 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-GS++:Improving LiDAR Gaussian Reconstruction via Diffusion Priors
Nov 15, 2025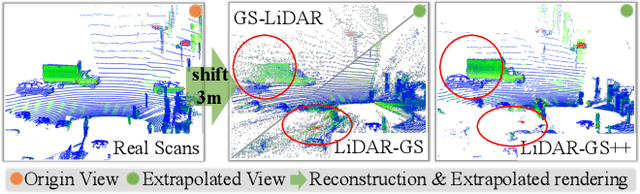
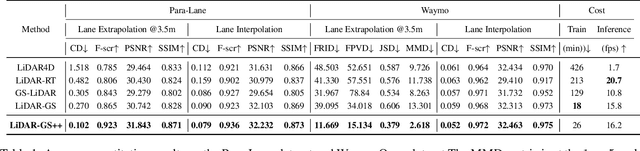
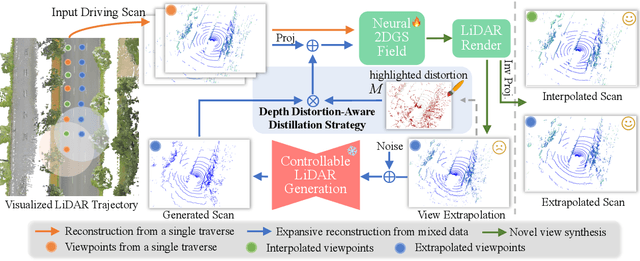
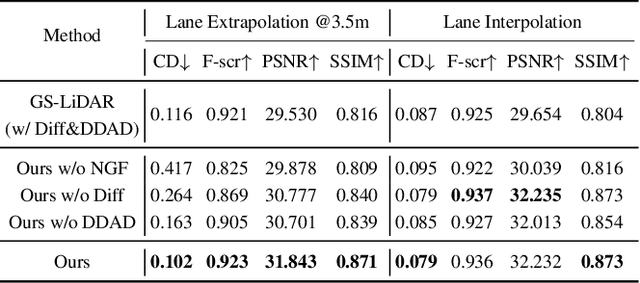
Recent GS-based rendering has made significant progress for LiDAR, surpassing Neural Radiance Fields (NeRF) in both quality and speed. However, these methods exhibit artifacts in extrapolated novel view synthesis due to the incomplete reconstruction from single traversal scans. To address this limitation, we present LiDAR-GS++, a LiDAR Gaussian Splatting reconstruction method enhanced by diffusion priors for real-time and high-fidelity re-simulation on public urban roads. Specifically, we introduce a controllable LiDAR generation model conditioned on coarsely extrapolated rendering to produce extra geometry-consistent scans and employ an effective distillation mechanism for expansive reconstruction. By extending reconstruction to under-fitted regions, our approach ensures global geometric consistency for extrapolative novel views while preserving detailed scene surfaces captured by sensors. Experiments on multiple public datasets demonstrate that LiDAR-GS++ achieves state-of-the-art performance for both interpolated and extrapolated viewpoints, surpassing existing GS and NeRF-based methods.
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
May 18, 2024Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
2L3: Lifting Imperfect Generated 2D Images into Accurate 3D
Jan 29, 2024Reconstructing 3D objects from a single image is an intriguing but challenging problem. One promising solution is to utilize multi-view (MV) 3D reconstruction to fuse generated MV images into consistent 3D objects. However, the generated images usually suffer from inconsistent lighting, misaligned geometry, and sparse views, leading to poor reconstruction quality. To cope with these problems, we present a novel 3D reconstruction framework that leverages intrinsic decomposition guidance, transient-mono prior guidance, and view augmentation to cope with the three issues, respectively. Specifically, we first leverage to decouple the shading information from the generated images to reduce the impact of inconsistent lighting; then, we introduce mono prior with view-dependent transient encoding to enhance the reconstructed normal; and finally, we design a view augmentation fusion strategy that minimizes pixel-level loss in generated sparse views and semantic loss in augmented random views, resulting in view-consistent geometry and detailed textures. Our approach, therefore, enables the integration of a pre-trained MV image generator and a neural network-based volumetric signed distance function (SDF) representation for a single image to 3D object reconstruction. We evaluate our framework on various datasets and demonstrate its superior performance in both quantitative and qualitative assessments, signifying a significant advancement in 3D object reconstruction. Compared with the latest state-of-the-art method Syncdreamer~\cite{liu2023syncdreamer}, we reduce the Chamfer Distance error by about 36\% and improve PSNR by about 30\% .
In-Hand 3D Object Reconstruction from a Monocular RGB Video
Dec 27, 2023

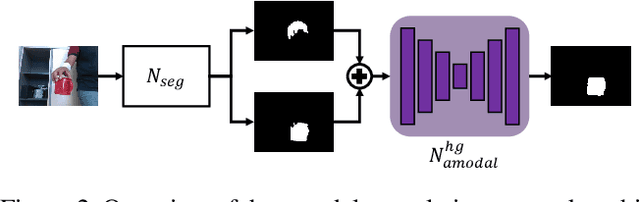

Our work aims to reconstruct a 3D object that is held and rotated by a hand in front of a static RGB camera. Previous methods that use implicit neural representations to recover the geometry of a generic hand-held object from multi-view images achieved compelling results in the visible part of the object. However, these methods falter in accurately capturing the shape within the hand-object contact region due to occlusion. In this paper, we propose a novel method that deals with surface reconstruction under occlusion by incorporating priors of 2D occlusion elucidation and physical contact constraints. For the former, we introduce an object amodal completion network to infer the 2D complete mask of objects under occlusion. To ensure the accuracy and view consistency of the predicted 2D amodal masks, we devise a joint optimization method for both amodal mask refinement and 3D reconstruction. For the latter, we impose penetration and attraction constraints on the local geometry in contact regions. We evaluate our approach on HO3D and HOD datasets and demonstrate that it outperforms the state-of-the-art methods in terms of reconstruction surface quality, with an improvement of $52\%$ on HO3D and $20\%$ on HOD. Project webpage: https://east-j.github.io/ihor.
Holistic Inverse Rendering of Complex Facade via Aerial 3D Scanning
Nov 20, 2023



In this work, we use multi-view aerial images to reconstruct the geometry, lighting, and material of facades using neural signed distance fields (SDFs). Without the requirement of complex equipment, our method only takes simple RGB images captured by a drone as inputs to enable physically based and photorealistic novel-view rendering, relighting, and editing. However, a real-world facade usually has complex appearances ranging from diffuse rocks with subtle details to large-area glass windows with specular reflections, making it hard to attend to everything. As a result, previous methods can preserve the geometry details but fail to reconstruct smooth glass windows or verse vise. In order to address this challenge, we introduce three spatial- and semantic-adaptive optimization strategies, including a semantic regularization approach based on zero-shot segmentation techniques to improve material consistency, a frequency-aware geometry regularization to balance surface smoothness and details in different surfaces, and a visibility probe-based scheme to enable efficient modeling of the local lighting in large-scale outdoor environments. In addition, we capture a real-world facade aerial 3D scanning image set and corresponding point clouds for training and benchmarking. The experiment demonstrates the superior quality of our method on facade holistic inverse rendering, novel view synthesis, and scene editing compared to state-of-the-art baselines.