 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Video Compression: Towards 0.01% Compression Rate for Video Transmission
Dec 30, 2025Whether a video can be compressed at an extreme compression rate as low as 0.01%? To this end, we achieve the compression rate as 0.02% at some cases by introducing Generative Video Compression (GVC), a new framework that redefines the limits of video compression by leveraging modern generative video models to achieve extreme compression rates while preserving a perception-centric, task-oriented communication paradigm, corresponding to Level C of the Shannon-Weaver model. Besides, How we trade computation for compression rate or bandwidth? GVC answers this question by shifting the burden from transmission to inference: it encodes video into extremely compact representations and delegates content reconstruction to the receiver, where powerful generative priors synthesize high-quality video from minimal transmitted information. Is GVC practical and deployable? To ensure practical deployment, we propose a compression-computation trade-off strategy, enabling fast inference on consume-grade GPUs. Within the AI Flow framework, GVC opens new possibility for video communication in bandwidth- and resource-constrained environments such as emergency rescue, remote surveillance, and mobile edge computing. Through empirical validation, we demonstrate that GVC offers a viable path toward a new effective, efficient, scalable, and practical video communication paradigm.
UniForm: A Unified Diffusion Transformer for Audio-Video Generation
Feb 08, 2025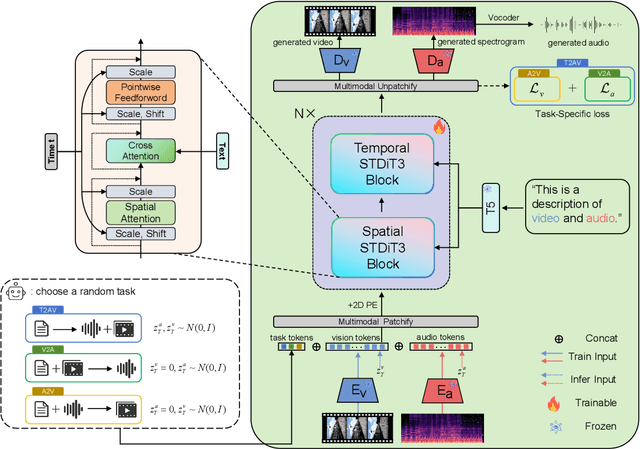
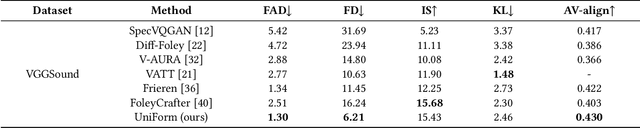
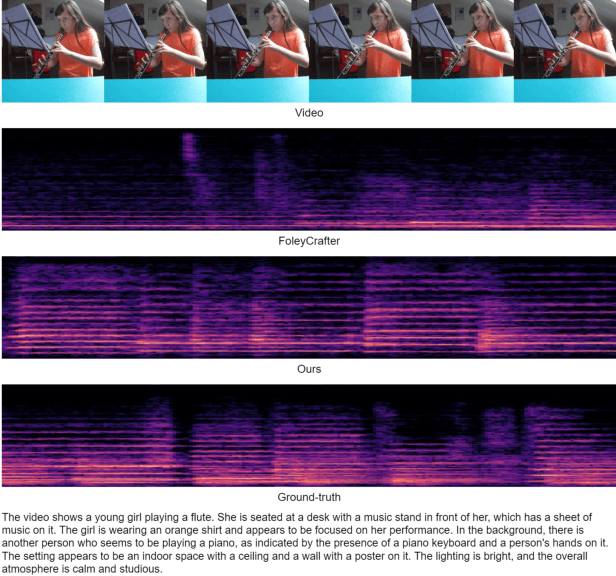

As a natural multimodal content, audible video delivers an immersive sensory experience. Consequently, audio-video generation systems have substantial potential. However, existing diffusion-based studies mainly employ relatively independent modules for generating each modality, which lack exploration of shared-weight generative modules. This approach may under-use the intrinsic correlations between audio and visual modalities, potentially resulting in sub-optimal generation quality. To address this, we propose UniForm, a unified diffusion transformer designed to enhance cross-modal consistency. By concatenating auditory and visual information, UniForm learns to generate audio and video simultaneously within a unified latent space, facilitating the creation of high-quality and well-aligned audio-visual pairs. Extensive experiments demonstrate the superior performance of our method in joint audio-video generation, audio-guided video generation, and video-guided audio generation tasks. Our demos are available at https://uniform-t2av.github.io/.
VAST 1.0: A Unified Framework for Controllable and Consistent Video Generation
Dec 21, 2024



Generating high-quality videos from textual descriptions poses challenges in maintaining temporal coherence and control over subject motion. We propose VAST (Video As Storyboard from Text), a two-stage framework to address these challenges and enable high-quality video generation. In the first stage, StoryForge transforms textual descriptions into detailed storyboards, capturing human poses and object layouts to represent the structural essence of the scene. In the second stage, VisionForge generates videos from these storyboards, producing high-quality videos with smooth motion, temporal consistency, and spatial coherence. By decoupling text understanding from video generation, VAST enables precise control over subject dynamics and scene composition. Experiments on the VBench benchmark demonstrate that VAST outperforms existing methods in both visual quality and semantic expression, setting a new standard for dynamic and coherent video generation.
ASFormer: Transformer for Action Segmentation
Oct 16, 2021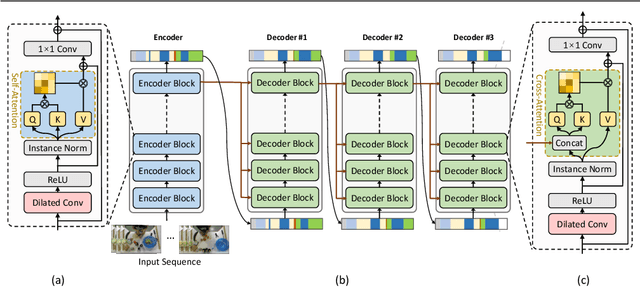


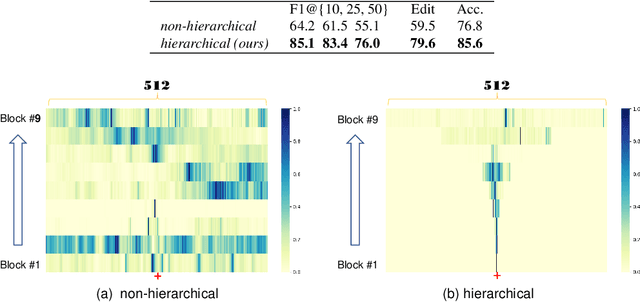
Algorithms for the action segmentation task typically use temporal models to predict what action is occurring at each frame for a minute-long daily activity. Recent studies have shown the potential of Transformer in modeling the relations among elements in sequential data. However, there are several major concerns when directly applying the Transformer to the action segmentation task, such as the lack of inductive biases with small training sets, the deficit in processing long input sequence, and the limitation of the decoder architecture to utilize temporal relations among multiple action segments to refine the initial predictions. To address these concerns, we design an efficient Transformer-based model for action segmentation task, named ASFormer, with three distinctive characteristics: (i) We explicitly bring in the local connectivity inductive priors because of the high locality of features. It constrains the hypothesis space within a reliable scope, and is beneficial for the action segmentation task to learn a proper target function with small training sets. (ii) We apply a pre-defined hierarchical representation pattern that efficiently handles long input sequences. (iii) We carefully design the decoder to refine the initial predictions from the encoder. Extensive experiments on three public datasets demonstrate that effectiveness of our methods. Code is available at \url{https://github.com/ChinaYi/ASFormer}.
Not End-to-End: Explore Multi-Stage Architecture for Online Surgical Phase Recognition
Jul 10, 2021



Surgical phase recognition is of particular interest to computer assisted surgery systems, in which the goal is to predict what phase is occurring at each frame for a surgery video. Networks with multi-stage architecture have been widely applied in many computer vision tasks with rich patterns, where a predictor stage first outputs initial predictions and an additional refinement stage operates on the initial predictions to perform further refinement. Existing works show that surgical video contents are well ordered and contain rich temporal patterns, making the multi-stage architecture well suited for the surgical phase recognition task. However, we observe that when simply applying the multi-stage architecture to the surgical phase recognition task, the end-to-end training manner will make the refinement ability fall short of its wishes. To address the problem, we propose a new non end-to-end training strategy and explore different designs of multi-stage architecture for surgical phase recognition task. For the non end-to-end training strategy, the refinement stage is trained separately with proposed two types of disturbed sequences. Meanwhile, we evaluate three different choices of refinement models to show that our analysis and solution are robust to the choices of specific multi-stage models. We conduct experiments on two public benchmarks, the M2CAI16 Workflow Challenge, and the Cholec80 dataset. Results show that multi-stage architecture trained with our strategy largely boosts the performance of the current state-of-the-art single-stage model. Code is available at \url{https://github.com/ChinaYi/casual_tcn}.