 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployment-Oriented Session-wise Meta-Calibration for Landmark-Based Webcam Gaze Tracking
Mar 12, 2026Practical webcam gaze tracking is constrained not only by error, but also by calibration burden, robustness to head motion and session drift, runtime footprint, and browser use. We therefore target a deployment-oriented operating point rather than the image large-backbone regime. We cast landmark-based point-of-regard estimation as session-wise adaptation: a shared geometric encoder produces embeddings that can be aligned to a new session from a small calibration set. We present Equivariant Meta-Calibrated Gaze (EMC-Gaze), a lightweight landmark-only method combining an E(3)-equivariant landmark-graph encoder, local eye geometry, binocular emphasis, auxiliary 3D gaze-direction supervision, and a closed-form ridge calibrator differentiated through episodic meta-training. To reduce pose leakage, we use a two-view canonicalization consistency loss. The deployed predictor uses only facial landmarks and fits a per-session ridge head from brief calibration. In a fixation-style interactive evaluation over 33 sessions at 100 cm, EMC-Gaze achieves 5.79 +/- 1.81 deg RMSE after 9-point calibration versus 6.68 +/- 2.34 deg for Elastic Net; the gain is larger on still-head queries (2.92 +/- 0.75 deg vs. 4.45 +/- 0.30 deg). Across three subject holdouts of 10 subjects each, EMC-Gaze retains an advantage (5.66 +/- 0.19 deg vs. 6.49 +/- 0.33 deg). On MPIIFaceGaze with short per-session calibration, the eye-focused model reaches 8.82 +/- 1.21 deg at 16-shot calibration, ties Elastic Net at 1-shot, and outperforms it from 3-shot onward. The exported eye-focused encoder has 944,423 parameters, is 4.76 MB in ONNX, and supports calibrated browser prediction in 12.58/12.58/12.90 ms per sample (mean/median/p90) in Chromium 145 with ONNX Runtime Web. These results position EMC-Gaze as a calibration-friendly operating point rather than a universal state-of-the-art claim against heavier appearance-based systems.
LIBERO-X: Robustness Litmus for Vision-Language-Action Models
Feb 06, 2026Reliable benchmarking is critical for advancing Vision-Language-Action (VLA) models, as it reveals their generalization, robustness, and alignment of perception with language-driven manipulation tasks. However, existing benchmarks often provide limited or misleading assessments due to insufficient evaluation protocols that inadequately capture real-world distribution shifts. This work systematically rethinks VLA benchmarking from both evaluation and data perspectives, introducing LIBERO-X, a benchmark featuring: 1) A hierarchical evaluation protocol with progressive difficulty levels targeting three core capabilities: spatial generalization, object recognition, and task instruction understanding. This design enables fine-grained analysis of performance degradation under increasing environmental and task complexity; 2) A high-diversity training dataset collected via human teleoperation, where each scene supports multiple fine-grained manipulation objectives to bridge the train-evaluation distribution gap. Experiments with representative VLA models reveal significant performance drops under cumulative perturbations, exposing persistent limitations in scene comprehension and instruction grounding. By integrating hierarchical evaluation with diverse training data, LIBERO-X offers a more reliable foundation for assessing and advancing VLA development.
SemanticForge: Repository-Level Code Generation through Semantic Knowledge Graphs and Constraint Satisfaction
Nov 10, 2025Large language models (LLMs) have transformed software development by enabling automated code generation, yet they frequently suffer from systematic errors that limit practical deployment. We identify two critical failure modes: \textit{logical hallucination} (incorrect control/data-flow reasoning) and \textit{schematic hallucination} (type mismatches, signature violations, and architectural inconsistencies). These errors stem from the absence of explicit, queryable representations of repository-wide semantics. This paper presents \textbf{SemanticForge}, which introduces four fundamental algorithmic advances for semantically-aware code generation: (1) a novel automatic reconciliation algorithm for dual static-dynamic knowledge graphs, unifying compile-time and runtime program semantics; (2) a neural approach that learns to generate structured graph queries from natural language, achieving 73\% precision versus 51\% for traditional retrieval; (3) a novel beam search algorithm with integrated SMT solving, enabling real-time constraint verification during generation rather than post-hoc validation; and (4) an incremental maintenance algorithm that updates knowledge graphs in $O(|ΔR| \cdot \log n)$ time while maintaining semantic equivalence.
GODBench: A Benchmark for Multimodal Large Language Models in Video Comment Art
May 16, 2025Video Comment Art enhances user engagement by providing creative content that conveys humor, satire, or emotional resonance, requiring a nuanced and comprehensive grasp of cultural and contextual subtleties. Although Multimodal Large Language Models (MLLMs) and Chain-of-Thought (CoT) have demonstrated strong reasoning abilities in STEM tasks (e.g. mathematics and coding), they still struggle to generate creative expressions such as resonant jokes and insightful satire. Moreover, existing benchmarks are constrained by their limited modalities and insufficient categories, hindering the exploration of comprehensive creativity in video-based Comment Art creation. To address these limitations, we introduce GODBench, a novel benchmark that integrates video and text modalities to systematically evaluate MLLMs' abilities to compose Comment Art. Furthermore, inspired by the propagation patterns of waves in physics, we propose Ripple of Thought (RoT), a multi-step reasoning framework designed to enhance the creativity of MLLMs. Extensive experiments reveal that existing MLLMs and CoT methods still face significant challenges in understanding and generating creative video comments. In contrast, RoT provides an effective approach to improve creative composing, highlighting its potential to drive meaningful advancements in MLLM-based creativity. GODBench is publicly available at https://github.com/stan-lei/GODBench-ACL2025.
SeriesBench: A Benchmark for Narrative-Driven Drama Series Understanding
Apr 30, 2025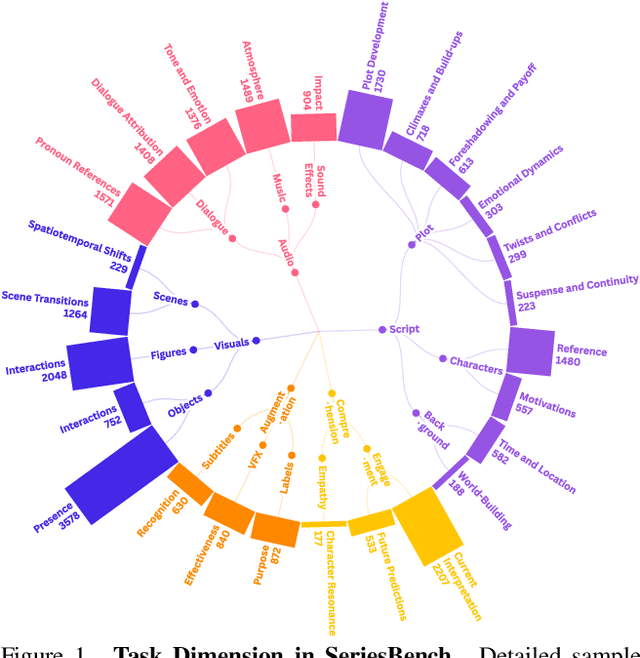

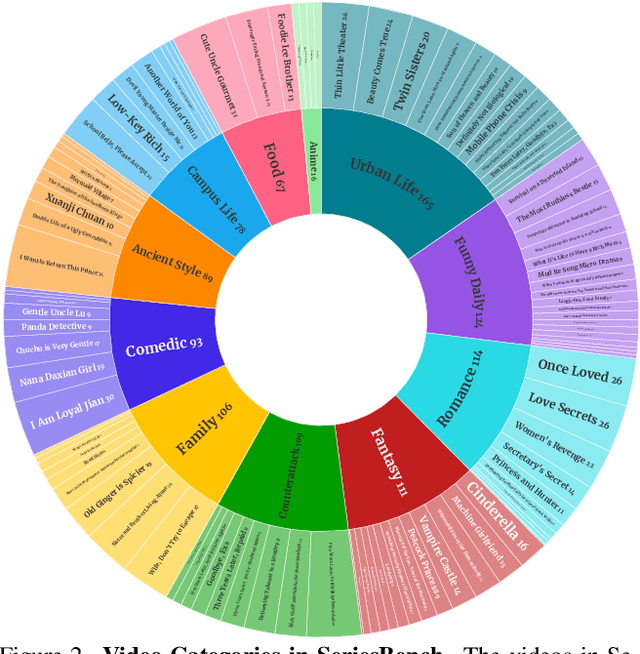
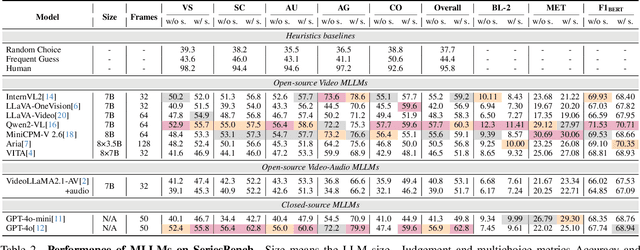
With the rapid development of Multi-modal Large Language Models (MLLMs), an increasing number of benchmarks have been established to evaluate the video understanding capabilities of these models. However, these benchmarks focus on \textbf{standalone} videos and mainly assess ``visual elements'' like human actions and object states. In reality, contemporary videos often encompass complex and continuous narratives, typically presented as a \textbf{series}. To address this challenge, we propose \textbf{SeriesBench}, a benchmark consisting of 105 carefully curated narrative-driven series, covering 28 specialized tasks that require deep narrative understanding. Specifically, we first select a diverse set of drama series spanning various genres. Then, we introduce a novel long-span narrative annotation method, combined with a full-information transformation approach to convert manual annotations into diverse task formats. To further enhance model capacity for detailed analysis of plot structures and character relationships within series, we propose a novel narrative reasoning framework, \textbf{PC-DCoT}. Extensive results on \textbf{SeriesBench} indicate that existing MLLMs still face significant challenges in understanding narrative-driven series, while \textbf{PC-DCoT} enables these MLLMs to achieve performance improvements. Overall, our \textbf{SeriesBench} and \textbf{PC-DCoT} highlight the critical necessity of advancing model capabilities to understand narrative-driven series, guiding the future development of MLLMs. SeriesBench is publicly available at https://github.com/zackhxn/SeriesBench-CVPR2025.
A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
Mar 28, 2025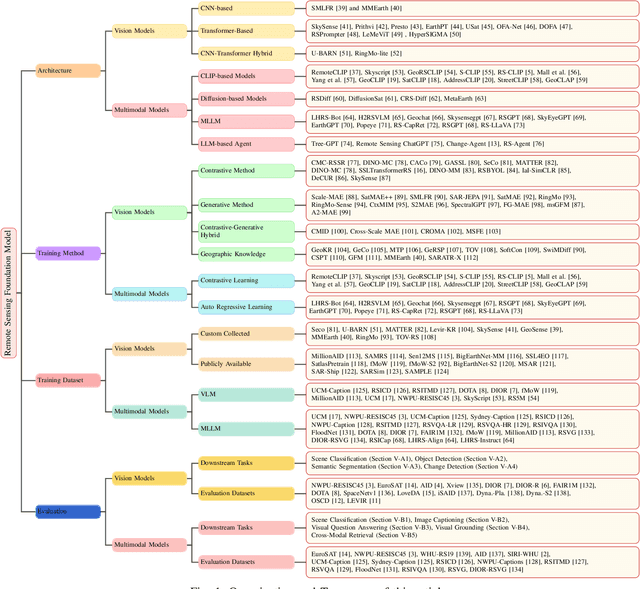
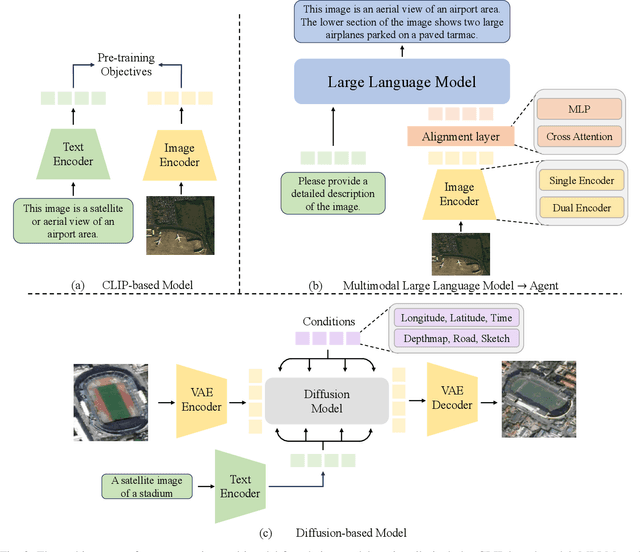

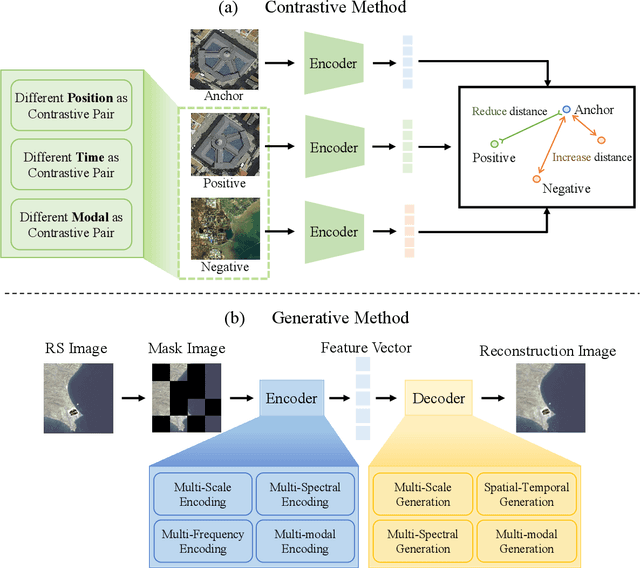
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.
KwaiChat: A Large-Scale Video-Driven Multilingual Mixed-Type Dialogue Corpus
Mar 10, 2025Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.
A Survey on Data Synthesis and Augmentation for Large Language Models
Oct 16, 2024The success of Large Language Models (LLMs) is inherently linked to the availability of vast, diverse, and high-quality data for training and evaluation. However, the growth rate of high-quality data is significantly outpaced by the expansion of training datasets, leading to a looming data exhaustion crisis. This underscores the urgent need to enhance data efficiency and explore new data sources. In this context, synthetic data has emerged as a promising solution. Currently, data generation primarily consists of two major approaches: data augmentation and synthesis. This paper comprehensively reviews and summarizes data generation techniques throughout the lifecycle of LLMs, including data preparation, pre-training, fine-tuning, instruction-tuning, preference alignment, and applications. Furthermore, We discuss the current constraints faced by these methods and investigate potential pathways for future development and research. Our aspiration is to equip researchers with a clear understanding of these methodologies, enabling them to swiftly identify appropriate data generation strategies in the construction of LLMs, while providing valuable insights for future exploration.
Generalizable Semantic Vision Query Generation for Zero-shot Panoptic and Semantic Segmentation
Feb 21, 2024



Zero-shot Panoptic Segmentation (ZPS) aims to recognize foreground instances and background stuff without images containing unseen categories in training. Due to the visual data sparsity and the difficulty of generalizing from seen to unseen categories, this task remains challenging. To better generalize to unseen classes, we propose Conditional tOken aligNment and Cycle trAnsiTion (CONCAT), to produce generalizable semantic vision queries. First, a feature extractor is trained by CON to link the vision and semantics for providing target queries. Formally, CON is proposed to align the semantic queries with the CLIP visual CLS token extracted from complete and masked images. To address the lack of unseen categories, a generator is required. However, one of the gaps in synthesizing pseudo vision queries, ie, vision queries for unseen categories, is describing fine-grained visual details through semantic embeddings. Therefore, we approach CAT to train the generator in semantic-vision and vision-semantic manners. In semantic-vision, visual query contrast is proposed to model the high granularity of vision by pulling the pseudo vision queries with the corresponding targets containing segments while pushing those without segments away. To ensure the generated queries retain semantic information, in vision-semantic, the pseudo vision queries are mapped back to semantic and supervised by real semantic embeddings. Experiments on ZPS achieve a 5.2% hPQ increase surpassing SOTA. We also examine inductive ZPS and open-vocabulary semantic segmentation and obtain comparative results while being 2 times faster in testing.
CLIP Is Also a Good Teacher: A New Learning Framework for Inductive Zero-shot Semantic Segmentation
Oct 03, 2023Existing Generalized Zero-shot Semantic Segmentation (GZLSS) methods apply either finetuning the CLIP paradigm or formulating it as a mask classification task, benefiting from the Vision-Language Models (VLMs). However, the fine-tuning methods are restricted with fixed backbone models which are not flexible for segmentation, and mask classification methods heavily rely on additional explicit mask proposers. Meanwhile, prevalent methods utilize only seen categories which is a great waste, i.e., neglecting the area exists but not annotated. To this end, we propose CLIPTeacher, a new learning framework that can be applied to various per-pixel classification segmentation models without introducing any explicit mask proposer or changing the structure of CLIP, and utilize both seen and ignoring areas. Specifically, CLIPTeacher consists of two key modules: Global Learning Module (GLM) and Pixel Learning Module (PLM). Specifically, GLM aligns the dense features from an image encoder with the CLS token, i.e., the only token trained in CLIP, which is a simple but effective way to probe global information from the CLIP models. In contrast, PLM only leverages dense tokens from CLIP to produce high-level pseudo annotations for ignoring areas without introducing any extra mask proposer. Meanwhile, PLM can fully take advantage of the whole image based on the pseudo annotations. Experimental results on three benchmark datasets: PASCAL VOC 2012, COCO-Stuff 164k, and PASCAL Context show large performance gains, i.e., 2.2%, 1.3%, and 8.8%