 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Numerical Hallucinations via Data-centric Compilation for Online Financial QA
May 29, 2026Large Language Models (LLMs) have significantly advanced online data services, particularly in the domain of financial question answering (FinQA). However, such systems remain susceptible to numerical reasoning hallucinations, which critically undermine reliability in high-stakes financial applications. Although retrieval-augmented generation (RAG) has been widely adopted to ground responses in external knowledge, it introduces three persistent challenges: noise sensitivity, calculation fragility, and an auditability crisis. Existing model-centric approaches, which primarily focus on optimizing either the retriever or generator in isolation, still struggle to address these issues in an integrated manner. In this work, we pioneer a data-centric paradigm and propose a novel framework, the Data-centric Reasoning Compiler (DCRC). The framework operates through three cohesive phases: (1) adversarial data construction, which synthesizes training examples with controlled noise to teach robustness; (2) multi-stage training that cultivates a Data-centric Structuring Agent (DSA) capable of explicit evidence auditing and program synthesis; and (3) a compile-and-execute inference process, where the DSA transforms user queries and retrieved documents into verifiable, executable reasoning programs. This data-driven framework ensures faithful numerical reasoning by design. We conduct extensive experiments on established offline benchmarks and further validate our framework through deployment in a real-world online financial QA system.
Looking Farther with Confidence: Uncertainty-Guided Future Learning for Sequential Recommendation
May 27, 2026Sequential recommendation effectively models dynamic user interests but continues to face challenges related to data sparsity. While self-supervised learning has alleviated this issue to some extent, most existing methods focus exclusively on immediate next-item prediction during training, thereby neglecting the rich information embedded in longer-term future interactions. Although a few studies have explored the utilization of future data, existing attempts typically apply future supervision signals with uniform intensity across all samples, which may lead to suboptimal solutions. In this paper, we propose an adaptive future learning framework, UFRec, which encourages the model to look further ahead when it is confident in the current state, while focusing on the immediate task when it is uncertain. Specifically, UFRec incorporates an Uncertainty-Guided Future Supervision module that dynamically modulates the weight of multi-step future supervision based on the model's confidence in the primary next-item prediction task. Furthermore, we complement step-wise future supervision with a Future-Aware Contrastive Learning module that treats the future trajectory as a holistic entity. Notably, both auxiliary modules are utilized exclusively during training and incur no inference overhead. Extensive experiments on four benchmark datasets demonstrate that our method significantly outperforms state-of-the-art approaches by effectively leveraging future data.
Data-Driven Function Calling Improvements in Large Language Model for Online Financial QA
Apr 07, 2026Large language models (LLMs) have been incorporated into numerous industrial applications. Meanwhile, a vast array of API assets is scattered across various functions in the financial domain. An online financial question-answering system can leverage both LLMs and private APIs to provide timely financial analysis and information. The key is equipping the LLM model with function calling capability tailored to a financial scenario. However, a generic LLM requires customized financial APIs to call and struggles to adapt to the financial domain. Additionally, online user queries are diverse and contain out-of-distribution parameters compared with the required function input parameters, which makes it more difficult for a generic LLM to serve online users. In this paper, we propose a data-driven pipeline to enhance function calling in LLM for our online, deployed financial QA, comprising dataset construction, data augmentation, and model training. Specifically, we construct a dataset based on a previous study and update it periodically, incorporating queries and an augmentation method named AugFC. The addition of user query-related samples will \textit{exploit} our financial toolset in a data-driven manner, and AugFC explores the possible parameter values to enhance the diversity of our updated dataset. Then, we train an LLM with a two-step method, which enables the use of our financial functions. Extensive experiments on existing offline datasets, as well as the deployment of an online scenario, illustrate the superiority of our pipeline. The related pipeline has been adopted in the financial QA of YuanBao\footnote{https://yuanbao.tencent.com/chat/}, one of the largest chat platforms in China.
Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting
Mar 26, 2026Existing feed-forward 3D Gaussian Splatting methods predict pixel-aligned primitives, leading to a quadratic growth in primitive count as resolution increases. This fundamentally limits their scalability, making high-resolution synthesis such as 4K intractable. We introduce LGTM (Less Gaussians, Texture More), a feed-forward framework that overcomes this resolution scaling barrier. By predicting compact Gaussian primitives coupled with per-primitive textures, LGTM decouples geometric complexity from rendering resolution. This approach enables high-fidelity 4K novel view synthesis without per-scene optimization, a capability previously out of reach for feed-forward methods, all while using significantly fewer Gaussian primitives. Project page: https://yxlao.github.io/lgtm/
Latent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving
Mar 25, 2026We introduce Latent-WAM, an efficient end-to-end autonomous driving framework that achieves strong trajectory planning through spatially-aware and dynamics-informed latent world representations. Existing world-model-based planners suffer from inadequately compressed representations, limited spatial understanding, and underutilized temporal dynamics, resulting in sub-optimal planning under constrained data and compute budgets. Latent-WAM addresses these limitations with two core modules: a Spatial-Aware Compressive World Encoder (SCWE) that distills geometric knowledge from a foundation model and compresses multi-view images into compact scene tokens via learnable queries, and a Dynamic Latent World Model (DLWM) that employs a causal Transformer to autoregressively predict future world status conditioned on historical visual and motion representations. Extensive experiments on NAVSIM v2 and HUGSIM demonstrate new state-of-the-art results: 89.3 EPDMS on NAVSIM v2 and 28.9 HD-Score on HUGSIM, surpassing the best prior perception-free method by 3.2 EPDMS with significantly less training data and a compact 104M-parameter model.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Nonlinearity as Rank: Generative Low-Rank Adapter with Radial Basis Functions
Feb 05, 2026Low-rank adaptation (LoRA) approximates the update of a pretrained weight matrix using the product of two low-rank matrices. However, standard LoRA follows an explicit-rank paradigm, where increasing model capacity requires adding more rows or columns (i.e., basis vectors) to the low-rank matrices, leading to substantial parameter growth. In this paper, we find that these basis vectors exhibit significant parameter redundancy and can be compactly represented by lightweight nonlinear functions. Therefore, we propose Generative Low-Rank Adapter (GenLoRA), which replaces explicit basis vector storage with nonlinear basis vector generation. Specifically, GenLoRA maintains a latent vector for each low-rank matrix and employs a set of lightweight radial basis functions (RBFs) to synthesize the basis vectors. Each RBF requires far fewer parameters than an explicit basis vector, enabling higher parameter efficiency in GenLoRA. Extensive experiments across multiple datasets and architectures show that GenLoRA attains higher effective LoRA ranks under smaller parameter budgets, resulting in superior fine-tuning performance. The code is available at https://anonymous.4open.science/r/GenLoRA-1519.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Automated Information Flow Selection for Multi-scenario Multi-task Recommendation
Dec 15, 2025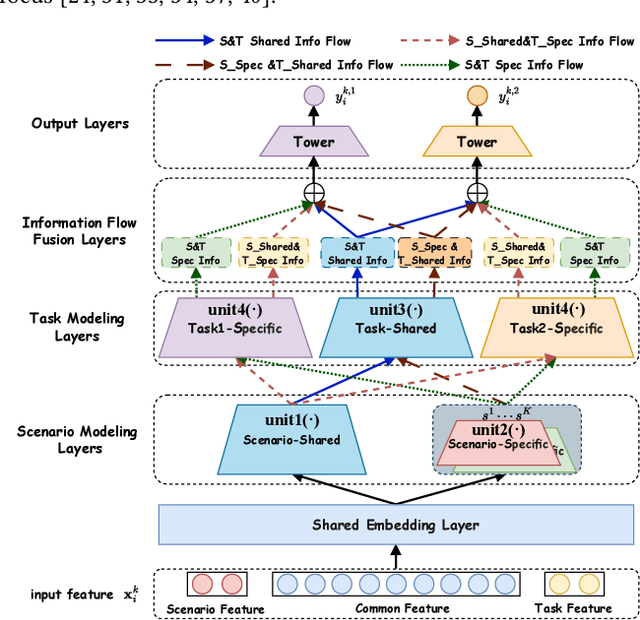
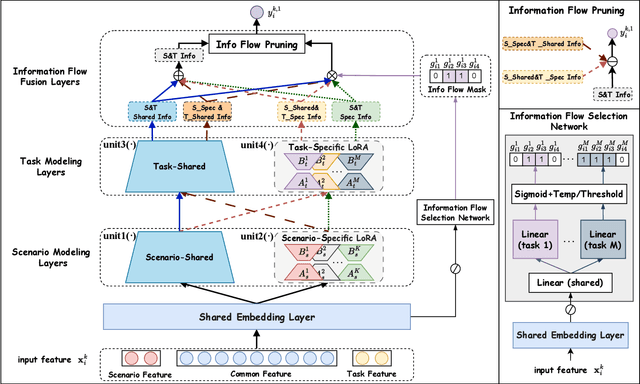
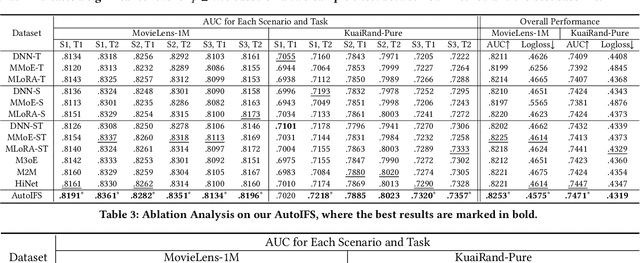
Multi-scenario multi-task recommendation (MSMTR) systems must address recommendation demands across diverse scenarios while simultaneously optimizing multiple objectives, such as click-through rate and conversion rate. Existing MSMTR models typically consist of four information units: scenario-shared, scenario-specific, task-shared, and task-specific networks. These units interact to generate four types of relationship information flows, directed from scenario-shared or scenario-specific networks to task-shared or task-specific networks. However, these models face two main limitations: 1) They often rely on complex architectures, such as mixture-of-experts (MoE) networks, which increase the complexity of information fusion, model size, and training cost. 2) They extract all available information flows without filtering out irrelevant or even harmful content, introducing potential noise. Regarding these challenges, we propose a lightweight Automated Information Flow Selection (AutoIFS) framework for MSMTR. To tackle the first issue, AutoIFS incorporates low-rank adaptation (LoRA) to decouple the four information units, enabling more flexible and efficient information fusion with minimal parameter overhead. To address the second issue, AutoIFS introduces an information flow selection network that automatically filters out invalid scenario-task information flows based on model performance feedback. It employs a simple yet effective pruning function to eliminate useless information flows, thereby enhancing the impact of key relationships and improving model performance. Finally, we evaluate AutoIFS and confirm its effectiveness through extensive experiments on two public benchmark datasets and an online A/B test.
Sharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp