 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGS-HPC: Distractor-free 3D Gaussian Splatting with Hybrid Patch-wise Classification
Mar 08, 20263D Gaussian Splatting (3DGS) has demonstrated remarkable performance in novel view synthesis and 3D scene reconstruction, yet its quality often degrades in real-world environments due to transient distractors, such as moving objects and varying shadows. Existing methods commonly rely on semantic cues extracted from pre-trained vision models to identify and suppress these distractors, but such semantics are misaligned with the binary distinction between static and transient regions and remain fragile under the appearance perturbations introduced during 3DGS optimization. We propose 3DGS-HPC, a framework that circumvents these limitations by combining two complementary principles: a patch-wise classification strategy that leverages local spatial consistency for robust region-level decisions, and a hybrid classification metric that adaptively integrates photometric and perceptual cues for more reliable separation. Extensive experiments demonstrate the superiority and robustness of our method in mitigating distractors to improve 3DGS-based novel view synthesis.
Aerial Vision-and-Language Navigation with Grid-based View Selection and Map Construction
Mar 14, 2025Aerial Vision-and-Language Navigation (Aerial VLN) aims to obtain an unmanned aerial vehicle agent to navigate aerial 3D environments following human instruction. Compared to ground-based VLN, aerial VLN requires the agent to decide the next action in both horizontal and vertical directions based on the first-person view observations. Previous methods struggle to perform well due to the longer navigation path, more complicated 3D scenes, and the neglect of the interplay between vertical and horizontal actions. In this paper, we propose a novel grid-based view selection framework that formulates aerial VLN action prediction as a grid-based view selection task, incorporating vertical action prediction in a manner that accounts for the coupling with horizontal actions, thereby enabling effective altitude adjustments. We further introduce a grid-based bird's eye view map for aerial space to fuse the visual information in the navigation history, provide contextual scene information, and mitigate the impact of obstacles. Finally, a cross-modal transformer is adopted to explicitly align the long navigation history with the instruction. We demonstrate the superiority of our method in extensive experiments.
Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI
Jul 09, 2024



Embodied Artificial Intelligence (Embodied AI) is crucial for achieving Artificial General Intelligence (AGI) and serves as a foundation for various applications that bridge cyberspace and the physical world. Recently, the emergence of Multi-modal Large Models (MLMs) and World Models (WMs) have attracted significant attention due to their remarkable perception, interaction, and reasoning capabilities, making them a promising architecture for the brain of embodied agents. However, there is no comprehensive survey for Embodied AI in the era of MLMs. In this survey, we give a comprehensive exploration of the latest advancements in Embodied AI. Our analysis firstly navigates through the forefront of representative works of embodied robots and simulators, to fully understand the research focuses and their limitations. Then, we analyze four main research targets: 1) embodied perception, 2) embodied interaction, 3) embodied agent, and 4) sim-to-real adaptation, covering the state-of-the-art methods, essential paradigms, and comprehensive datasets. Additionally, we explore the complexities of MLMs in virtual and real embodied agents, highlighting their significance in facilitating interactions in dynamic digital and physical environments. Finally, we summarize the challenges and limitations of embodied AI and discuss their potential future directions. We hope this survey will serve as a foundational reference for the research community and inspire continued innovation. The associated project can be found at https://github.com/HCPLab-SYSU/Embodied_AI_Paper_List.
OVER-NAV: Elevating Iterative Vision-and-Language Navigation with Open-Vocabulary Detection and StructurEd Representation
Mar 26, 2024Recent advances in Iterative Vision-and-Language Navigation (IVLN) introduce a more meaningful and practical paradigm of VLN by maintaining the agent's memory across tours of scenes. Although the long-term memory aligns better with the persistent nature of the VLN task, it poses more challenges on how to utilize the highly unstructured navigation memory with extremely sparse supervision. Towards this end, we propose OVER-NAV, which aims to go over and beyond the current arts of IVLN techniques. In particular, we propose to incorporate LLMs and open-vocabulary detectors to distill key information and establish correspondence between multi-modal signals. Such a mechanism introduces reliable cross-modal supervision and enables on-the-fly generalization to unseen scenes without the need of extra annotation and re-training. To fully exploit the interpreted navigation data, we further introduce a structured representation, coded Omnigraph, to effectively integrate multi-modal information along the tour. Accompanied with a novel omnigraph fusion mechanism, OVER-NAV is able to extract the most relevant knowledge from omnigraph for a more accurate navigating action. In addition, OVER-NAV seamlessly supports both discrete and continuous environments under a unified framework. We demonstrate the superiority of OVER-NAV in extensive experiments.
Improved Distribution Matching for Dataset Condensation
Jul 19, 2023Dataset Condensation aims to condense a large dataset into a smaller one while maintaining its ability to train a well-performing model, thus reducing the storage cost and training effort in deep learning applications. However, conventional dataset condensation methods are optimization-oriented and condense the dataset by performing gradient or parameter matching during model optimization, which is computationally intensive even on small datasets and models. In this paper, we propose a novel dataset condensation method based on distribution matching, which is more efficient and promising. Specifically, we identify two important shortcomings of naive distribution matching (i.e., imbalanced feature numbers and unvalidated embeddings for distance computation) and address them with three novel techniques (i.e., partitioning and expansion augmentation, efficient and enriched model sampling, and class-aware distribution regularization). Our simple yet effective method outperforms most previous optimization-oriented methods with much fewer computational resources, thereby scaling data condensation to larger datasets and models. Extensive experiments demonstrate the effectiveness of our method. Codes are available at https://github.com/uitrbn/IDM
Exploration and Exploitation of Unlabeled Data for Open-Set Semi-Supervised Learning
Jun 30, 2023



In this paper, we address a complex but practical scenario in semi-supervised learning (SSL) named open-set SSL, where unlabeled data contain both in-distribution (ID) and out-of-distribution (OOD) samples. Unlike previous methods that only consider ID samples to be useful and aim to filter out OOD ones completely during training, we argue that the exploration and exploitation of both ID and OOD samples can benefit SSL. To support our claim, i) we propose a prototype-based clustering and identification algorithm that explores the inherent similarity and difference among samples at feature level and effectively cluster them around several predefined ID and OOD prototypes, thereby enhancing feature learning and facilitating ID/OOD identification; ii) we propose an importance-based sampling method that exploits the difference in importance of each ID and OOD sample to SSL, thereby reducing the sampling bias and improving the training. Our proposed method achieves state-of-the-art in several challenging benchmarks, and improves upon existing SSL methods even when ID samples are totally absent in unlabeled data.
Centrality and Consistency: Two-Stage Clean Samples Identification for Learning with Instance-Dependent Noisy Labels
Jul 29, 2022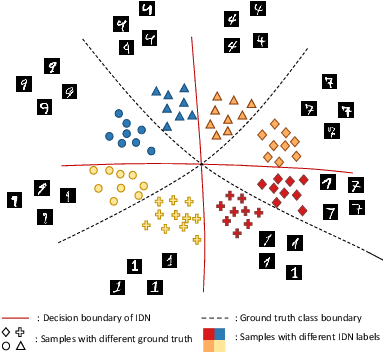
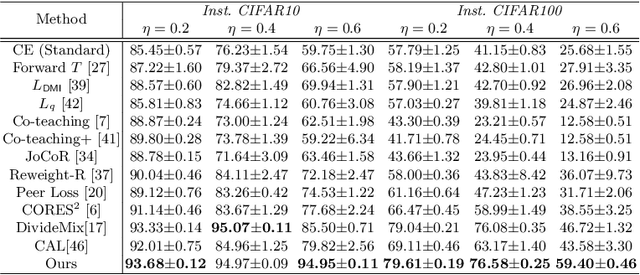

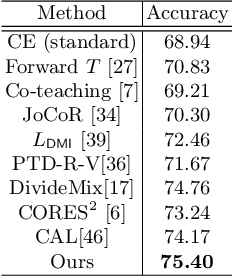
Deep models trained with noisy labels are prone to over-fitting and struggle in generalization. Most existing solutions are based on an ideal assumption that the label noise is class-conditional, i.e., instances of the same class share the same noise model, and are independent of features. While in practice, the real-world noise patterns are usually more fine-grained as instance-dependent ones, which poses a big challenge, especially in the presence of inter-class imbalance. In this paper, we propose a two-stage clean samples identification method to address the aforementioned challenge. First, we employ a class-level feature clustering procedure for the early identification of clean samples that are near the class-wise prediction centers. Notably, we address the class imbalance problem by aggregating rare classes according to their prediction entropy. Second, for the remaining clean samples that are close to the ground truth class boundary (usually mixed with the samples with instance-dependent noises), we propose a novel consistency-based classification method that identifies them using the consistency of two classifier heads: the higher the consistency, the larger the probability that a sample is clean. Extensive experiments on several challenging benchmarks demonstrate the superior performance of our method against the state-of-the-art.
Collaborative Training between Region Proposal Localization and Classification for Domain Adaptive Object Detection
Sep 18, 2020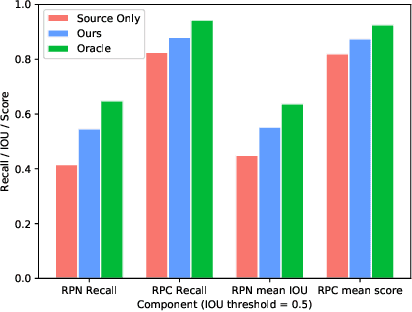

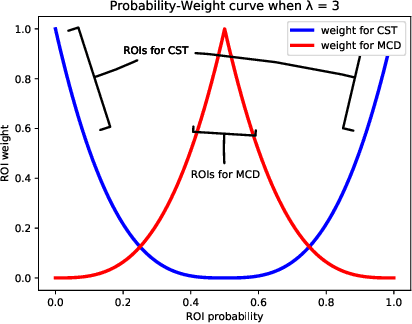

Object detectors are usually trained with large amount of labeled data, which is expensive and labor-intensive. Pre-trained detectors applied to unlabeled dataset always suffer from the difference of dataset distribution, also called domain shift. Domain adaptation for object detection tries to adapt the detector from labeled datasets to unlabeled ones for better performance. In this paper, we are the first to reveal that the region proposal network (RPN) and region proposal classifier~(RPC) in the endemic two-stage detectors (e.g., Faster RCNN) demonstrate significantly different transferability when facing large domain gap. The region classifier shows preferable performance but is limited without RPN's high-quality proposals while simple alignment in the backbone network is not effective enough for RPN adaptation. We delve into the consistency and the difference of RPN and RPC, treat them individually and leverage high-confidence output of one as mutual guidance to train the other. Moreover, the samples with low-confidence are used for discrepancy calculation between RPN and RPC and minimax optimization. Extensive experimental results on various scenarios have demonstrated the effectiveness of our proposed method in both domain-adaptive region proposal generation and object detection. Code is available at https://github.com/GanlongZhao/CST_DA_detection.