 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniForm: A Unified Diffusion Transformer for Audio-Video Generation
Paper and Code
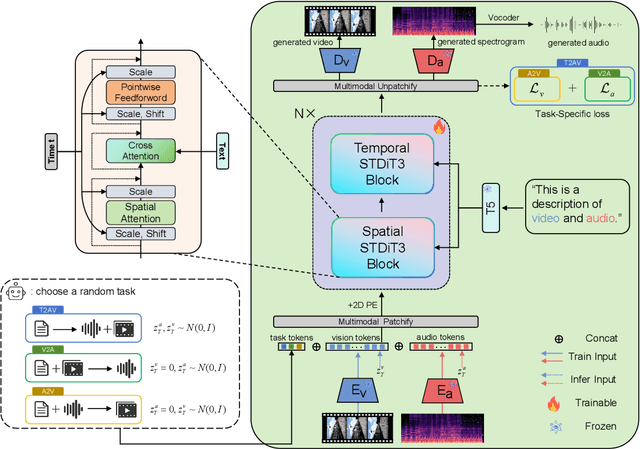
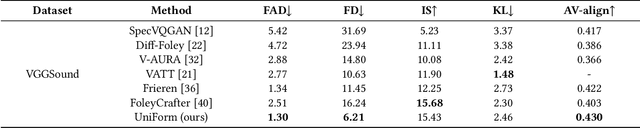
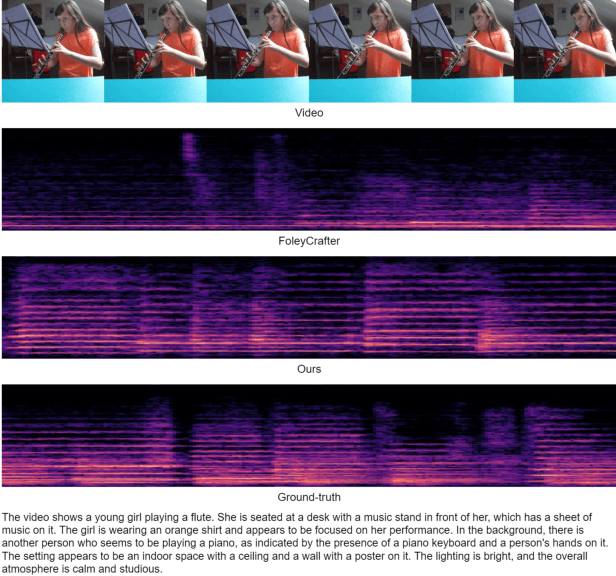

As a natural multimodal content, audible video delivers an immersive sensory experience. Consequently, audio-video generation systems have substantial potential. However, existing diffusion-based studies mainly employ relatively independent modules for generating each modality, which lack exploration of shared-weight generative modules. This approach may under-use the intrinsic correlations between audio and visual modalities, potentially resulting in sub-optimal generation quality. To address this, we propose UniForm, a unified diffusion transformer designed to enhance cross-modal consistency. By concatenating auditory and visual information, UniForm learns to generate audio and video simultaneously within a unified latent space, facilitating the creation of high-quality and well-aligned audio-visual pairs. Extensive experiments demonstrate the superior performance of our method in joint audio-video generation, audio-guided video generation, and video-guided audio generation tasks. Our demos are available at https://uniform-t2av.github.io/.