 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeisFusion: Constrained Diffusion Model with Input Guidance for 3D Seismic Data Interpolation and Reconstruction
Mar 18, 2024Geographical, physical, or economic constraints often result in missing traces within seismic data, making the reconstruction of complete seismic data a crucial step in seismic data processing. Traditional methods for seismic data reconstruction require the selection of multiple empirical parameters and struggle to handle large-scale continuous missing data. With the development of deep learning, various neural networks have demonstrated powerful reconstruction capabilities. However, these convolutional neural networks represent a point-to-point reconstruction approach that may not cover the entire distribution of the dataset. Consequently, when dealing with seismic data featuring complex missing patterns, such networks may experience varying degrees of performance degradation. In response to this challenge, we propose a novel diffusion model reconstruction framework tailored for 3D seismic data. To constrain the results generated by the diffusion model, we introduce conditional supervision constraints into the diffusion model, constraining the generated data of the diffusion model based on the input data to be reconstructed. We introduce a 3D neural network architecture into the diffusion model, successfully extending the 2D diffusion model to 3D space. Additionally, we refine the model's generation process by incorporating missing data into the generation process, resulting in reconstructions with higher consistency. Through ablation studies determining optimal parameter values, our method exhibits superior reconstruction accuracy when applied to both field datasets and synthetic datasets, effectively addressing a wide range of complex missing patterns. Our implementation is available at https://github.com/WAL-l/SeisFusion.
MobileVLM : A Fast, Strong and Open Vision Language Assistant for Mobile Devices
Dec 30, 2023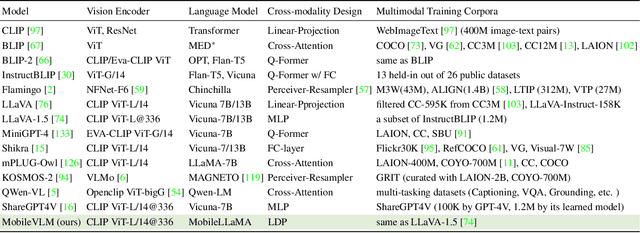
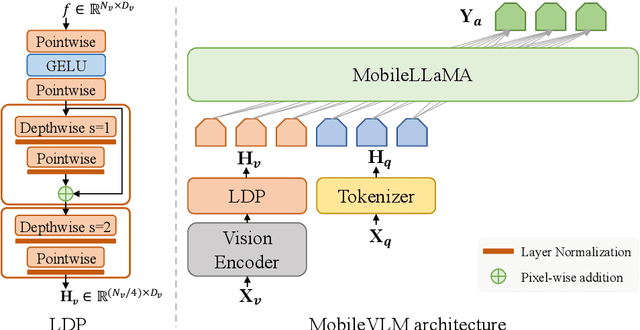
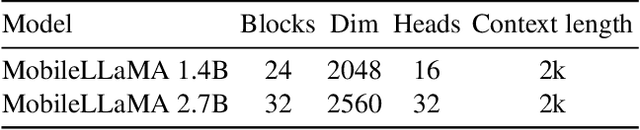
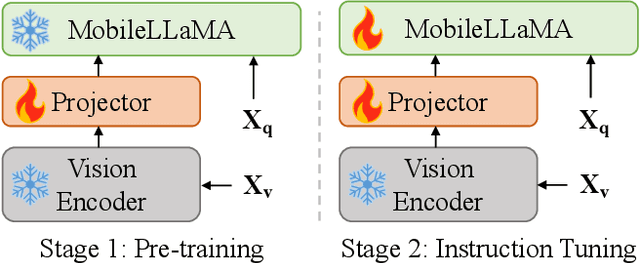
We present MobileVLM, a competent multimodal vision language model (MMVLM) targeted to run on mobile devices. It is an amalgamation of a myriad of architectural designs and techniques that are mobile-oriented, which comprises a set of language models at the scale of 1.4B and 2.7B parameters, trained from scratch, a multimodal vision model that is pre-trained in the CLIP fashion, cross-modality interaction via an efficient projector. We evaluate MobileVLM on several typical VLM benchmarks. Our models demonstrate on par performance compared with a few much larger models. More importantly, we measure the inference speed on both a Qualcomm Snapdragon 888 CPU and an NVIDIA Jeston Orin GPU, and we obtain state-of-the-art performance of 21.5 tokens and 65.3 tokens per second, respectively. Our code will be made available at: https://github.com/Meituan-AutoML/MobileVLM.
Enriching Phrases with Coupled Pixel and Object Contexts for Panoptic Narrative Grounding
Nov 02, 2023Panoptic narrative grounding (PNG) aims to segment things and stuff objects in an image described by noun phrases of a narrative caption. As a multimodal task, an essential aspect of PNG is the visual-linguistic interaction between image and caption. The previous two-stage method aggregates visual contexts from offline-generated mask proposals to phrase features, which tend to be noisy and fragmentary. The recent one-stage method aggregates only pixel contexts from image features to phrase features, which may incur semantic misalignment due to lacking object priors. To realize more comprehensive visual-linguistic interaction, we propose to enrich phrases with coupled pixel and object contexts by designing a Phrase-Pixel-Object Transformer Decoder (PPO-TD), where both fine-grained part details and coarse-grained entity clues are aggregated to phrase features. In addition, we also propose a PhraseObject Contrastive Loss (POCL) to pull closer the matched phrase-object pairs and push away unmatched ones for aggregating more precise object contexts from more phrase-relevant object tokens. Extensive experiments on the PNG benchmark show our method achieves new state-of-the-art performance with large margins.
Orthogonal Temporal Interpolation for Zero-Shot Video Recognition
Aug 14, 2023Zero-shot video recognition (ZSVR) is a task that aims to recognize video categories that have not been seen during the model training process. Recently, vision-language models (VLMs) pre-trained on large-scale image-text pairs have demonstrated impressive transferability for ZSVR. To make VLMs applicable to the video domain, existing methods often use an additional temporal learning module after the image-level encoder to learn the temporal relationships among video frames. Unfortunately, for video from unseen categories, we observe an abnormal phenomenon where the model that uses spatial-temporal feature performs much worse than the model that removes temporal learning module and uses only spatial feature. We conjecture that improper temporal modeling on video disrupts the spatial feature of the video. To verify our hypothesis, we propose Feature Factorization to retain the orthogonal temporal feature of the video and use interpolation to construct refined spatial-temporal feature. The model using appropriately refined spatial-temporal feature performs better than the one using only spatial feature, which verifies the effectiveness of the orthogonal temporal feature for the ZSVR task. Therefore, an Orthogonal Temporal Interpolation module is designed to learn a better refined spatial-temporal video feature during training. Additionally, a Matching Loss is introduced to improve the quality of the orthogonal temporal feature. We propose a model called OTI for ZSVR by employing orthogonal temporal interpolation and the matching loss based on VLMs. The ZSVR accuracies on popular video datasets (i.e., Kinetics-600, UCF101 and HMDB51) show that OTI outperforms the previous state-of-the-art method by a clear margin.
Exploration and Exploitation of Unlabeled Data for Open-Set Semi-Supervised Learning
Jun 30, 2023



In this paper, we address a complex but practical scenario in semi-supervised learning (SSL) named open-set SSL, where unlabeled data contain both in-distribution (ID) and out-of-distribution (OOD) samples. Unlike previous methods that only consider ID samples to be useful and aim to filter out OOD ones completely during training, we argue that the exploration and exploitation of both ID and OOD samples can benefit SSL. To support our claim, i) we propose a prototype-based clustering and identification algorithm that explores the inherent similarity and difference among samples at feature level and effectively cluster them around several predefined ID and OOD prototypes, thereby enhancing feature learning and facilitating ID/OOD identification; ii) we propose an importance-based sampling method that exploits the difference in importance of each ID and OOD sample to SSL, thereby reducing the sampling bias and improving the training. Our proposed method achieves state-of-the-art in several challenging benchmarks, and improves upon existing SSL methods even when ID samples are totally absent in unlabeled data.
3rd Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 11, 2023



In order to deal with the task of video panoptic segmentation in the wild, we propose a robust integrated video panoptic segmentation solution. In our solution, we regard the video panoptic segmentation task as a segmentation target querying task, represent both semantic and instance targets as a set of queries, and then combine these queries with video features extracted by neural networks to predict segmentation masks. In order to improve the learning accuracy and convergence speed of the solution, we add additional tasks of video semantic segmentation and video instance segmentation for joint training. In addition, we also add an additional image semantic segmentation model to further improve the performance of semantic classes. In addition, we also add some additional operations to improve the robustness of the model. Extensive experiments on the VIPSeg dataset show that the proposed solution achieves state-of-the-art performance with 50.04\% VPQ on the VIPSeg test set, which is 3rd place on the video panoptic segmentation track of the PVUW Challenge 2023.
Towards Accurate Post-Training Quantization for Vision Transformer
Mar 25, 2023



Vision transformer emerges as a potential architecture for vision tasks. However, the intense computation and non-negligible delay hinder its application in the real world. As a widespread model compression technique, existing post-training quantization methods still cause severe performance drops. We find the main reasons lie in (1) the existing calibration metric is inaccurate in measuring the quantization influence for extremely low-bit representation, and (2) the existing quantization paradigm is unfriendly to the power-law distribution of Softmax. Based on these observations, we propose a novel Accurate Post-training Quantization framework for Vision Transformer, namely APQ-ViT. We first present a unified Bottom-elimination Blockwise Calibration scheme to optimize the calibration metric to perceive the overall quantization disturbance in a blockwise manner and prioritize the crucial quantization errors that influence more on the final output. Then, we design a Matthew-effect Preserving Quantization for Softmax to maintain the power-law character and keep the function of the attention mechanism. Comprehensive experiments on large-scale classification and detection datasets demonstrate that our APQ-ViT surpasses the existing post-training quantization methods by convincing margins, especially in lower bit-width settings (e.g., averagely up to 5.17% improvement for classification and 24.43% for detection on W4A4). We also highlight that APQ-ViT enjoys versatility and works well on diverse transformer variants.
Pose-Controllable 3D Facial Animation Synthesis using Hierarchical Audio-Vertex Attention
Feb 24, 2023
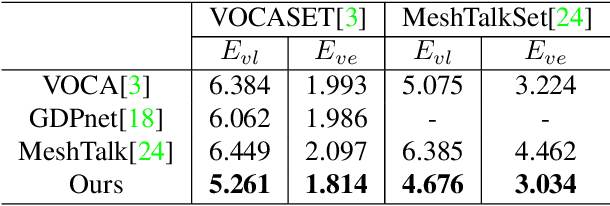

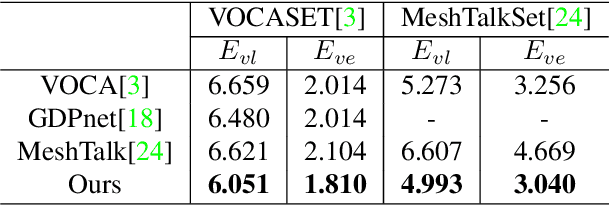
Most of the existing audio-driven 3D facial animation methods suffered from the lack of detailed facial expression and head pose, resulting in unsatisfactory experience of human-robot interaction. In this paper, a novel pose-controllable 3D facial animation synthesis method is proposed by utilizing hierarchical audio-vertex attention. To synthesize real and detailed expression, a hierarchical decomposition strategy is proposed to encode the audio signal into both a global latent feature and a local vertex-wise control feature. Then the local and global audio features combined with vertex spatial features are used to predict the final consistent facial animation via a graph convolutional neural network by fusing the intrinsic spatial topology structure of the face model and the corresponding semantic feature of the audio. To accomplish pose-controllable animation, we introduce a novel pose attribute augmentation method by utilizing the 2D talking face technique. Experimental results indicate that the proposed method can produce more realistic facial expressions and head posture movements. Qualitative and quantitative experiments show that the proposed method achieves competitive performance against state-of-the-art methods.
3D Colored Shape Reconstruction from a Single RGB Image through Diffusion
Feb 11, 2023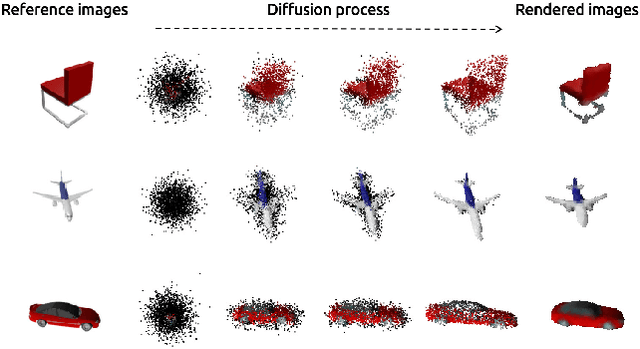
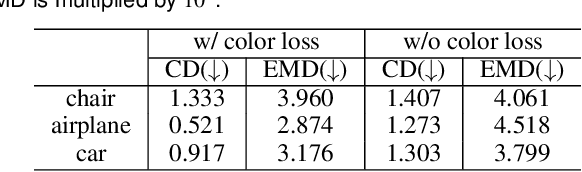
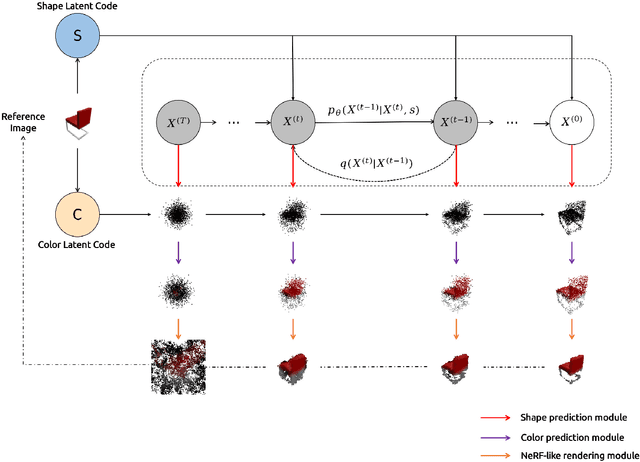
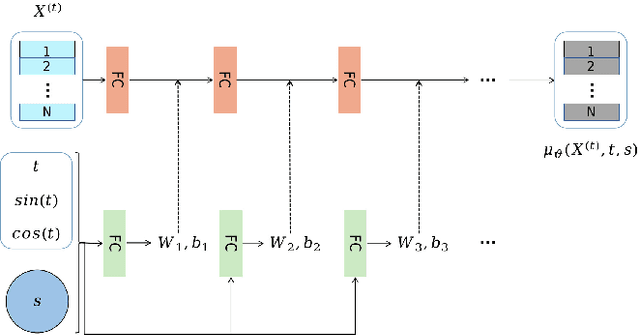
We propose a novel 3d colored shape reconstruction method from a single RGB image through diffusion model. Diffusion models have shown great development potentials for high-quality 3D shape generation. However, most existing work based on diffusion models only focus on geometric shape generation, they cannot either accomplish 3D reconstruction from a single image, or produce 3D geometric shape with color information. In this work, we propose to reconstruct a 3D colored shape from a single RGB image through a novel conditional diffusion model. The reverse process of the proposed diffusion model is consisted of three modules, shape prediction module, color prediction module and NeRF-like rendering module. In shape prediction module, the reference RGB image is first encoded into a high-level shape feature and then the shape feature is utilized as a condition to predict the reverse geometric noise in diffusion model. Then the color of each 3D point updated in shape prediction module is predicted by color prediction module. Finally, a NeRF-like rendering module is designed to render the colored point cloud predicted by the former two modules to 2D image space to guide the training conditioned only on a reference image. As far as the authors know, the proposed method is the first diffusion model for 3D colored shape reconstruction from a single RGB image. Experimental results demonstrate that the proposed method achieves competitive performance on colored 3D shape reconstruction, and the ablation study validates the positive role of the color prediction module in improving the reconstruction quality of 3D geometric point cloud.
Multiple Object Tracking Challenge Technical Report for Team MT_IoT
Dec 07, 2022This is a brief technical report of our proposed method for Multiple-Object Tracking (MOT) Challenge in Complex Environments. In this paper, we treat the MOT task as a two-stage task including human detection and trajectory matching. Specifically, we designed an improved human detector and associated most of detection to guarantee the integrity of the motion trajectory. We also propose a location-wise matching matrix to obtain more accurate trace matching. Without any model merging, our method achieves 66.672 HOTA and 93.971 MOTA on the DanceTrack challenge dataset.