 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapGPT: Map-Guided Prompting for Unified Vision-and-Language Navigation
Jan 14, 2024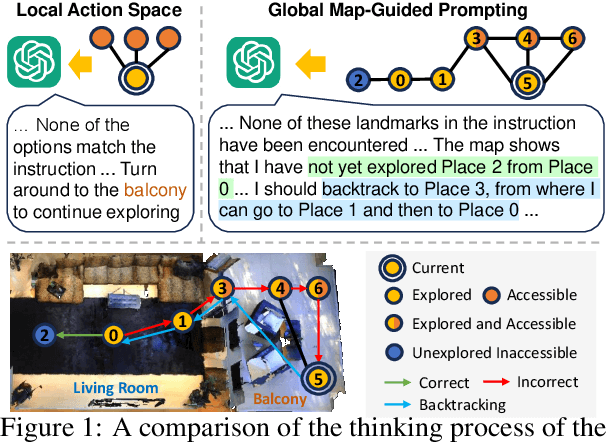
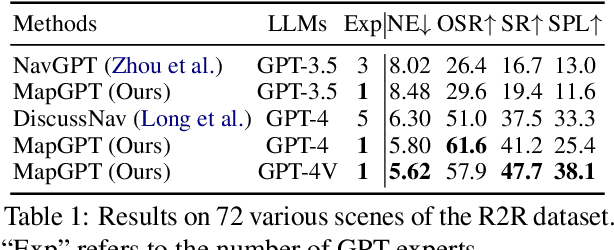
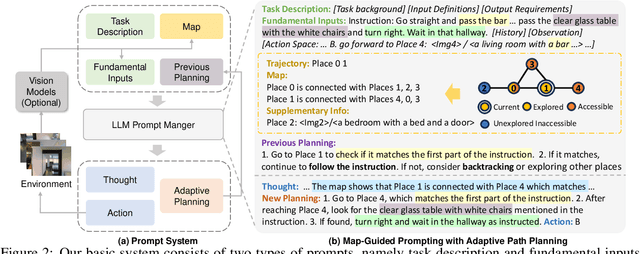
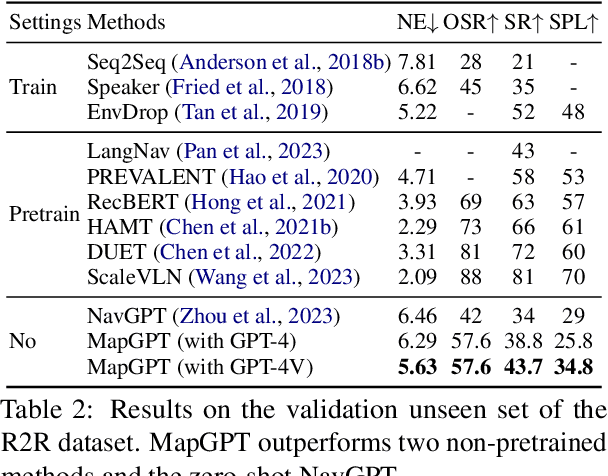
Embodied agents equipped with GPT as their brain have exhibited extraordinary thinking and decision-making abilities across various tasks. However, existing zero-shot agents for vision-and-language navigation (VLN) only prompt the GPT to handle excessive environmental information and select potential locations within localized environments, without constructing an effective ''global-view'' (e.g., a commonly-used map) for the agent to understand the overall environment. In this work, we present a novel map-guided GPT-based path-planning agent, dubbed MapGPT, for the zero-shot VLN task. Specifically, we convert a topological map constructed online into prompts to encourage map-guided global exploration, and require the agent to explicitly output and update multi-step path planning to avoid getting stuck in local exploration. Extensive experiments demonstrate that our MapGPT is effective, achieving impressive performance on both the R2R and REVERIE datasets (38.8% and 28.4% success rate, respectively) and showcasing the newly emerged global thinking and path planning capabilities of the GPT model. Unlike previous VLN agents, which require separate parameters fine-tuning or specific prompt design to accommodate various instruction styles across different datasets, our MapGPT is more unified as it can adapt to different instruction styles seamlessly, which is the first of its kind in this field.
Divide and Adapt: Active Domain Adaptation via Customized Learning
Jul 21, 2023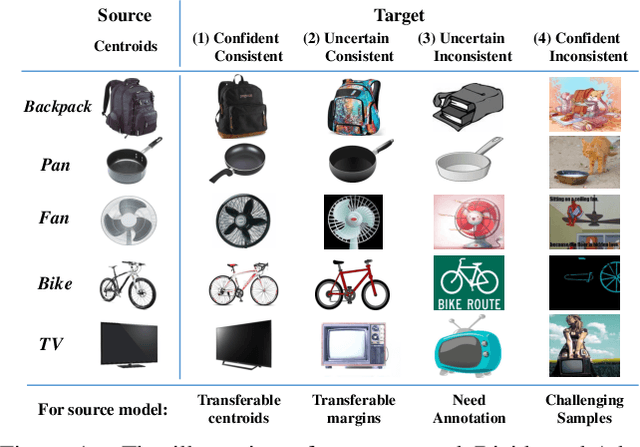
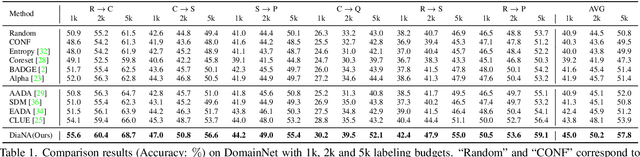
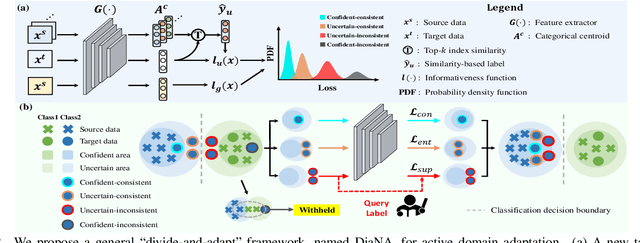
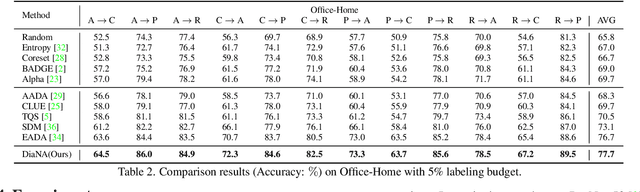
Active domain adaptation (ADA) aims to improve the model adaptation performance by incorporating active learning (AL) techniques to label a maximally-informative subset of target samples. Conventional AL methods do not consider the existence of domain shift, and hence, fail to identify the truly valuable samples in the context of domain adaptation. To accommodate active learning and domain adaption, the two naturally different tasks, in a collaborative framework, we advocate that a customized learning strategy for the target data is the key to the success of ADA solutions. We present Divide-and-Adapt (DiaNA), a new ADA framework that partitions the target instances into four categories with stratified transferable properties. With a novel data subdivision protocol based on uncertainty and domainness, DiaNA can accurately recognize the most gainful samples. While sending the informative instances for annotation, DiaNA employs tailored learning strategies for the remaining categories. Furthermore, we propose an informativeness score that unifies the data partitioning criteria. This enables the use of a Gaussian mixture model (GMM) to automatically sample unlabeled data into the proposed four categories. Thanks to the "divideand-adapt" spirit, DiaNA can handle data with large variations of domain gap. In addition, we show that DiaNA can generalize to different domain adaptation settings, such as unsupervised domain adaptation (UDA), semi-supervised domain adaptation (SSDA), source-free domain adaptation (SFDA), etc.
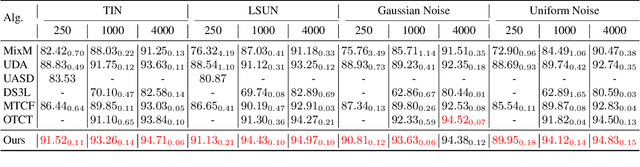
Exploration and Exploitation of Unlabeled Data for Open-Set Semi-Supervised Learning
Jun 30, 2023



In this paper, we address a complex but practical scenario in semi-supervised learning (SSL) named open-set SSL, where unlabeled data contain both in-distribution (ID) and out-of-distribution (OOD) samples. Unlike previous methods that only consider ID samples to be useful and aim to filter out OOD ones completely during training, we argue that the exploration and exploitation of both ID and OOD samples can benefit SSL. To support our claim, i) we propose a prototype-based clustering and identification algorithm that explores the inherent similarity and difference among samples at feature level and effectively cluster them around several predefined ID and OOD prototypes, thereby enhancing feature learning and facilitating ID/OOD identification; ii) we propose an importance-based sampling method that exploits the difference in importance of each ID and OOD sample to SSL, thereby reducing the sampling bias and improving the training. Our proposed method achieves state-of-the-art in several challenging benchmarks, and improves upon existing SSL methods even when ID samples are totally absent in unlabeled data.
Towards Accurate Post-Training Quantization for Vision Transformer
Mar 25, 2023



Vision transformer emerges as a potential architecture for vision tasks. However, the intense computation and non-negligible delay hinder its application in the real world. As a widespread model compression technique, existing post-training quantization methods still cause severe performance drops. We find the main reasons lie in (1) the existing calibration metric is inaccurate in measuring the quantization influence for extremely low-bit representation, and (2) the existing quantization paradigm is unfriendly to the power-law distribution of Softmax. Based on these observations, we propose a novel Accurate Post-training Quantization framework for Vision Transformer, namely APQ-ViT. We first present a unified Bottom-elimination Blockwise Calibration scheme to optimize the calibration metric to perceive the overall quantization disturbance in a blockwise manner and prioritize the crucial quantization errors that influence more on the final output. Then, we design a Matthew-effect Preserving Quantization for Softmax to maintain the power-law character and keep the function of the attention mechanism. Comprehensive experiments on large-scale classification and detection datasets demonstrate that our APQ-ViT surpasses the existing post-training quantization methods by convincing margins, especially in lower bit-width settings (e.g., averagely up to 5.17% improvement for classification and 24.43% for detection on W4A4). We also highlight that APQ-ViT enjoys versatility and works well on diverse transformer variants.
Compressing Models with Few Samples: Mimicking then Replacing
Jan 07, 2022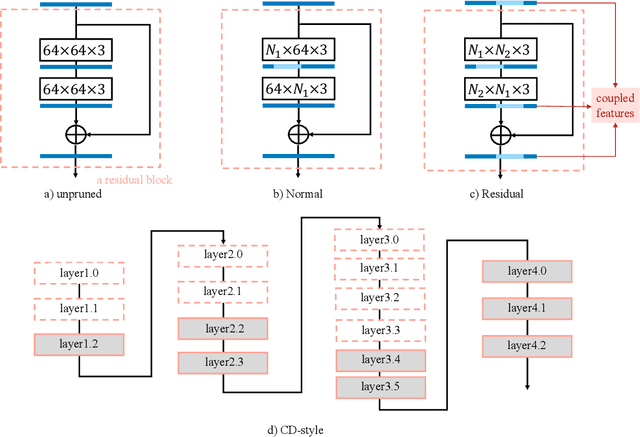

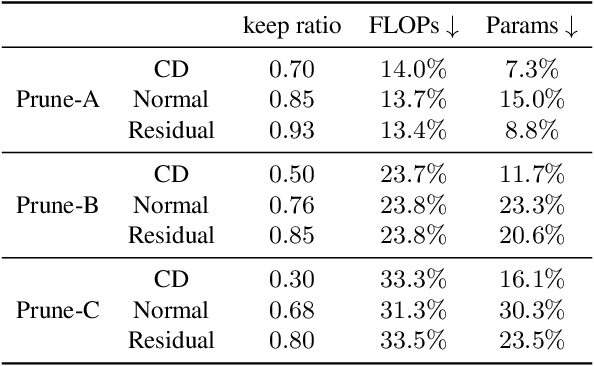
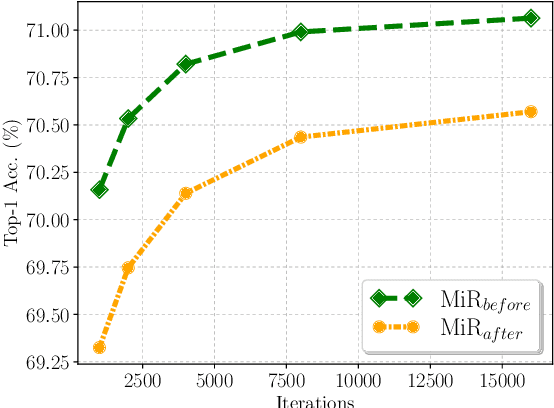
Few-sample compression aims to compress a big redundant model into a small compact one with only few samples. If we fine-tune models with these limited few samples directly, models will be vulnerable to overfit and learn almost nothing. Hence, previous methods optimize the compressed model layer-by-layer and try to make every layer have the same outputs as the corresponding layer in the teacher model, which is cumbersome. In this paper, we propose a new framework named Mimicking then Replacing (MiR) for few-sample compression, which firstly urges the pruned model to output the same features as the teacher's in the penultimate layer, and then replaces teacher's layers before penultimate with a well-tuned compact one. Unlike previous layer-wise reconstruction methods, our MiR optimizes the entire network holistically, which is not only simple and effective, but also unsupervised and general. MiR outperforms previous methods with large margins. Codes will be available soon.
Contrastive Attention Network with Dense Field Estimation for Face Completion
Dec 20, 2021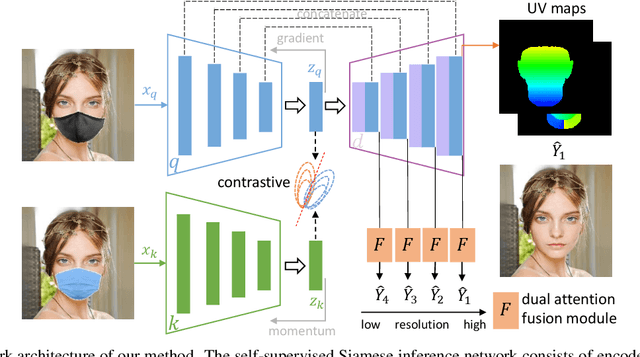
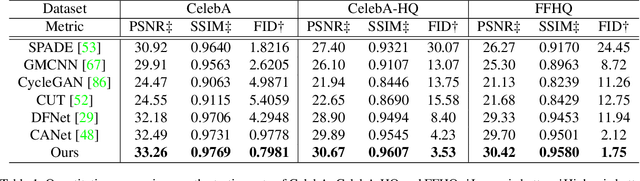
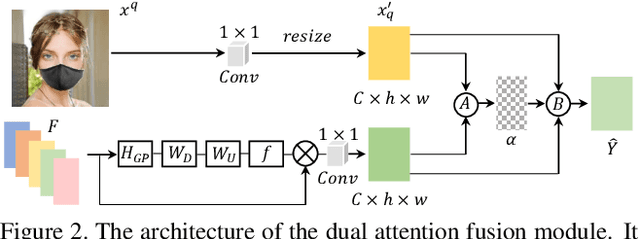

Most modern face completion approaches adopt an autoencoder or its variants to restore missing regions in face images. Encoders are often utilized to learn powerful representations that play an important role in meeting the challenges of sophisticated learning tasks. Specifically, various kinds of masks are often presented in face images in the wild, forming complex patterns, especially in this hard period of COVID-19. It's difficult for encoders to capture such powerful representations under this complex situation. To address this challenge, we propose a self-supervised Siamese inference network to improve the generalization and robustness of encoders. It can encode contextual semantics from full-resolution images and obtain more discriminative representations. To deal with geometric variations of face images, a dense correspondence field is integrated into the network. We further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine the restored and known regions in an adaptive manner. This multi-scale architecture is beneficial for the decoder to utilize discriminative representations learned from encoders into images. Extensive experiments clearly demonstrate that the proposed approach not only achieves more appealing results compared with state-of-the-art methods but also improves the performance of masked face recognition dramatically.
Trash to Treasure: Harvesting OOD Data with Cross-Modal Matching for Open-Set Semi-Supervised Learning
Aug 12, 2021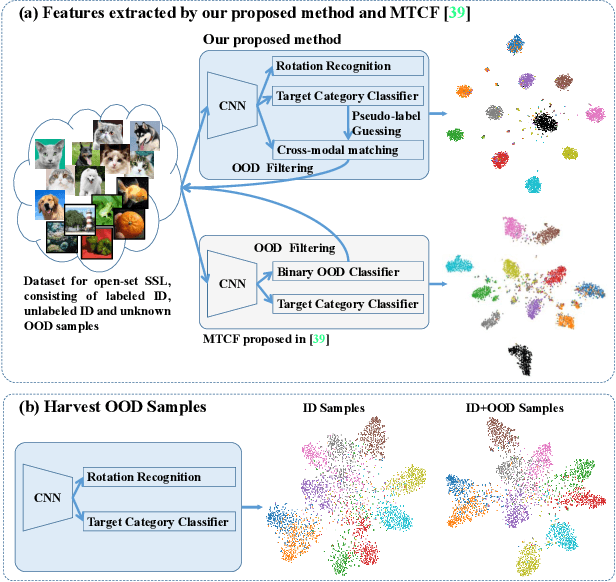
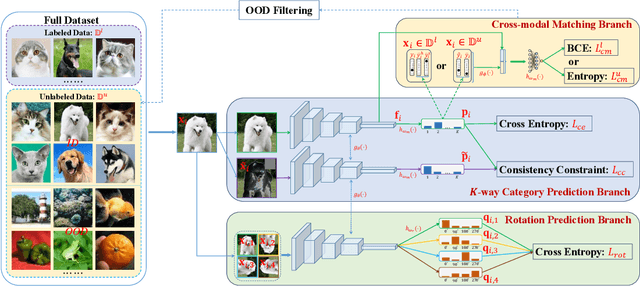

Open-set semi-supervised learning (open-set SSL) investigates a challenging but practical scenario where out-of-distribution (OOD) samples are contained in the unlabeled data. While the mainstream technique seeks to completely filter out the OOD samples for semi-supervised learning (SSL), we propose a novel training mechanism that could effectively exploit the presence of OOD data for enhanced feature learning while avoiding its adverse impact on the SSL. We achieve this goal by first introducing a warm-up training that leverages all the unlabeled data, including both the in-distribution (ID) and OOD samples. Specifically, we perform a pretext task that enforces our feature extractor to obtain a high-level semantic understanding of the training images, leading to more discriminative features that can benefit the downstream tasks. Since the OOD samples are inevitably detrimental to SSL, we propose a novel cross-modal matching strategy to detect OOD samples. Instead of directly applying binary classification, we train the network to predict whether the data sample is matched to an assigned one-hot class label. The appeal of the proposed cross-modal matching over binary classification is the ability to generate a compatible feature space that aligns with the core classification task. Extensive experiments show that our approach substantially lifts the performance on open-set SSL and outperforms the state-of-the-art by a large margin.
Rethinking BiSeNet For Real-time Semantic Segmentation
Apr 27, 2021


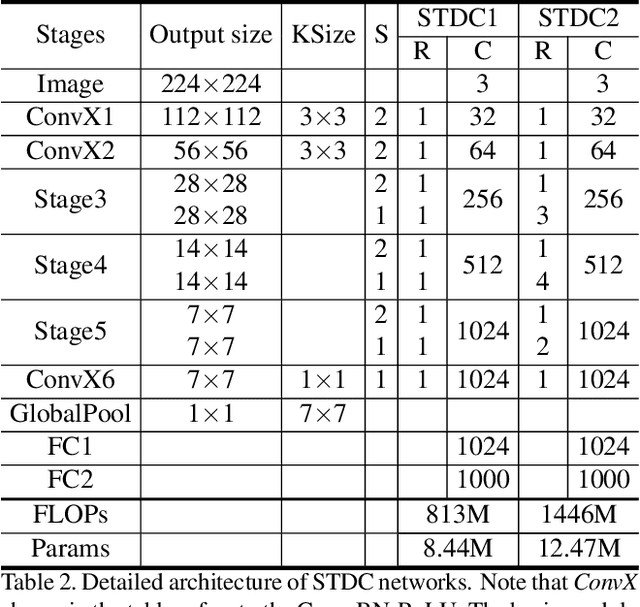
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
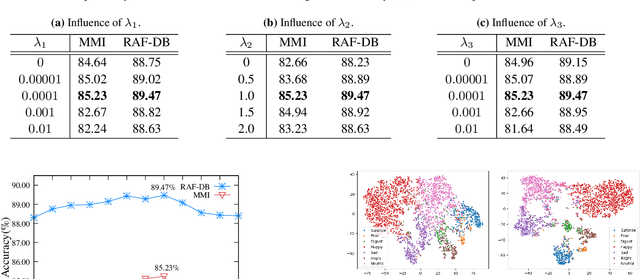
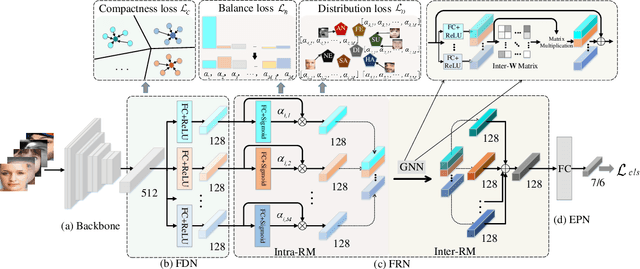
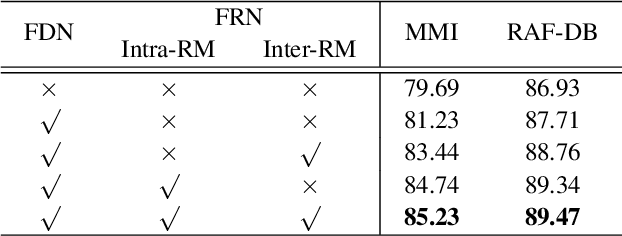
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.
Free-Form Image Inpainting via Contrastive Attention Network
Oct 29, 2020
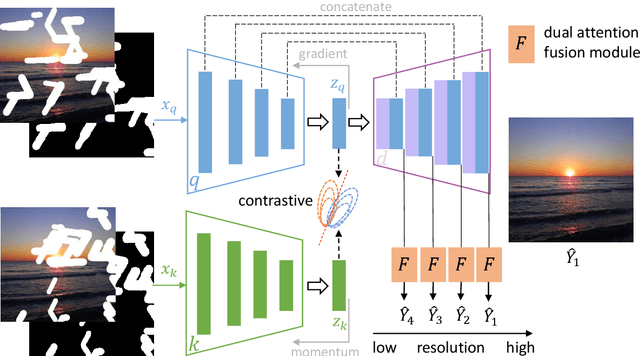
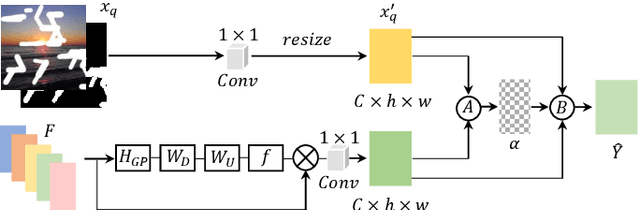

Most deep learning based image inpainting approaches adopt autoencoder or its variants to fill missing regions in images. Encoders are usually utilized to learn powerful representational spaces, which are important for dealing with sophisticated learning tasks. Specifically, in image inpainting tasks, masks with any shapes can appear anywhere in images (i.e., free-form masks) which form complex patterns. It is difficult for encoders to capture such powerful representations under this complex situation. To tackle this problem, we propose a self-supervised Siamese inference network to improve the robustness and generalization. It can encode contextual semantics from full resolution images and obtain more discriminative representations. we further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine both the restored and known regions in a smooth way. This multi-scale architecture is beneficial for decoding discriminative representations learned by encoders into images layer by layer. In this way, unknown regions will be filled naturally from outside to inside. Qualitative and quantitative experiments on multiple datasets, including facial and natural datasets (i.e., Celeb-HQ, Pairs Street View, Places2 and ImageNet), demonstrate that our proposed method outperforms state-of-the-art methods in generating high-quality inpainting results.