 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVDiff: Omni Controllable Video Diffusion for Generation and Understanding
Apr 15, 2025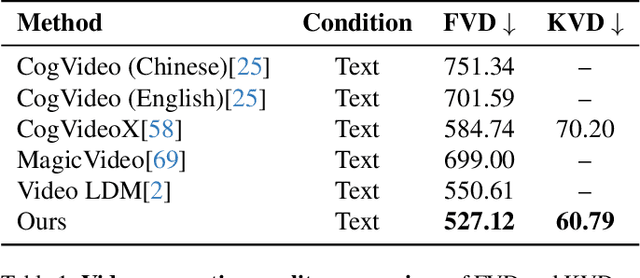
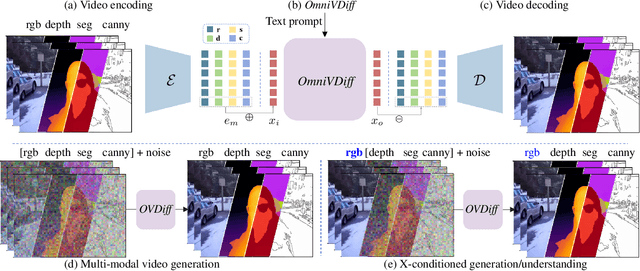
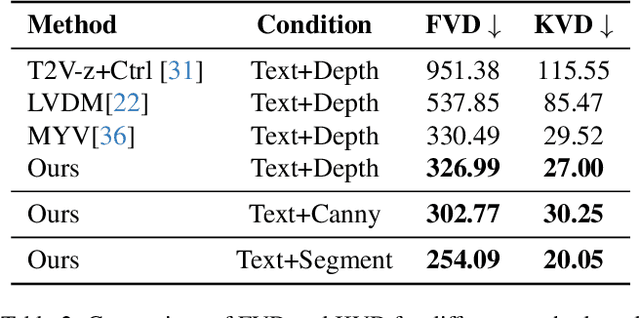

In this paper, we propose a novel framework for controllable video diffusion, OmniVDiff, aiming to synthesize and comprehend multiple video visual content in a single diffusion model. To achieve this, OmniVDiff treats all video visual modalities in the color space to learn a joint distribution, while employing an adaptive control strategy that dynamically adjusts the role of each visual modality during the diffusion process, either as a generation modality or a conditioning modality. This allows flexible manipulation of each modality's role, enabling support for a wide range of tasks. Consequently, our model supports three key functionalities: (1) Text-conditioned video generation: multi-modal visual video sequences (i.e., rgb, depth, canny, segmentaion) are generated based on the text conditions in one diffusion process; (2) Video understanding: OmniVDiff can estimate the depth, canny map, and semantic segmentation across the input rgb frames while ensuring coherence with the rgb input; and (3) X-conditioned video generation: OmniVDiff generates videos conditioned on fine-grained attributes (e.g., depth maps or segmentation maps). By integrating these diverse tasks into a unified video diffusion framework, OmniVDiff enhances the flexibility and scalability for controllable video diffusion, making it an effective tool for a variety of downstream applications, such as video-to-video translation. Extensive experiments demonstrate the effectiveness of our approach, highlighting its potential for various video-related applications.
NFIG: Autoregressive Image Generation with Next-Frequency Prediction
Mar 10, 2025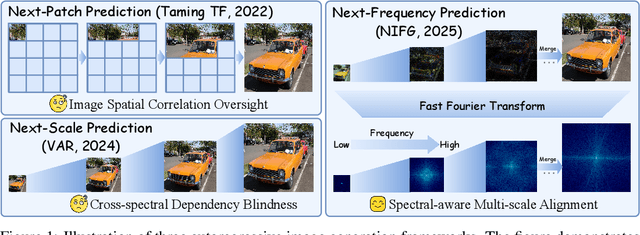

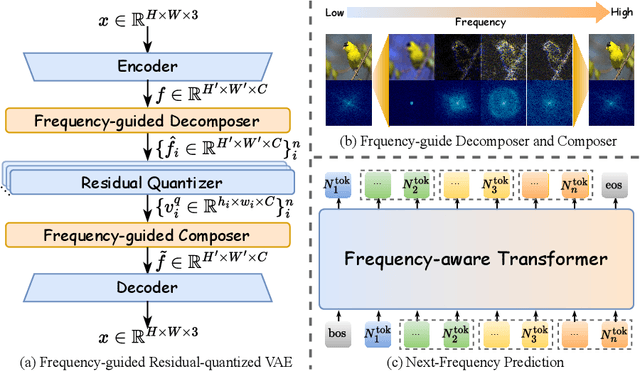
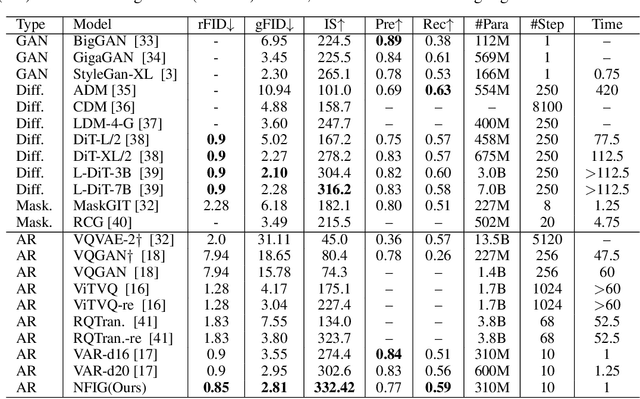
Autoregressive models have achieved promising results in natural language processing. However, for image generation tasks, they encounter substantial challenges in effectively capturing long-range dependencies, managing computational costs, and most crucially, defining meaningful autoregressive sequences that reflect natural image hierarchies. To address these issues, we present \textbf{N}ext-\textbf{F}requency \textbf{I}mage \textbf{G}eneration (\textbf{NFIG}), a novel framework that decomposes the image generation process into multiple frequency-guided stages. Our approach first generates low-frequency components to establish global structure with fewer tokens, then progressively adds higher-frequency details, following the natural spectral hierarchy of images. This principled autoregressive sequence not only improves the quality of generated images by better capturing true causal relationships between image components, but also significantly reduces computational overhead during inference. Extensive experiments demonstrate that NFIG achieves state-of-the-art performance with fewer steps, offering a more efficient solution for image generation, with 1.25$\times$ speedup compared to VAR-d20 while achieving better performance (FID: 2.81) on the ImageNet-256 benchmark. We hope that our insight of incorporating frequency-domain knowledge to guide autoregressive sequence design will shed light on future research. We will make our code publicly available upon acceptance of the paper.
VAST 1.0: A Unified Framework for Controllable and Consistent Video Generation
Dec 21, 2024



Generating high-quality videos from textual descriptions poses challenges in maintaining temporal coherence and control over subject motion. We propose VAST (Video As Storyboard from Text), a two-stage framework to address these challenges and enable high-quality video generation. In the first stage, StoryForge transforms textual descriptions into detailed storyboards, capturing human poses and object layouts to represent the structural essence of the scene. In the second stage, VisionForge generates videos from these storyboards, producing high-quality videos with smooth motion, temporal consistency, and spatial coherence. By decoupling text understanding from video generation, VAST enables precise control over subject dynamics and scene composition. Experiments on the VBench benchmark demonstrate that VAST outperforms existing methods in both visual quality and semantic expression, setting a new standard for dynamic and coherent video generation.
M${^2}$Depth: Self-supervised Two-Frame Multi-camera Metric Depth Estimation
May 03, 2024
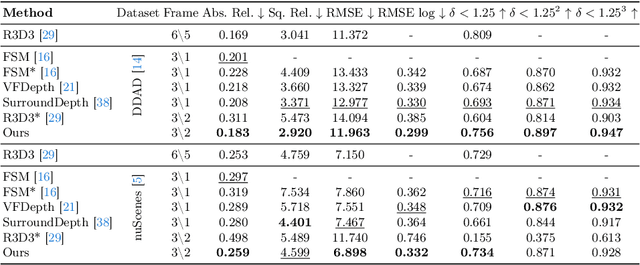
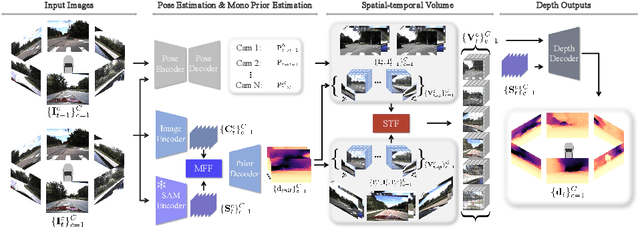
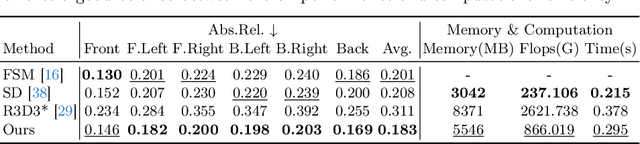
This paper presents a novel self-supervised two-frame multi-camera metric depth estimation network, termed M${^2}$Depth, which is designed to predict reliable scale-aware surrounding depth in autonomous driving. Unlike the previous works that use multi-view images from a single time-step or multiple time-step images from a single camera, M${^2}$Depth takes temporally adjacent two-frame images from multiple cameras as inputs and produces high-quality surrounding depth. We first construct cost volumes in spatial and temporal domains individually and propose a spatial-temporal fusion module that integrates the spatial-temporal information to yield a strong volume presentation. We additionally combine the neural prior from SAM features with internal features to reduce the ambiguity between foreground and background and strengthen the depth edges. Extensive experimental results on nuScenes and DDAD benchmarks show M${^2}$Depth achieves state-of-the-art performance. More results can be found in https://heiheishuang.xyz/M2Depth .
PivotNet: Vectorized Pivot Learning for End-to-end HD Map Construction
Sep 01, 2023Vectorized high-definition map online construction has garnered considerable attention in the field of autonomous driving research. Most existing approaches model changeable map elements using a fixed number of points, or predict local maps in a two-stage autoregressive manner, which may miss essential details and lead to error accumulation. Towards precise map element learning, we propose a simple yet effective architecture named PivotNet, which adopts unified pivot-based map representations and is formulated as a direct set prediction paradigm. Concretely, we first propose a novel point-to-line mask module to encode both the subordinate and geometrical point-line priors in the network. Then, a well-designed pivot dynamic matching module is proposed to model the topology in dynamic point sequences by introducing the concept of sequence matching. Furthermore, to supervise the position and topology of the vectorized point predictions, we propose a dynamic vectorized sequence loss. Extensive experiments and ablations show that PivotNet is remarkably superior to other SOTAs by 5.9 mAP at least. The code will be available soon.
MachMap: End-to-End Vectorized Solution for Compact HD-Map Construction
Jun 17, 2023This report introduces the 1st place winning solution for the Autonomous Driving Challenge 2023 - Online HD-map Construction. By delving into the vectorization pipeline, we elaborate an effective architecture, termed as MachMap, which formulates the task of HD-map construction as the point detection paradigm in the bird-eye-view space with an end-to-end manner. Firstly, we introduce a novel map-compaction scheme into our framework, leading to reducing the number of vectorized points by 93% without any expression performance degradation. Build upon the above process, we then follow the general query-based paradigm and propose a strong baseline with integrating a powerful CNN-based backbone like InternImage, a temporal-based instance decoder and a well-designed point-mask coupling head. Additionally, an extra optional ensemble stage is utilized to refine model predictions for better performance. Our MachMap-tiny with IN-1K initialization achieves a mAP of 79.1 on the Argoverse2 benchmark and the further improved MachMap-huge reaches the best mAP of 83.5, outperforming all the other online HD-map construction approaches on the final leaderboard with a distinct performance margin (> 9.8 mAP at least).
End-to-End Vectorized HD-map Construction with Piecewise Bezier Curve
Jun 16, 2023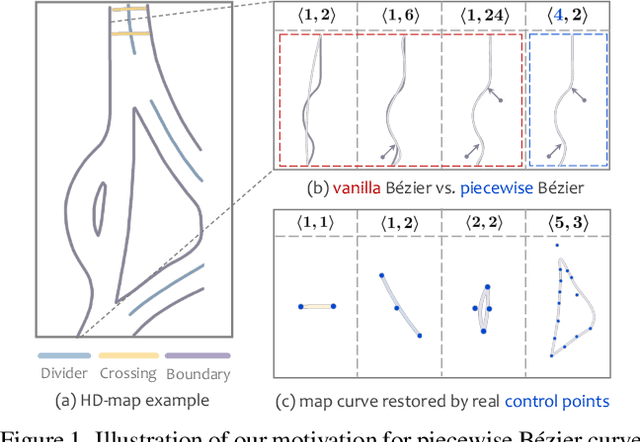
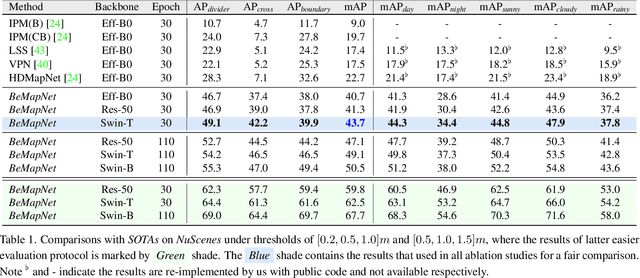
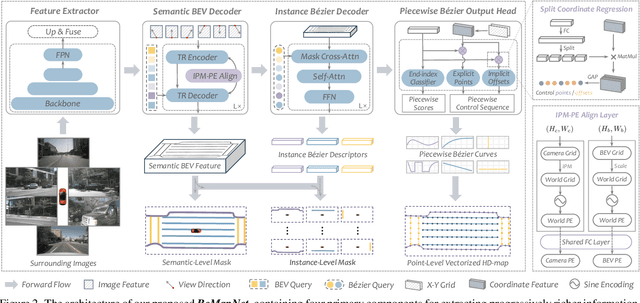
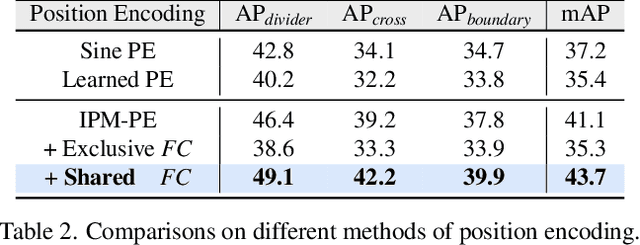
Vectorized high-definition map (HD-map) construction, which focuses on the perception of centimeter-level environmental information, has attracted significant research interest in the autonomous driving community. Most existing approaches first obtain rasterized map with the segmentation-based pipeline and then conduct heavy post-processing for downstream-friendly vectorization. In this paper, by delving into parameterization-based methods, we pioneer a concise and elegant scheme that adopts unified piecewise Bezier curve. In order to vectorize changeful map elements end-to-end, we elaborate a simple yet effective architecture, named Piecewise Bezier HD-map Network (BeMapNet), which is formulated as a direct set prediction paradigm and postprocessing-free. Concretely, we first introduce a novel IPM-PE Align module to inject 3D geometry prior into BEV features through common position encoding in Transformer. Then a well-designed Piecewise Bezier Head is proposed to output the details of each map element, including the coordinate of control points and the segment number of curves. In addition, based on the progressively restoration of Bezier curve, we also present an efficient Point-Curve-Region Loss for supervising more robust and precise HD-map modeling. Extensive comparisons show that our method is remarkably superior to other existing SOTAs by 18.0 mAP at least.
GRM: Gradient Rectification Module for Visual Place Retrieval
Apr 23, 2022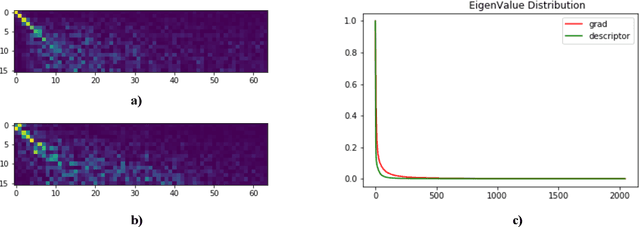
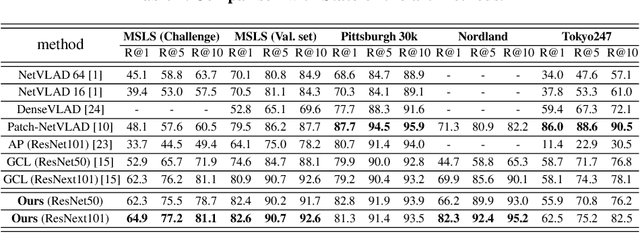
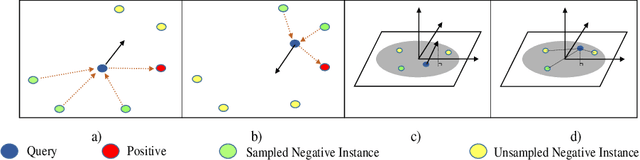
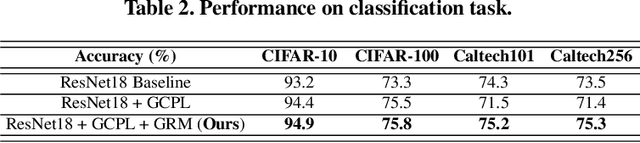
Visual place retrieval aims to search images in the database that depict similar places as the query image. However, global descriptors encoded by the network usually fall into a low dimensional principal space, which is harmful to the retrieval performance. We first analyze the cause of this phenomenon, pointing out that it is due to degraded distribution of the gradients of descriptors. Then, a new module called Gradient Rectification Module(GRM) is proposed to alleviate this issue. It can be appended after the final pooling layer. This module can rectify the gradients to the complement space of the principal space. Therefore, the network is encouraged to generate descriptors more uniformly in the whole space. At last, we conduct experiments on multiple datasets and generalize our method to classification task under prototype learning framework.
Binocular Mutual Learning for Improving Few-shot Classification
Aug 27, 2021
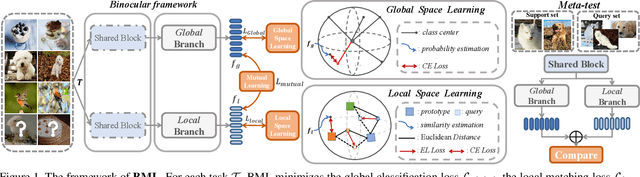
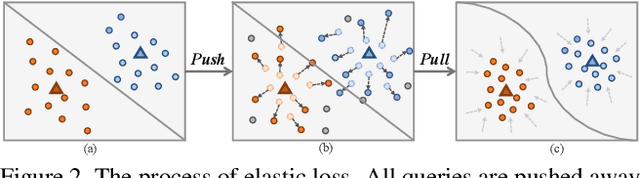
Most of the few-shot learning methods learn to transfer knowledge from datasets with abundant labeled data (i.e., the base set). From the perspective of class space on base set, existing methods either focus on utilizing all classes under a global view by normal pretraining, or pay more attention to adopt an episodic manner to train meta-tasks within few classes in a local view. However, the interaction of the two views is rarely explored. As the two views capture complementary information, we naturally think of the compatibility of them for achieving further performance gains. Inspired by the mutual learning paradigm and binocular parallax, we propose a unified framework, namely Binocular Mutual Learning (BML), which achieves the compatibility of the global view and the local view through both intra-view and cross-view modeling. Concretely, the global view learns in the whole class space to capture rich inter-class relationships. Meanwhile, the local view learns in the local class space within each episode, focusing on matching positive pairs correctly. In addition, cross-view mutual interaction further promotes the collaborative learning and the implicit exploration of useful knowledge from each other. During meta-test, binocular embeddings are aggregated together to support decision-making, which greatly improve the accuracy of classification. Extensive experiments conducted on multiple benchmarks including cross-domain validation confirm the effectiveness of our method.
DeFRCN: Decoupled Faster R-CNN for Few-Shot Object Detection
Aug 20, 2021

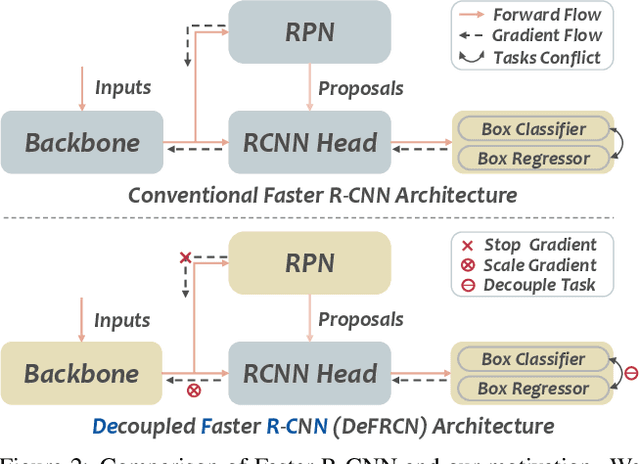
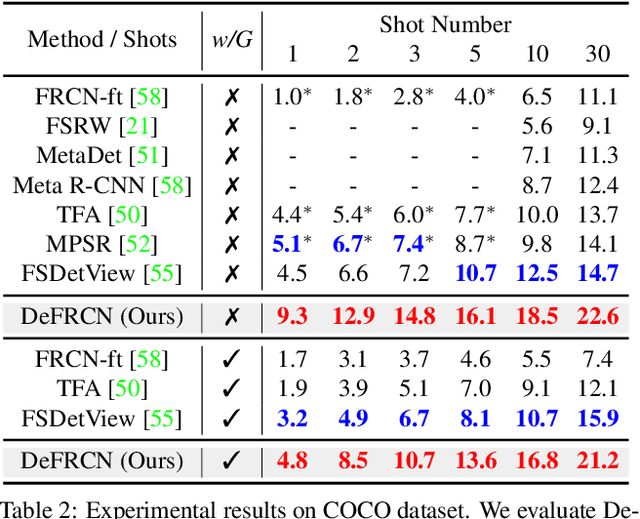
Few-shot object detection, which aims at detecting novel objects rapidly from extremely few annotated examples of previously unseen classes, has attracted significant research interest in the community. Most existing approaches employ the Faster R-CNN as basic detection framework, yet, due to the lack of tailored considerations for data-scarce scenario, their performance is often not satisfactory. In this paper, we look closely into the conventional Faster R-CNN and analyze its contradictions from two orthogonal perspectives, namely multi-stage (RPN vs. RCNN) and multi-task (classification vs. localization). To resolve these issues, we propose a simple yet effective architecture, named Decoupled Faster R-CNN (DeFRCN). To be concrete, we extend Faster R-CNN by introducing Gradient Decoupled Layer for multi-stage decoupling and Prototypical Calibration Block for multi-task decoupling. The former is a novel deep layer with redefining the feature-forward operation and gradient-backward operation for decoupling its subsequent layer and preceding layer, and the latter is an offline prototype-based classification model with taking the proposals from detector as input and boosting the original classification scores with additional pairwise scores for calibration. Extensive experiments on multiple benchmarks show our framework is remarkably superior to other existing approaches and establishes a new state-of-the-art in few-shot literature.