 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Credit the Right Steps: Objective-aware Process Optimization for Visual Generation
Apr 21, 2026Reinforcement learning, particularly Group Relative Policy Optimization (GRPO), has emerged as an effective framework for post-training visual generative models with human preference signals. However, its effectiveness is fundamentally limited by coarse reward credit assignment. In modern visual generation, multiple reward models are often used to capture heterogeneous objectives, such as visual quality, motion consistency, and text alignment. Existing GRPO pipelines typically collapse these rewards into a single static scalar and propagate it uniformly across the entire diffusion trajectory. This design ignores the stage-specific roles of different denoising steps and produces mistimed or incompatible optimization signals. To address this issue, we propose Objective-aware Trajectory Credit Assignment (OTCA), a structured framework for fine-grained GRPO training. OTCA consists of two key components. Trajectory-Level Credit Decomposition estimates the relative importance of different denoising steps. Multi-Objective Credit Allocation adaptively weights and combines multiple reward signals throughout the denoising process. By jointly modeling temporal credit and objective-level credit, OTCA converts coarse reward supervision into a structured, timestep-aware training signal that better matches the iterative nature of diffusion-based generation. Extensive experiments show that OTCA consistently improves both image and video generation quality across evaluation metrics.
Reward-Aware Trajectory Shaping for Few-step Visual Generation
Apr 16, 2026Achieving high-fidelity generation in extremely few sampling steps has long been a central goal of generative modeling. Existing approaches largely rely on distillation-based frameworks to compress the original multi-step denoising process into a few-step generator. However, such methods inherently constrain the student to imitate a stronger multi-step teacher, imposing the teacher as an upper bound on student performance. We argue that introducing \textbf{preference alignment awareness} enables the student to optimize toward reward-preferred generation quality, potentially surpassing the teacher instead of being restricted to rigid teacher imitation. To this end, we propose \textbf{Reward-Aware Trajectory Shaping (RATS)}, a lightweight framework for preference-aligned few-step generation. Specifically, teacher and student latent trajectories are aligned at key denoising stages through horizon matching, while a \textbf{reward-aware gate} is introduced to adaptively regulate teacher guidance based on their relative reward performance. Trajectory shaping is strengthened when the teacher achieves higher rewards, and relaxed when the student matches or surpasses the teacher, thereby enabling continued reward-driven improvement. By seamlessly integrating trajectory distillation, reward-aware gating, and preference alignment, RATS effectively transfers preference-relevant knowledge from high-step generators without incurring additional test-time computational overhead. Experimental results demonstrate that RATS substantially improves the efficiency--quality trade-off in few-step visual generation, significantly narrowing the gap between few-step students and stronger multi-step generators.
Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
TeleBoost: A Systematic Alignment Framework for High-Fidelity, Controllable, and Robust Video Generation
Feb 07, 2026Post-training is the decisive step for converting a pretrained video generator into a production-oriented model that is instruction-following, controllable, and robust over long temporal horizons. This report presents a systematical post-training framework that organizes supervised policy shaping, reward-driven reinforcement learning, and preference-based refinement into a single stability-constrained optimization stack. The framework is designed around practical video-generation constraints, including high rollout cost, temporally compounding failure modes, and feedback that is heterogeneous, uncertain, and often weakly discriminative. By treating optimization as a staged, diagnostic-driven process rather than a collection of isolated tricks, the report summarizes a cohesive recipe for improving perceptual fidelity, temporal coherence, and prompt adherence while preserving the controllability established at initialization. The resulting framework provides a clear blueprint for building scalable post-training pipelines that remain stable, extensible, and effective in real-world deployment settings.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
Uni-Inter: Unifying 3D Human Motion Synthesis Across Diverse Interaction Contexts
Nov 17, 2025We present Uni-Inter, a unified framework for human motion generation that supports a wide range of interaction scenarios: including human-human, human-object, and human-scene-within a single, task-agnostic architecture. In contrast to existing methods that rely on task-specific designs and exhibit limited generalization, Uni-Inter introduces the Unified Interactive Volume (UIV), a volumetric representation that encodes heterogeneous interactive entities into a shared spatial field. This enables consistent relational reasoning and compound interaction modeling. Motion generation is formulated as joint-wise probabilistic prediction over the UIV, allowing the model to capture fine-grained spatial dependencies and produce coherent, context-aware behaviors. Experiments across three representative interaction tasks demonstrate that Uni-Inter achieves competitive performance and generalizes well to novel combinations of entities. These results suggest that unified modeling of compound interactions offers a promising direction for scalable motion synthesis in complex environments.
Free3D: 3D Human Motion Emerges from Single-View 2D Supervision
Nov 14, 2025Recent 3D human motion generation models demonstrate remarkable reconstruction accuracy yet struggle to generalize beyond training distributions. This limitation arises partly from the use of precise 3D supervision, which encourages models to fit fixed coordinate patterns instead of learning the essential 3D structure and motion semantic cues required for robust generalization.To overcome this limitation, we propose Free3D, a framework that synthesizes realistic 3D motions without any 3D motion annotations. Free3D introduces a Motion-Lifting Residual Quantized VAE (ML-RQ) that maps 2D motion sequences into 3D-consistent latent spaces, and a suite of 3D-free regularization objectives enforcing view consistency, orientation coherence, and physical plausibility. Trained entirely on 2D motion data, Free3D generates diverse, temporally coherent, and semantically aligned 3D motions, achieving performance comparable to or even surpassing fully 3D-supervised counterparts. These results suggest that relaxing explicit 3D supervision encourages stronger structural reasoning and generalization, offering a scalable and data-efficient paradigm for 3D motion generation.
SpatialLock: Precise Spatial Control in Text-to-Image Synthesis
Nov 06, 2025
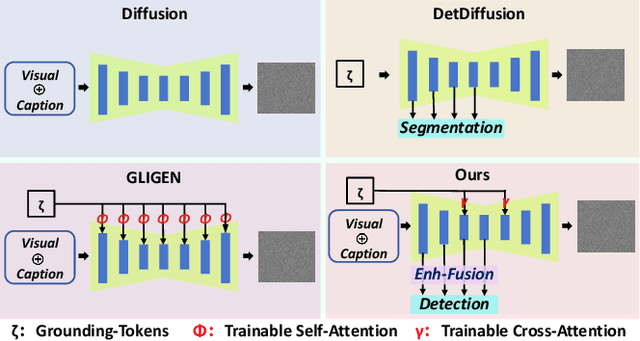


Text-to-Image (T2I) synthesis has made significant advancements in recent years, driving applications such as generating datasets automatically. However, precise control over object localization in generated images remains a challenge. Existing methods fail to fully utilize positional information, leading to an inadequate understanding of object spatial layouts. To address this issue, we propose SpatialLock, a novel framework that leverages perception signals and grounding information to jointly control the generation of spatial locations. SpatialLock incorporates two components: Position-Engaged Injection (PoI) and Position-Guided Learning (PoG). PoI directly integrates spatial information through an attention layer, encouraging the model to learn the grounding information effectively. PoG employs perception-based supervision to further refine object localization. Together, these components enable the model to generate objects with precise spatial arrangements and improve the visual quality of the generated images. Experiments show that SpatialLock sets a new state-of-the-art for precise object positioning, achieving IOU scores above 0.9 across multiple datasets.
InterSyn: Interleaved Learning for Dynamic Motion Synthesis in the Wild
Aug 14, 2025We present Interleaved Learning for Motion Synthesis (InterSyn), a novel framework that targets the generation of realistic interaction motions by learning from integrated motions that consider both solo and multi-person dynamics. Unlike previous methods that treat these components separately, InterSyn employs an interleaved learning strategy to capture the natural, dynamic interactions and nuanced coordination inherent in real-world scenarios. Our framework comprises two key modules: the Interleaved Interaction Synthesis (INS) module, which jointly models solo and interactive behaviors in a unified paradigm from a first-person perspective to support multiple character interactions, and the Relative Coordination Refinement (REC) module, which refines mutual dynamics and ensures synchronized motions among characters. Experimental results show that the motion sequences generated by InterSyn exhibit higher text-to-motion alignment and improved diversity compared with recent methods, setting a new benchmark for robust and natural motion synthesis. Additionally, our code will be open-sourced in the future to promote further research and development in this area.
AI Flow: Perspectives, Scenarios, and Approaches
Jun 14, 2025Pioneered by the foundational information theory by Claude Shannon and the visionary framework of machine intelligence by Alan Turing, the convergent evolution of information and communication technologies (IT/CT) has created an unbroken wave of connectivity and computation. This synergy has sparked a technological revolution, now reaching its peak with large artificial intelligence (AI) models that are reshaping industries and redefining human-machine collaboration. However, the realization of ubiquitous intelligence faces considerable challenges due to substantial resource consumption in large models and high communication bandwidth demands. To address these challenges, AI Flow has been introduced as a multidisciplinary framework that integrates cutting-edge IT and CT advancements, with a particular emphasis on the following three key points. First, device-edge-cloud framework serves as the foundation, which integrates end devices, edge servers, and cloud clusters to optimize scalability and efficiency for low-latency model inference. Second, we introduce the concept of familial models, which refers to a series of different-sized models with aligned hidden features, enabling effective collaboration and the flexibility to adapt to varying resource constraints and dynamic scenarios. Third, connectivity- and interaction-based intelligence emergence is a novel paradigm of AI Flow. By leveraging communication networks to enhance connectivity, the collaboration among AI models across heterogeneous nodes achieves emergent intelligence that surpasses the capability of any single model. The innovations of AI Flow provide enhanced intelligence, timely responsiveness, and ubiquitous accessibility to AI services, paving the way for the tighter fusion of AI techniques and communication systems.