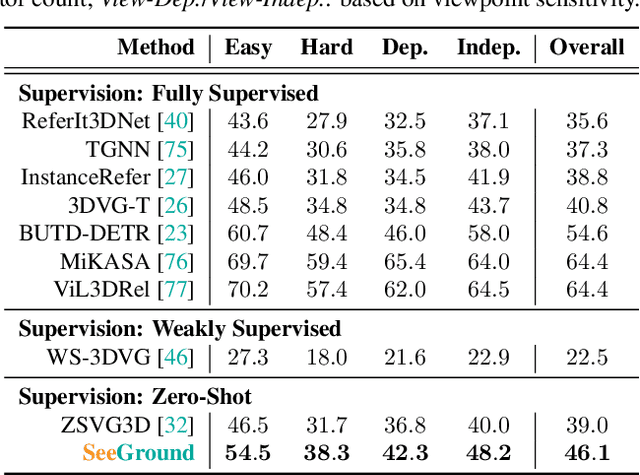
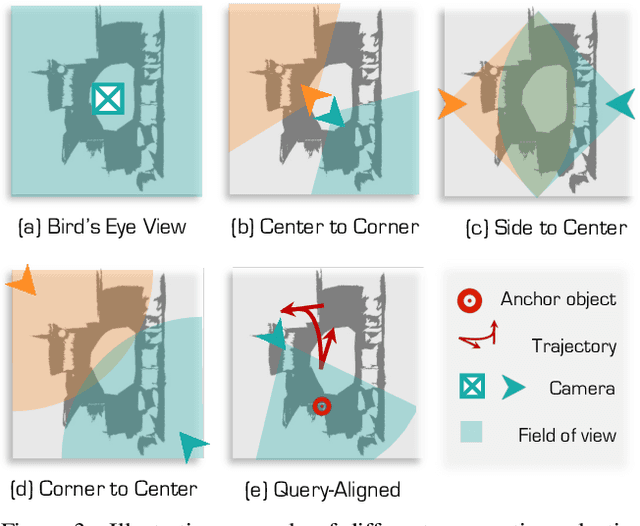
3D Visual Grounding (3DVG) seeks to locate target objects in 3D scenes using natural language descriptions, enabling downstream applications such as augmented reality and robotics. Existing approaches typically rely on labeled 3D data and predefined categories, limiting scalability to open-world settings. We present SeeGround, a zero-shot 3DVG framework that leverages 2D Vision-Language Models (VLMs) to bypass the need for 3D-specific training. To bridge the modality gap, we introduce a hybrid input format that pairs query-aligned rendered views with spatially enriched textual descriptions. Our framework incorporates two core components: a Perspective Adaptation Module that dynamically selects optimal viewpoints based on the query, and a Fusion Alignment Module that integrates visual and spatial signals to enhance localization precision. Extensive evaluations on ScanRefer and Nr3D confirm that SeeGround achieves substantial improvements over existing zero-shot baselines -- outperforming them by 7.7% and 7.1%, respectively -- and even rivals fully supervised alternatives, demonstrating strong generalization under challenging conditions.
WECAR: An End-Edge Collaborative Inference and Training Framework for WiFi-Based Continuous Human Activity Recognition
Mar 09, 2025WiFi-based human activity recognition (HAR) holds significant promise for ubiquitous sensing in smart environments. A critical challenge lies in enabling systems to dynamically adapt to evolving scenarios, learning new activities without catastrophic forgetting of prior knowledge, while adhering to the stringent computational constraints of edge devices. Current approaches struggle to reconcile these requirements due to prohibitive storage demands for retaining historical data and inefficient parameter utilization. We propose WECAR, an end-edge collaborative inference and training framework for WiFi-based continuous HAR, which decouples computational workloads to overcome these limitations. In this framework, edge devices handle model training, lightweight optimization, and updates, while end devices perform efficient inference. WECAR introduces two key innovations, i.e., dynamic continual learning with parameter efficiency and hierarchical distillation for end deployment. For the former, we propose a transformer-based architecture enhanced by task-specific dynamic model expansion and stability-aware selective retraining. For the latter, we propose a dual-phase distillation mechanism that includes multi-head self-attention relation distillation and prefix relation distillation. We implement WECAR based on heterogeneous hardware using Jetson Nano as edge devices and the ESP32 as end devices, respectively. Our experiments across three public WiFi datasets reveal that WECAR not only outperforms several state-of-the-art methods in performance and parameter efficiency, but also achieves a substantial reduction in the model's parameter count post-optimization without sacrificing accuracy. This validates its practicality for resource-constrained environments.
Global-Aware Monocular Semantic Scene Completion with State Space Models
Mar 09, 2025


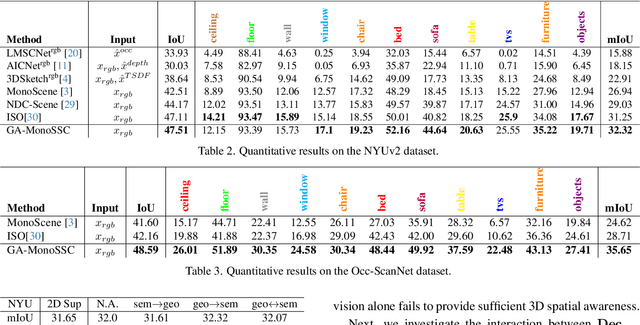
Monocular Semantic Scene Completion (MonoSSC) reconstructs and interprets 3D environments from a single image, enabling diverse real-world applications. However, existing methods are often constrained by the local receptive field of Convolutional Neural Networks (CNNs), making it challenging to handle the non-uniform distribution of projected points (Fig. \ref{fig:perspective}) and effectively reconstruct missing information caused by the 3D-to-2D projection. In this work, we introduce GA-MonoSSC, a hybrid architecture for MonoSSC that effectively captures global context in both the 2D image domain and 3D space. Specifically, we propose a Dual-Head Multi-Modality Encoder, which leverages a Transformer architecture to capture spatial relationships across all features in the 2D image domain, enabling more comprehensive 2D feature extraction. Additionally, we introduce the Frustum Mamba Decoder, built on the State Space Model (SSM), to efficiently capture long-range dependencies in 3D space. Furthermore, we propose a frustum reordering strategy within the Frustum Mamba Decoder to mitigate feature discontinuities in the reordered voxel sequence, ensuring better alignment with the scan mechanism of the State Space Model (SSM) for improved 3D representation learning. We conduct extensive experiments on the widely used Occ-ScanNet and NYUv2 datasets, demonstrating that our proposed method achieves state-of-the-art performance, validating its effectiveness. The code will be released upon acceptance.
ConSense: Continually Sensing Human Activity with WiFi via Growing and Picking
Feb 18, 2025WiFi-based human activity recognition (HAR) holds significant application potential across various fields. To handle dynamic environments where new activities are continuously introduced, WiFi-based HAR systems must adapt by learning new concepts without forgetting previously learned ones. Furthermore, retaining knowledge from old activities by storing historical exemplar is impractical for WiFi-based HAR due to privacy concerns and limited storage capacity of edge devices. In this work, we propose ConSense, a lightweight and fast-adapted exemplar-free class incremental learning framework for WiFi-based HAR. The framework leverages the transformer architecture and involves dynamic model expansion and selective retraining to preserve previously learned knowledge while integrating new information. Specifically, during incremental sessions, small-scale trainable parameters that are trained specifically on the data of each task are added in the multi-head self-attention layer. In addition, a selective retraining strategy that dynamically adjusts the weights in multilayer perceptron based on the performance stability of neurons across tasks is used. Rather than training the entire model, the proposed strategies of dynamic model expansion and selective retraining reduce the overall computational load while balancing stability on previous tasks and plasticity on new tasks. Evaluation results on three public WiFi datasets demonstrate that ConSense not only outperforms several competitive approaches but also requires fewer parameters, highlighting its practical utility in class-incremental scenarios for HAR.
SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding
Dec 05, 2024



3D Visual Grounding (3DVG) aims to locate objects in 3D scenes based on textual descriptions, which is essential for applications like augmented reality and robotics. Traditional 3DVG approaches rely on annotated 3D datasets and predefined object categories, limiting scalability and adaptability. To overcome these limitations, we introduce SeeGround, a zero-shot 3DVG framework leveraging 2D Vision-Language Models (VLMs) trained on large-scale 2D data. We propose to represent 3D scenes as a hybrid of query-aligned rendered images and spatially enriched text descriptions, bridging the gap between 3D data and 2D-VLMs input formats. We propose two modules: the Perspective Adaptation Module, which dynamically selects viewpoints for query-relevant image rendering, and the Fusion Alignment Module, which integrates 2D images with 3D spatial descriptions to enhance object localization. Extensive experiments on ScanRefer and Nr3D demonstrate that our approach outperforms existing zero-shot methods by large margins. Notably, we exceed weakly supervised methods and rival some fully supervised ones, outperforming previous SOTA by 7.7% on ScanRefer and 7.1% on Nr3D, showcasing its effectiveness.
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
May 18, 2024Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.