 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoAlign: Geometric Feature Realignment for MLLM Spatial Reasoning
Apr 14, 2026Multimodal large language models (MLLMs) have exhibited remarkable performance in various visual tasks, yet still struggle with spatial reasoning. Recent efforts mitigate this by injecting geometric features from 3D foundation models, but rely on static single-layer extractions. We identify that such an approach induces a task misalignment bias: the geometric features naturally evolve towards 3D pretraining objectives, which may contradict the heterogeneous spatial demands of MLLMs, rendering any single layer fundamentally insufficient. To resolve this, we propose GeoAlign, a novel framework that dynamically aggregates multi-layer geometric features to realign with the actual demands. GeoAlign constructs a hierarchical geometric feature bank and leverages the MLLM's original visual tokens as content-aware queries to perform layer-wise sparse routing, adaptively fetching the suitable geometric features for each patch. Extensive experiments on VSI-Bench, ScanQA, and SQA3D demonstrate that our compact 4B model effectively achieves state-of-the-art performance, even outperforming larger existing MLLMs.
STAR: STacked AutoRegressive Scheme for Unified Multimodal Learning
Dec 15, 2025
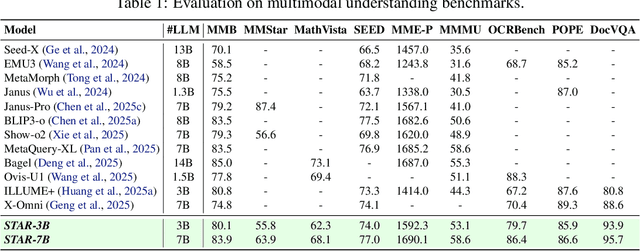
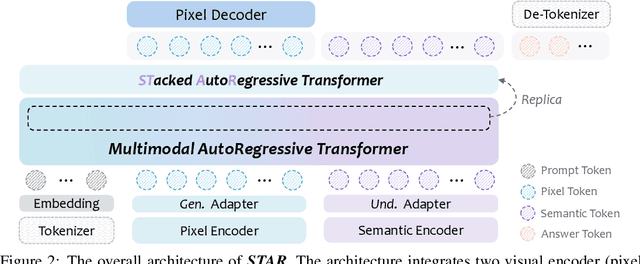
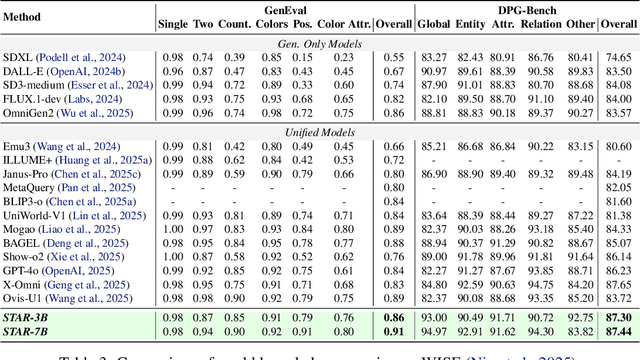
Multimodal large language models (MLLMs) play a pivotal role in advancing the quest for general artificial intelligence. However, achieving unified target for multimodal understanding and generation remains challenging due to optimization conflicts and performance trade-offs. To effectively enhance generative performance while preserving existing comprehension capabilities, we introduce STAR: a STacked AutoRegressive scheme for task-progressive unified multimodal learning. This approach decomposes multimodal learning into multiple stages: understanding, generation, and editing. By freezing the parameters of the fundamental autoregressive (AR) model and progressively stacking isomorphic AR modules, it avoids cross-task interference while expanding the model's capabilities. Concurrently, we introduce a high-capacity VQ to enhance the granularity of image representations and employ an implicit reasoning mechanism to improve generation quality under complex conditions. Experiments demonstrate that STAR achieves state-of-the-art performance on GenEval (0.91), DPG-Bench (87.44), and ImgEdit (4.34), validating its efficacy for unified multimodal learning.
X-SAM: From Segment Anything to Any Segmentation
Aug 06, 2025Large Language Models (LLMs) demonstrate strong capabilities in broad knowledge representation, yet they are inherently deficient in pixel-level perceptual understanding. Although the Segment Anything Model (SAM) represents a significant advancement in visual-prompt-driven image segmentation, it exhibits notable limitations in multi-mask prediction and category-specific segmentation tasks, and it cannot integrate all segmentation tasks within a unified model architecture. To address these limitations, we present X-SAM, a streamlined Multimodal Large Language Model (MLLM) framework that extends the segmentation paradigm from \textit{segment anything} to \textit{any segmentation}. Specifically, we introduce a novel unified framework that enables more advanced pixel-level perceptual comprehension for MLLMs. Furthermore, we propose a new segmentation task, termed Visual GrounDed (VGD) segmentation, which segments all instance objects with interactive visual prompts and empowers MLLMs with visual grounded, pixel-wise interpretative capabilities. To enable effective training on diverse data sources, we present a unified training strategy that supports co-training across multiple datasets. Experimental results demonstrate that X-SAM achieves state-of-the-art performance on a wide range of image segmentation benchmarks, highlighting its efficiency for multimodal, pixel-level visual understanding. Code is available at https://github.com/wanghao9610/X-SAM.
Beyond the Visible: Benchmarking Occlusion Perception in Multimodal Large Language Models
Aug 06, 2025Occlusion perception, a critical foundation for human-level spatial understanding, embodies the challenge of integrating visual recognition and reasoning. Though multimodal large language models (MLLMs) have demonstrated remarkable capabilities, their performance on occlusion perception remains under-explored. To address this gap, we introduce O-Bench, the first visual question answering (VQA) benchmark specifically designed for occlusion perception. Based on SA-1B, we construct 1,365 images featuring semantically coherent occlusion scenarios through a novel layered synthesis approach. Upon this foundation, we annotate 4,588 question-answer pairs in total across five tailored tasks, employing a reliable, semi-automatic workflow. Our extensive evaluation of 22 representative MLLMs against the human baseline reveals a significant performance gap between current MLLMs and humans, which, we find, cannot be sufficiently bridged by model scaling or thinking process. We further identify three typical failure patterns, including an overly conservative bias, a fragile gestalt prediction, and a struggle with quantitative tasks. We believe O-Bench can not only provide a vital evaluation tool for occlusion perception, but also inspire the development of MLLMs for better visual intelligence. Our benchmark will be made publicly available upon paper publication.
UniViTAR: Unified Vision Transformer with Native Resolution
Apr 02, 2025Conventional Vision Transformer simplifies visual modeling by standardizing input resolutions, often disregarding the variability of natural visual data and compromising spatial-contextual fidelity. While preliminary explorations have superficially investigated native resolution modeling, existing approaches still lack systematic analysis from a visual representation perspective. To bridge this gap, we introduce UniViTAR, a family of homogeneous vision foundation models tailored for unified visual modality and native resolution scenario in the era of multimodal. Our framework first conducts architectural upgrades to the vanilla paradigm by integrating multiple advanced components. Building upon these improvements, a progressive training paradigm is introduced, which strategically combines two core mechanisms: (1) resolution curriculum learning, transitioning from fixed-resolution pretraining to native resolution tuning, thereby leveraging ViT's inherent adaptability to variable-length sequences, and (2) visual modality adaptation via inter-batch image-video switching, which balances computational efficiency with enhanced temporal reasoning. In parallel, a hybrid training framework further synergizes sigmoid-based contrastive loss with feature distillation from a frozen teacher model, thereby accelerating early-stage convergence. Finally, trained exclusively on public datasets, externsive experiments across multiple model scales from 0.3B to 1B demonstrate its effectiveness.
PLUG: Revisiting Amodal Segmentation with Foundation Model and Hierarchical Focus
May 25, 2024



Aiming to predict the complete shapes of partially occluded objects, amodal segmentation is an important step towards visual intelligence. With crucial significance, practical prior knowledge derives from sufficient training, while limited amodal annotations pose challenges to achieve better performance. To tackle this problem, utilizing the mighty priors accumulated in the foundation model, we propose the first SAM-based amodal segmentation approach, PLUG. Methodologically, a novel framework with hierarchical focus is presented to better adapt the task characteristics and unleash the potential capabilities of SAM. In the region level, due to the association and division in visible and occluded areas, inmodal and amodal regions are assigned as the focuses of distinct branches to avoid mutual disturbance. In the point level, we introduce the concept of uncertainty to explicitly assist the model in identifying and focusing on ambiguous points. Guided by the uncertainty map, a computation-economic point loss is applied to improve the accuracy of predicted boundaries. Experiments are conducted on several prominent datasets, and the results show that our proposed method outperforms existing methods with large margins. Even with fewer total parameters, our method still exhibits remarkable advantages.
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Feb 06, 2024We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
MobileVLM : A Fast, Strong and Open Vision Language Assistant for Mobile Devices
Dec 30, 2023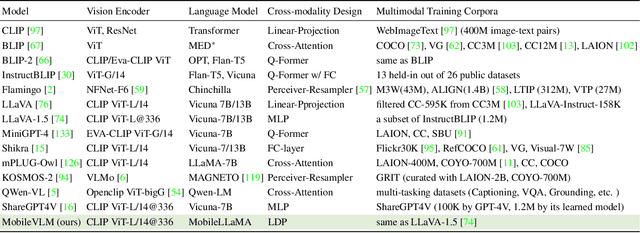
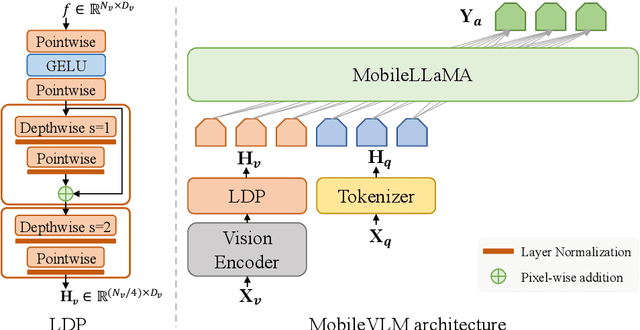
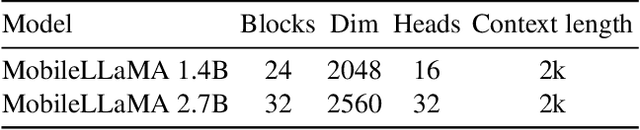
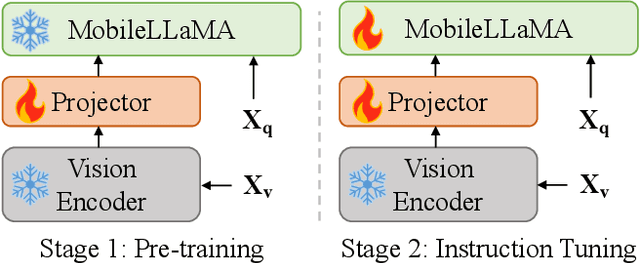
We present MobileVLM, a competent multimodal vision language model (MMVLM) targeted to run on mobile devices. It is an amalgamation of a myriad of architectural designs and techniques that are mobile-oriented, which comprises a set of language models at the scale of 1.4B and 2.7B parameters, trained from scratch, a multimodal vision model that is pre-trained in the CLIP fashion, cross-modality interaction via an efficient projector. We evaluate MobileVLM on several typical VLM benchmarks. Our models demonstrate on par performance compared with a few much larger models. More importantly, we measure the inference speed on both a Qualcomm Snapdragon 888 CPU and an NVIDIA Jeston Orin GPU, and we obtain state-of-the-art performance of 21.5 tokens and 65.3 tokens per second, respectively. Our code will be made available at: https://github.com/Meituan-AutoML/MobileVLM.
PivotNet: Vectorized Pivot Learning for End-to-end HD Map Construction
Sep 01, 2023Vectorized high-definition map online construction has garnered considerable attention in the field of autonomous driving research. Most existing approaches model changeable map elements using a fixed number of points, or predict local maps in a two-stage autoregressive manner, which may miss essential details and lead to error accumulation. Towards precise map element learning, we propose a simple yet effective architecture named PivotNet, which adopts unified pivot-based map representations and is formulated as a direct set prediction paradigm. Concretely, we first propose a novel point-to-line mask module to encode both the subordinate and geometrical point-line priors in the network. Then, a well-designed pivot dynamic matching module is proposed to model the topology in dynamic point sequences by introducing the concept of sequence matching. Furthermore, to supervise the position and topology of the vectorized point predictions, we propose a dynamic vectorized sequence loss. Extensive experiments and ablations show that PivotNet is remarkably superior to other SOTAs by 5.9 mAP at least. The code will be available soon.
MachMap: End-to-End Vectorized Solution for Compact HD-Map Construction
Jun 17, 2023This report introduces the 1st place winning solution for the Autonomous Driving Challenge 2023 - Online HD-map Construction. By delving into the vectorization pipeline, we elaborate an effective architecture, termed as MachMap, which formulates the task of HD-map construction as the point detection paradigm in the bird-eye-view space with an end-to-end manner. Firstly, we introduce a novel map-compaction scheme into our framework, leading to reducing the number of vectorized points by 93% without any expression performance degradation. Build upon the above process, we then follow the general query-based paradigm and propose a strong baseline with integrating a powerful CNN-based backbone like InternImage, a temporal-based instance decoder and a well-designed point-mask coupling head. Additionally, an extra optional ensemble stage is utilized to refine model predictions for better performance. Our MachMap-tiny with IN-1K initialization achieves a mAP of 79.1 on the Argoverse2 benchmark and the further improved MachMap-huge reaches the best mAP of 83.5, outperforming all the other online HD-map construction approaches on the final leaderboard with a distinct performance margin (> 9.8 mAP at least).