 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFAvatar: Pose-Fusion 3D Personalized Avatar Reconstruction from Real-World Outfit-of-the-Day Photos
Nov 18, 2025We propose PFAvatar (Pose-Fusion Avatar), a new method that reconstructs high-quality 3D avatars from Outfit of the Day(OOTD) photos, which exhibit diverse poses, occlusions, and complex backgrounds. Our method consists of two stages: (1) fine-tuning a pose-aware diffusion model from few-shot OOTD examples and (2) distilling a 3D avatar represented by a neural radiance field (NeRF). In the first stage, unlike previous methods that segment images into assets (e.g., garments, accessories) for 3D assembly, which is prone to inconsistency, we avoid decomposition and directly model the full-body appearance. By integrating a pre-trained ControlNet for pose estimation and a novel Condition Prior Preservation Loss (CPPL), our method enables end-to-end learning of fine details while mitigating language drift in few-shot training. Our method completes personalization in just 5 minutes, achieving a 48x speed-up compared to previous approaches. In the second stage, we introduce a NeRF-based avatar representation optimized by canonical SMPL-X space sampling and Multi-Resolution 3D-SDS. Compared to mesh-based representations that suffer from resolution-dependent discretization and erroneous occluded geometry, our continuous radiance field can preserve high-frequency textures (e.g., hair) and handle occlusions correctly through transmittance. Experiments demonstrate that PFAvatar outperforms state-of-the-art methods in terms of reconstruction fidelity, detail preservation, and robustness to occlusions/truncations, advancing practical 3D avatar generation from real-world OOTD albums. In addition, the reconstructed 3D avatar supports downstream applications such as virtual try-on, animation, and human video reenactment, further demonstrating the versatility and practical value of our approach.
LiDAR-GS++:Improving LiDAR Gaussian Reconstruction via Diffusion Priors
Nov 15, 2025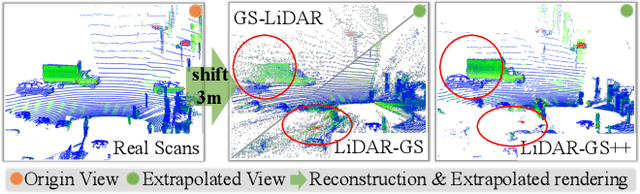
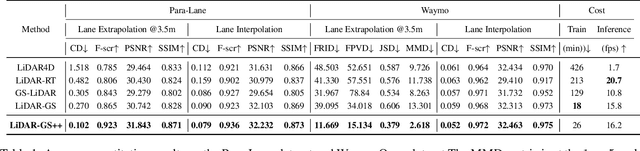
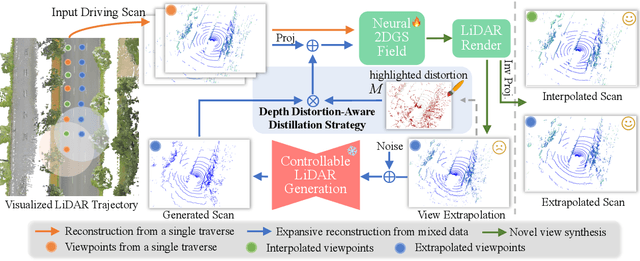
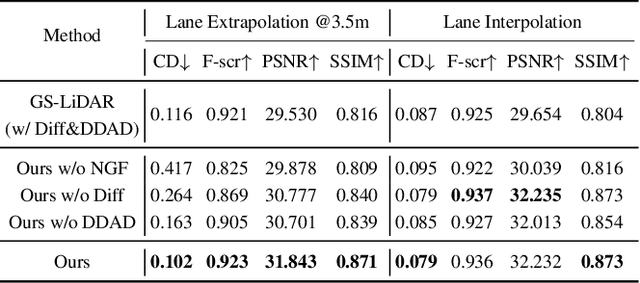
Recent GS-based rendering has made significant progress for LiDAR, surpassing Neural Radiance Fields (NeRF) in both quality and speed. However, these methods exhibit artifacts in extrapolated novel view synthesis due to the incomplete reconstruction from single traversal scans. To address this limitation, we present LiDAR-GS++, a LiDAR Gaussian Splatting reconstruction method enhanced by diffusion priors for real-time and high-fidelity re-simulation on public urban roads. Specifically, we introduce a controllable LiDAR generation model conditioned on coarsely extrapolated rendering to produce extra geometry-consistent scans and employ an effective distillation mechanism for expansive reconstruction. By extending reconstruction to under-fitted regions, our approach ensures global geometric consistency for extrapolative novel views while preserving detailed scene surfaces captured by sensors. Experiments on multiple public datasets demonstrate that LiDAR-GS++ achieves state-of-the-art performance for both interpolated and extrapolated viewpoints, surpassing existing GS and NeRF-based methods.
Leveraging Pretrained Diffusion Models for Zero-Shot Part Assembly
May 01, 20253D part assembly aims to understand part relationships and predict their 6-DoF poses to construct realistic 3D shapes, addressing the growing demand for autonomous assembly, which is crucial for robots. Existing methods mainly estimate the transformation of each part by training neural networks under supervision, which requires a substantial quantity of manually labeled data. However, the high cost of data collection and the immense variability of real-world shapes and parts make traditional methods impractical for large-scale applications. In this paper, we propose first a zero-shot part assembly method that utilizes pre-trained point cloud diffusion models as discriminators in the assembly process, guiding the manipulation of parts to form realistic shapes. Specifically, we theoretically demonstrate that utilizing a diffusion model for zero-shot part assembly can be transformed into an Iterative Closest Point (ICP) process. Then, we propose a novel pushing-away strategy to address the overlap parts, thereby further enhancing the robustness of the method. To verify our work, we conduct extensive experiments and quantitative comparisons to several strong baseline methods, demonstrating the effectiveness of the proposed approach, which even surpasses the supervised learning method. The code has been released on https://github.com/Ruiyuan-Zhang/Zero-Shot-Assembly.
* 10 pages, 12 figures, Accepted by IJCAI-2025
OmniVDiff: Omni Controllable Video Diffusion for Generation and Understanding
Apr 15, 2025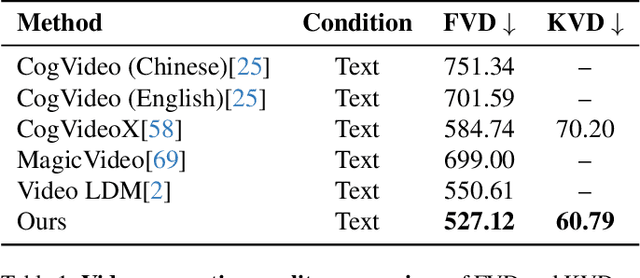
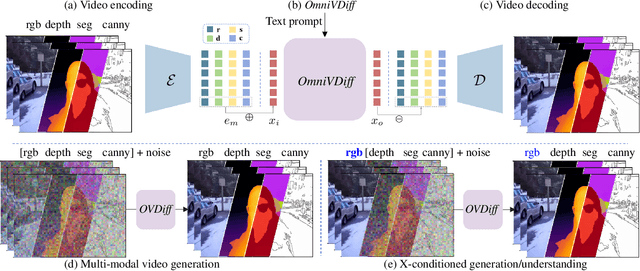
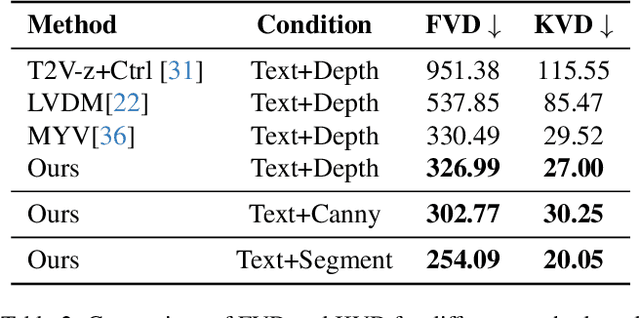

In this paper, we propose a novel framework for controllable video diffusion, OmniVDiff, aiming to synthesize and comprehend multiple video visual content in a single diffusion model. To achieve this, OmniVDiff treats all video visual modalities in the color space to learn a joint distribution, while employing an adaptive control strategy that dynamically adjusts the role of each visual modality during the diffusion process, either as a generation modality or a conditioning modality. This allows flexible manipulation of each modality's role, enabling support for a wide range of tasks. Consequently, our model supports three key functionalities: (1) Text-conditioned video generation: multi-modal visual video sequences (i.e., rgb, depth, canny, segmentaion) are generated based on the text conditions in one diffusion process; (2) Video understanding: OmniVDiff can estimate the depth, canny map, and semantic segmentation across the input rgb frames while ensuring coherence with the rgb input; and (3) X-conditioned video generation: OmniVDiff generates videos conditioned on fine-grained attributes (e.g., depth maps or segmentation maps). By integrating these diverse tasks into a unified video diffusion framework, OmniVDiff enhances the flexibility and scalability for controllable video diffusion, making it an effective tool for a variety of downstream applications, such as video-to-video translation. Extensive experiments demonstrate the effectiveness of our approach, highlighting its potential for various video-related applications.
LangPert: Detecting and Handling Task-level Perturbations for Robust Object Rearrangement
Apr 14, 2025Task execution for object rearrangement could be challenged by Task-Level Perturbations (TLP), i.e., unexpected object additions, removals, and displacements that can disrupt underlying visual policies and fundamentally compromise task feasibility and progress. To address these challenges, we present LangPert, a language-based framework designed to detect and mitigate TLP situations in tabletop rearrangement tasks. LangPert integrates a Visual Language Model (VLM) to comprehensively monitor policy's skill execution and environmental TLP, while leveraging the Hierarchical Chain-of-Thought (HCoT) reasoning mechanism to enhance the Large Language Model (LLM)'s contextual understanding and generate adaptive, corrective skill-execution plans. Our experimental results demonstrate that LangPert handles diverse TLP situations more effectively than baseline methods, achieving higher task completion rates, improved execution efficiency, and potential generalization to unseen scenarios.
LiDAR-GS:Real-time LiDAR Re-Simulation using Gaussian Splatting
Oct 07, 2024



LiDAR simulation plays a crucial role in closed-loop simulation for autonomous driving. Although recent advancements, such as the use of reconstructed mesh and Neural Radiance Fields (NeRF), have made progress in simulating the physical properties of LiDAR, these methods have struggled to achieve satisfactory frame rates and rendering quality. To address these limitations, we present LiDAR-GS, the first LiDAR Gaussian Splatting method, for real-time high-fidelity re-simulation of LiDAR sensor scans in public urban road scenes. The vanilla Gaussian Splatting, designed for camera models, cannot be directly applied to LiDAR re-simulation. To bridge the gap between passive camera and active LiDAR, our LiDAR-GS designs a differentiable laser beam splatting, grounded in the LiDAR range view model. This innovation allows for precise surface splatting by projecting lasers onto micro cross-sections, effectively eliminating artifacts associated with local affine approximations. Additionally, LiDAR-GS leverages Neural Gaussian Fields, which further integrate view-dependent clues, to represent key LiDAR properties that are influenced by the incident angle and external factors. Combining these practices with some essential adaptations, e.g., dynamic instances decomposition, our approach succeeds in simultaneously re-simulating depth, intensity, and ray-drop channels, achieving state-of-the-art results in both rendering frame rate and quality on publically available large scene datasets. Our source code will be made publicly available.
SGW-based Multi-Task Learning in Vision Tasks
Oct 03, 2024Multi-task-learning(MTL) is a multi-target optimization task. Neural networks try to realize each target using a shared interpretative space within MTL. However, as the scale of datasets expands and the complexity of tasks increases, knowledge sharing becomes increasingly challenging. In this paper, we first re-examine previous cross-attention MTL methods from the perspective of noise. We theoretically analyze this issue and identify it as a flaw in the cross-attention mechanism. To address this issue, we propose an information bottleneck knowledge extraction module (KEM). This module aims to reduce inter-task interference by constraining the flow of information, thereby reducing computational complexity. Furthermore, we have employed neural collapse to stabilize the knowledge-selection process. That is, before input to KEM, we projected the features into ETF space. This mapping makes our method more robust. We implemented and conducted comparative experiments with this method on multiple datasets. The results demonstrate that our approach significantly outperforms existing methods in multi-task learning.
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Sep 07, 2024



Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.
OpenSlot: Mixed Open-set Recognition with Object-centric Learning
Jul 02, 2024



Existing open-set recognition (OSR) studies typically assume that each image contains only one class label, and the unknown test set (negative) has a disjoint label space from the known test set (positive), a scenario termed full-label shift. This paper introduces the mixed OSR problem, where test images contain multiple class semantics, with known and unknown classes co-occurring in negatives, leading to a more challenging super-label shift. Addressing the mixed OSR requires classification models to accurately distinguish different class semantics within images and measure their "knowness". In this study, we propose the OpenSlot framework, built upon object-centric learning. OpenSlot utilizes slot features to represent diverse class semantics and produce class predictions. Through our proposed anti-noise-slot (ANS) technique, we mitigate the impact of noise (invalid and background) slots during classification training, effectively addressing the semantic misalignment between class predictions and the ground truth. We conduct extensive experiments with OpenSlot on mixed & conventional OSR benchmarks. Without elaborate designs, OpenSlot not only exceeds existing OSR studies in detecting super-label shifts across single & multi-label mixed OSR tasks but also achieves state-of-the-art performance on conventional benchmarks. Remarkably, our method can localize class objects without using bounding boxes during training. The competitive performance in open-set object detection demonstrates OpenSlot's ability to explicitly explain label shifts and benefits in computational efficiency and generalization.
MIRReS: Multi-bounce Inverse Rendering using Reservoir Sampling
Jun 25, 2024



We present MIRReS, a novel two-stage inverse rendering framework that jointly reconstructs and optimizes the explicit geometry, material, and lighting from multi-view images. Unlike previous methods that rely on implicit irradiance fields or simplified path tracing algorithms, our method extracts an explicit geometry (triangular mesh) in stage one, and introduces a more realistic physically-based inverse rendering model that utilizes multi-bounce path tracing and Monte Carlo integration. By leveraging multi-bounce path tracing, our method effectively estimates indirect illumination, including self-shadowing and internal reflections, which improves the intrinsic decomposition of shape, material, and lighting. Moreover, we incorporate reservoir sampling into our framework to address the noise in Monte Carlo integration, enhancing convergence and facilitating gradient-based optimization with low sample counts. Through qualitative and quantitative evaluation of several scenarios, especially in challenging scenarios with complex shadows, we demonstrate that our method achieves state-of-the-art performance on decomposition results. Additionally, our optimized explicit geometry enables applications such as scene editing, relighting, and material editing with modern graphics engines or CAD software. The source code is available at https://brabbitdousha.github.io/MIRReS/