 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Gram Alignment for Ultra-High-Resolution Image Synthesis
May 20, 2026Modern ultra-high-resolution image synthesis relies heavily on the robust generative capacity of large-scale pre-trained Latent Diffusion Models (LDMs). While recent representation alignment methods have proven effective by distilling visual priors from foundation models (e.g., SAM or DINO) into generative latent features, scaling these approaches to pre-trained LDMs at extreme resolutions exposes a critical learnability-fidelity conflict. Specifically, forcing direct patch-wise feature distillation inherently perturbs the pre-trained latent manifold, ultimately leading to generation degradation. To address this bottleneck, we propose Spatial Gram Alignment (SGA), a novel framework that explicitly leverages the representation priors of vision foundation models while preserving the native generative capacity of LDMs. Moving beyond restrictive direct alignment, SGA imposes a non-invasive spatial constraint by aligning the internal self-similarities of the generative features with those of the foundation priors. This spatial constraint effectively establishes macroscopic structural coherence, while the native generative objectives retain the microscopic pixel-level fidelity inherent to the original LDMs. Notably, this versatile strategy integrates seamlessly across both intermediate diffusion features and VAE latents within pre-trained LDMs. Extensive experiments demonstrate that SGA achieves state-of-the-art performance for ultra-high-resolution text-to-image synthesis, yielding an effective reconciliation between global structural integrity and fine-grained visual details. Code is available at https://github.com/zhang0jhon/SGA.
What Makes Synthetic Data Effective in Image Segmentation
May 19, 2026Driven by rapid advances in large-scale generative models, synthetic data has emerged as a promising solution for visual understanding. While modern diffusion models achieve remarkable photorealistic image synthesis, their potential in complex visual segmentation tasks remains underexplored. In this work, we conduct a systematic analysis of synthetic images from state-of-the-art diffusion models to uncover the factors governing their utility. In particular, synthetic images characterized by dense scene composition and fine instance fidelity demonstrate distinctive benefits, yielding significantly more discriminative spatial representations. Building on these insights, we propose SENSE, a unified framework that leverages flexible and scalable synthetic data to substantially enhance segmentation performance. Notably, SENSE is model-agnostic, compatible with diverse architectures (e.g., DPT and Mask2Former), and scales effectively across models with varying parameter capacities. Extensive experiments on Cityscapes, COCO, and ADE20K validate the effectiveness and generalization capability of our approach. Code is available at https://github.com/zhang0jhon/SENSE.
Reasoning-Driven Anomaly Detection and Localization with Image-Level Supervision
Mar 28, 2026Multimodal large language models (MLLMs) have recently demonstrated remarkable reasoning and perceptual abilities for anomaly detection. However, most approaches remain confined to image-level anomaly detection and textual reasoning, while pixel-level localization still relies on external vision modules and dense annotations. In this work, we activate the intrinsic reasoning potential of MLLMs to perform anomaly detection, pixel-level localization, and interpretable reasoning solely from image-level supervision, without any auxiliary components or pixel-wise labels. Specifically, we propose Reasoning-Driven Anomaly Localization (ReAL), which extracts anomaly-related tokens from the autoregressive reasoning process and aggregates their attention responses to produce pixel-level anomaly maps. We further introduce a Consistency-Guided Reasoning Optimization (CGRO) module that leverages reinforcement learning to align reasoning tokens with visual attentions, resulting in more coherent reasoning and accurate anomaly localization. Extensive experiments on four public benchmarks demonstrate that our method significantly improves anomaly detection, localization, and interpretability. Remarkably, despite relying solely on image-level supervision, our approach achieves performance competitive with MLLM-based methods trained under dense pixel-level supervision. Code is available at https://github.com/YizhouJin313/ReADL.
LIBERO-X: Robustness Litmus for Vision-Language-Action Models
Feb 06, 2026Reliable benchmarking is critical for advancing Vision-Language-Action (VLA) models, as it reveals their generalization, robustness, and alignment of perception with language-driven manipulation tasks. However, existing benchmarks often provide limited or misleading assessments due to insufficient evaluation protocols that inadequately capture real-world distribution shifts. This work systematically rethinks VLA benchmarking from both evaluation and data perspectives, introducing LIBERO-X, a benchmark featuring: 1) A hierarchical evaluation protocol with progressive difficulty levels targeting three core capabilities: spatial generalization, object recognition, and task instruction understanding. This design enables fine-grained analysis of performance degradation under increasing environmental and task complexity; 2) A high-diversity training dataset collected via human teleoperation, where each scene supports multiple fine-grained manipulation objectives to bridge the train-evaluation distribution gap. Experiments with representative VLA models reveal significant performance drops under cumulative perturbations, exposing persistent limitations in scene comprehension and instruction grounding. By integrating hierarchical evaluation with diverse training data, LIBERO-X offers a more reliable foundation for assessing and advancing VLA development.
ONER: Online Experience Replay for Incremental Anomaly Detection
Dec 05, 2024Incremental anomaly detection sequentially recognizes abnormal regions in novel categories for dynamic industrial scenarios. This remains highly challenging due to knowledge overwriting and feature conflicts, leading to catastrophic forgetting. In this work, we propose ONER, an end-to-end ONline Experience Replay method, which efficiently mitigates catastrophic forgetting while adapting to new tasks with minimal cost. Specifically, our framework utilizes two types of experiences from past tasks: decomposed prompts and semantic prototypes, addressing both model parameter updates and feature optimization. The decomposed prompts consist of learnable components that assemble to produce attention-conditioned prompts. These prompts reuse previously learned knowledge, enabling model to learn novel tasks effectively. The semantic prototypes operate at both pixel and image levels, performing regularization in the latent feature space to prevent forgetting across various tasks. Extensive experiments demonstrate that our method achieves state-of-the-art performance in incremental anomaly detection with significantly reduced forgetting, as well as efficiently adapting to new categories with minimal costs. These results confirm the efficiency and stability of ONER, making it a powerful solution for real-world applications.
Exploration and Exploitation of Unlabeled Data for Open-Set Semi-Supervised Learning
Jun 30, 2023



In this paper, we address a complex but practical scenario in semi-supervised learning (SSL) named open-set SSL, where unlabeled data contain both in-distribution (ID) and out-of-distribution (OOD) samples. Unlike previous methods that only consider ID samples to be useful and aim to filter out OOD ones completely during training, we argue that the exploration and exploitation of both ID and OOD samples can benefit SSL. To support our claim, i) we propose a prototype-based clustering and identification algorithm that explores the inherent similarity and difference among samples at feature level and effectively cluster them around several predefined ID and OOD prototypes, thereby enhancing feature learning and facilitating ID/OOD identification; ii) we propose an importance-based sampling method that exploits the difference in importance of each ID and OOD sample to SSL, thereby reducing the sampling bias and improving the training. Our proposed method achieves state-of-the-art in several challenging benchmarks, and improves upon existing SSL methods even when ID samples are totally absent in unlabeled data.
A calculus for epistemic interactions
Jun 29, 2022



It plays a central role in intelligent agent systems to model agent's epistemic state and its change. To this end, some formal systems have been presented. Among them, epistemic logics focus on logic laws of different epistemic attributes (e.g., knowledge, belief, common knowledge, etc) and epistemic actions (e.g., public announcement, private announcement, asynchronous announcement, etc). All these systems do not involve the interactive behaviours between an agent and its environment. Through enriching the well-known $\pi$-calculus, this paper presents the e-calculus, which provides a concept framework to model epistemic interactions between agents with epistemic states. Unlike usual process calculus, all systems in the e-calculus are always arranged to run at an epistemic state. To formalize epistemic states abstractly, a group of postulates on them are presented. Moreover, based on these postulates, the behaviour theory of the e-calculus is developed in two different viewpoints.
Representation and Correlation Enhanced Encoder-Decoder Framework for Scene Text Recognition
Jun 13, 2021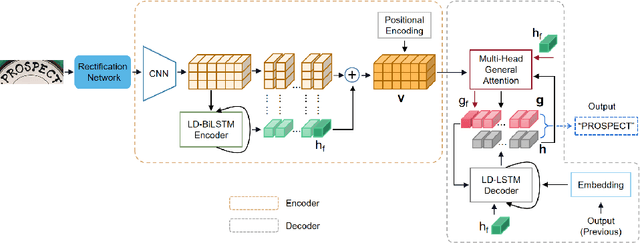
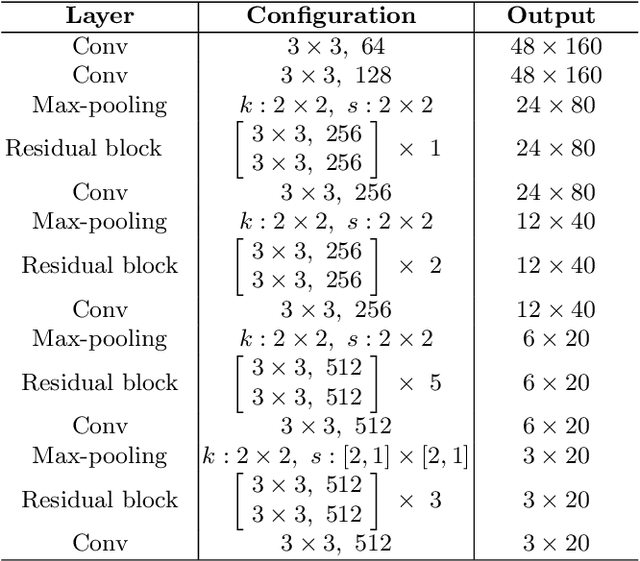

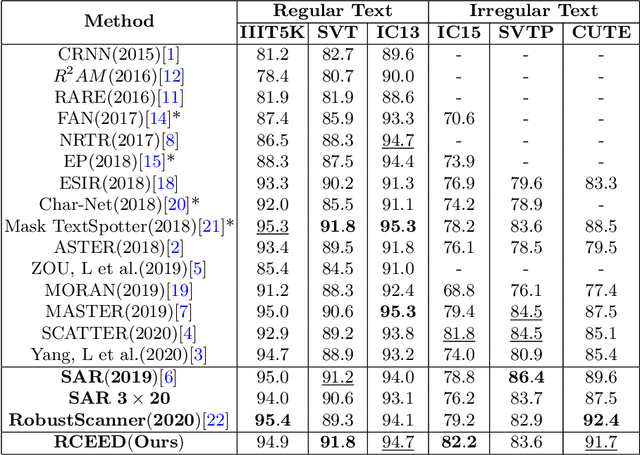
Attention-based encoder-decoder framework is widely used in the scene text recognition task. However, for the current state-of-the-art(SOTA) methods, there is room for improvement in terms of the efficient usage of local visual and global context information of the input text image, as well as the robust correlation between the scene processing module(encoder) and the text processing module(decoder). In this paper, we propose a Representation and Correlation Enhanced Encoder-Decoder Framework(RCEED) to address these deficiencies and break performance bottleneck. In the encoder module, local visual feature, global context feature, and position information are aligned and fused to generate a small-size comprehensive feature map. In the decoder module, two methods are utilized to enhance the correlation between scene and text feature space. 1) The decoder initialization is guided by the holistic feature and global glimpse vector exported from the encoder. 2) The feature enriched glimpse vector produced by the Multi-Head General Attention is used to assist the RNN iteration and the character prediction at each time step. Meanwhile, we also design a Layernorm-Dropout LSTM cell to improve model's generalization towards changeable texts. Extensive experiments on the benchmarks demonstrate the advantageous performance of RCEED in scene text recognition tasks, especially the irregular ones.
On graded semantics of abstract argumentation: Extension-based case
Dec 27, 2020



Based on Grossi and Modgil's recent work [1], this paper considers some issues on extension-based semantics for abstract argumentation framework (AAF, for short). First, an alternative fundamental lemma is given, which generalizes the corresponding result obtained in [1]. This lemma plays a central role in constructing some special extensions in terms of iterations of the defense function. Applying this lemma, some flaws in [1] are corrected and a number of structural properties of various extension-based semantics are given. Second, the operator so-called reduced meet modulo an ultrafilter is presented. A number of fundamental semantics for AAF, including conflict-free, admissible, complete and stable semantics, are shown to be closed under this operator. Based on this fact, we provide a concise and uniform proof method to establish the universal definability of a family of range related semantics. Thirdly, using model-theoretical tools, we characterize the class of extension-based semantics that is closed under reduced meet modulo any ultrafilter, which brings us a metatheorem concerning the universal definability of range related semantics. Finally, in addition to range related semantics, some graded variants of traditional semantics of AAF are also considered in this paper, e.g., ideal semantics, eager semantics, etc.
A Feasible Framework for Arbitrary-Shaped Scene Text Recognition
Dec 12, 2019
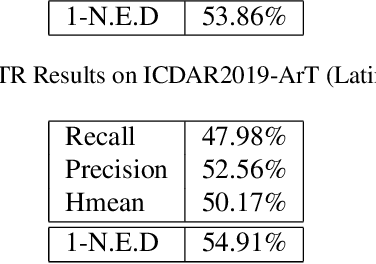
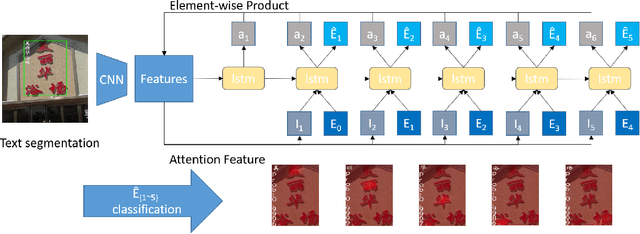
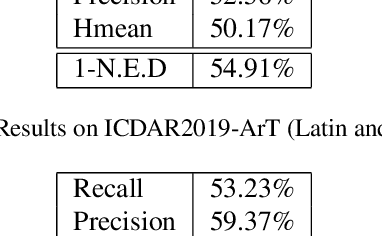
Deep learning based methods have achieved surprising progress in Scene Text Recognition (STR), one of classic problems in computer vision. In this paper, we propose a feasible framework for multi-lingual arbitrary-shaped STR, including instance segmentation based text detection and language model based attention mechanism for text recognition. Our STR algorithm not only recognizes Latin and Non-Latin characters, but also supports arbitrary-shaped text recognition. Our method wins the championship on Scene Text Spotting Task (Latin Only, Latin and Chinese) of ICDAR2019 Robust Reading Challenge on ArbitraryShaped Text Competition. Code is available at https://github.com/zhang0jhon/AttentionOCR.