 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language-Action Understanding and Generation for Autonomous Driving
Mar 02, 2026Vision-Language-Action (VLA) models are emerging as a promising paradigm for end-to-end autonomous driving, valued for their potential to leverage world knowledge and reason about complex driving scenes. However, existing methods suffer from two critical limitations: a persistent misalignment between language instructions and action outputs, and the inherent inefficiency of typical auto-regressive action generation. In this paper, we introduce LinkVLA, a novel architecture that directly addresses these challenges to enhance both alignment and efficiency. First, we establish a structural link by unifying language and action tokens into a shared discrete codebook, processed within a single multi-modal model. This structurally enforces cross-modal consistency from the ground up. Second, to create a deep semantic link, we introduce an auxiliary action understanding objective that trains the model to generate descriptive captions from trajectories, fostering a bidirectional language-action mapping. Finally, we replace the slow, step-by-step generation with a two-step coarse-to-fine generation method C2F that efficiently decodes the action sequence, saving 86% inference time. Experiments on closed-loop driving benchmarks show consistent gains in instruction following accuracy and driving performance, alongside reduced inference latency.
PivotNet: Vectorized Pivot Learning for End-to-end HD Map Construction
Sep 01, 2023Vectorized high-definition map online construction has garnered considerable attention in the field of autonomous driving research. Most existing approaches model changeable map elements using a fixed number of points, or predict local maps in a two-stage autoregressive manner, which may miss essential details and lead to error accumulation. Towards precise map element learning, we propose a simple yet effective architecture named PivotNet, which adopts unified pivot-based map representations and is formulated as a direct set prediction paradigm. Concretely, we first propose a novel point-to-line mask module to encode both the subordinate and geometrical point-line priors in the network. Then, a well-designed pivot dynamic matching module is proposed to model the topology in dynamic point sequences by introducing the concept of sequence matching. Furthermore, to supervise the position and topology of the vectorized point predictions, we propose a dynamic vectorized sequence loss. Extensive experiments and ablations show that PivotNet is remarkably superior to other SOTAs by 5.9 mAP at least. The code will be available soon.
MachMap: End-to-End Vectorized Solution for Compact HD-Map Construction
Jun 17, 2023This report introduces the 1st place winning solution for the Autonomous Driving Challenge 2023 - Online HD-map Construction. By delving into the vectorization pipeline, we elaborate an effective architecture, termed as MachMap, which formulates the task of HD-map construction as the point detection paradigm in the bird-eye-view space with an end-to-end manner. Firstly, we introduce a novel map-compaction scheme into our framework, leading to reducing the number of vectorized points by 93% without any expression performance degradation. Build upon the above process, we then follow the general query-based paradigm and propose a strong baseline with integrating a powerful CNN-based backbone like InternImage, a temporal-based instance decoder and a well-designed point-mask coupling head. Additionally, an extra optional ensemble stage is utilized to refine model predictions for better performance. Our MachMap-tiny with IN-1K initialization achieves a mAP of 79.1 on the Argoverse2 benchmark and the further improved MachMap-huge reaches the best mAP of 83.5, outperforming all the other online HD-map construction approaches on the final leaderboard with a distinct performance margin (> 9.8 mAP at least).
End-to-End Vectorized HD-map Construction with Piecewise Bezier Curve
Jun 16, 2023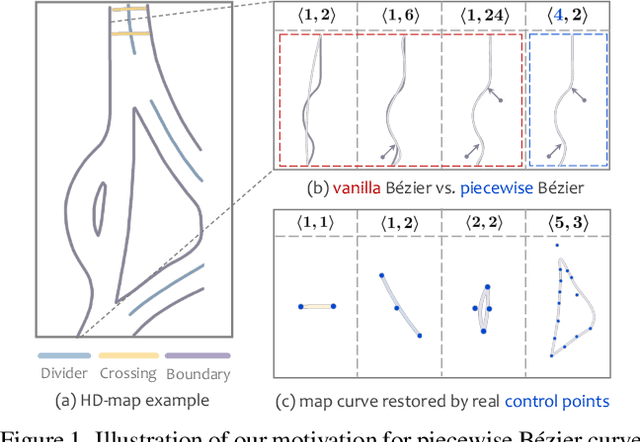
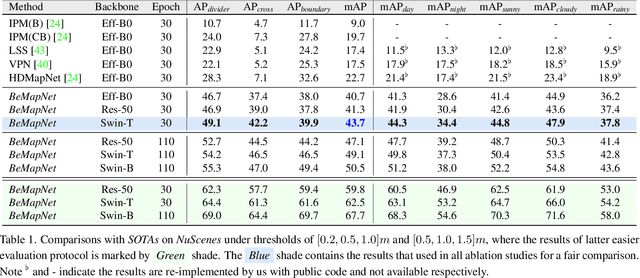
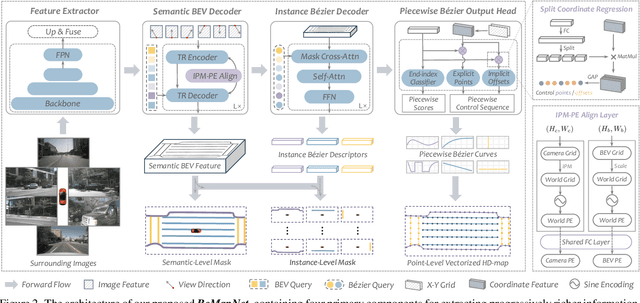
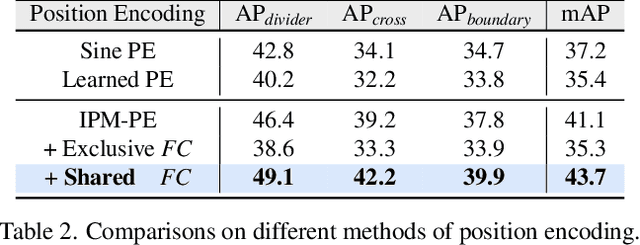
Vectorized high-definition map (HD-map) construction, which focuses on the perception of centimeter-level environmental information, has attracted significant research interest in the autonomous driving community. Most existing approaches first obtain rasterized map with the segmentation-based pipeline and then conduct heavy post-processing for downstream-friendly vectorization. In this paper, by delving into parameterization-based methods, we pioneer a concise and elegant scheme that adopts unified piecewise Bezier curve. In order to vectorize changeful map elements end-to-end, we elaborate a simple yet effective architecture, named Piecewise Bezier HD-map Network (BeMapNet), which is formulated as a direct set prediction paradigm and postprocessing-free. Concretely, we first introduce a novel IPM-PE Align module to inject 3D geometry prior into BEV features through common position encoding in Transformer. Then a well-designed Piecewise Bezier Head is proposed to output the details of each map element, including the coordinate of control points and the segment number of curves. In addition, based on the progressively restoration of Bezier curve, we also present an efficient Point-Curve-Region Loss for supervising more robust and precise HD-map modeling. Extensive comparisons show that our method is remarkably superior to other existing SOTAs by 18.0 mAP at least.
GRM: Gradient Rectification Module for Visual Place Retrieval
Apr 23, 2022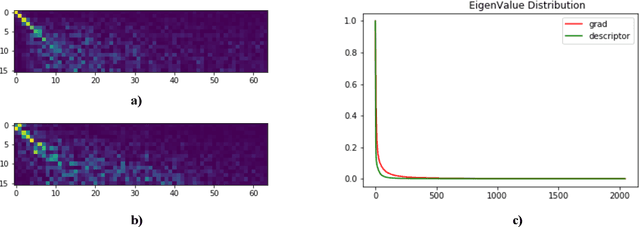
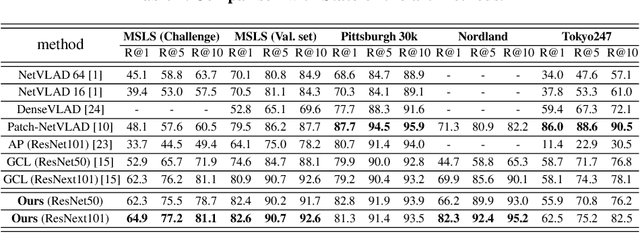
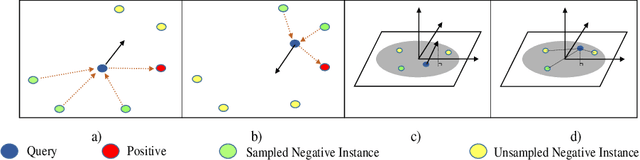
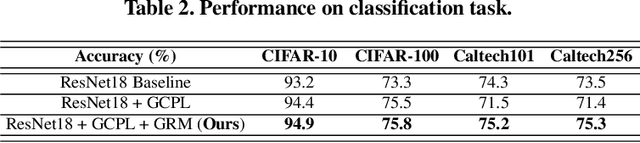
Visual place retrieval aims to search images in the database that depict similar places as the query image. However, global descriptors encoded by the network usually fall into a low dimensional principal space, which is harmful to the retrieval performance. We first analyze the cause of this phenomenon, pointing out that it is due to degraded distribution of the gradients of descriptors. Then, a new module called Gradient Rectification Module(GRM) is proposed to alleviate this issue. It can be appended after the final pooling layer. This module can rectify the gradients to the complement space of the principal space. Therefore, the network is encouraged to generate descriptors more uniformly in the whole space. At last, we conduct experiments on multiple datasets and generalize our method to classification task under prototype learning framework.
Universal Adversarial Perturbations Against Person Re-Identification
Oct 30, 2019
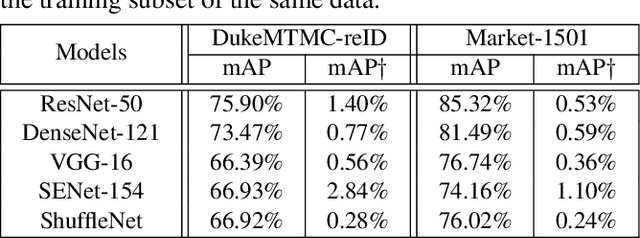

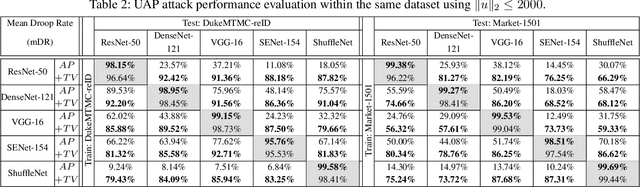
Person re-identification (re-ID) has made great progress and achieved high performance in recent years with the development of deep learning. However, as an application related to security issues, there are few researches considering the safety of person re-ID systems. In this paper, we attempt to explore the robustness of current person re-ID models against adversarial samples. Specifically, we attack the re-ID models using universal adversarial perturbations (UAPs), which are especially dangerous to the surveillance systems because it could fool most pedestrian images with a little overhead. Existing methods for UAPs mainly consider classification models, while the tasks in open set scenarios like re-ID are rarely explored. Re-ID attack is different from classification ones in the sense that the former discards decision boundary during test and cares more about the ranking list. Therefore, we propose an effective method to train UAPs against person re-ID models from the global list-wise perspective. Furthermore, to increase the impact of attack to different models and datasets, we propose a novel UAPs learning method based on total variation minimization. Extensive experiments validate the effectiveness of our proposed method.