 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit Matching for Inductive Zero-shot Semantic Segmentation
May 08, 2025Zero-shot Semantic Segmentation (ZSS) aims to segment categories that are not annotated during training. While fine-tuning vision-language models has achieved promising results, these models often overfit to seen categories due to the lack of supervision for unseen classes. As an alternative to fully supervised approaches, query-based segmentation has shown great latent in ZSS, as it enables object localization without relying on explicit labels. However, conventional Hungarian matching, a core component in query-based frameworks, needs full supervision and often misclassifies unseen categories as background in the setting of ZSS. To address this issue, we propose Split Matching (SM), a novel assignment strategy that decouples Hungarian matching into two components: one for seen classes in annotated regions and another for latent classes in unannotated regions (referred to as unseen candidates). Specifically, we partition the queries into seen and candidate groups, enabling each to be optimized independently according to its available supervision. To discover unseen candidates, we cluster CLIP dense features to generate pseudo masks and extract region-level embeddings using CLS tokens. Matching is then conducted separately for the two groups based on both class-level similarity and mask-level consistency. Additionally, we introduce a Multi-scale Feature Enhancement (MFE) module that refines decoder features through residual multi-scale aggregation, improving the model's ability to capture spatial details across resolutions. SM is the first to introduce decoupled Hungarian matching under the inductive ZSS setting, and achieves state-of-the-art performance on two standard benchmarks.
CQVPR: Landmark-aware Contextual Queries for Visual Place Recognition
Mar 11, 2025
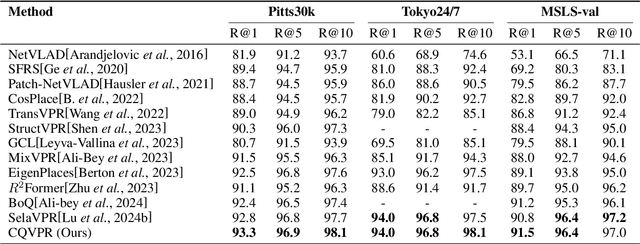


Visual Place Recognition (VPR) aims to estimate the location of the given query image within a database of geo-tagged images. To identify the exact location in an image, detecting landmarks is crucial. However, in some scenarios, such as urban environments, there are numerous landmarks, such as various modern buildings, and the landmarks in different cities often exhibit high visual similarity. Therefore, it is essential not only to leverage the landmarks but also to consider the contextual information surrounding them, such as whether there are trees, roads, or other features around the landmarks. We propose the Contextual Query VPR (CQVPR), which integrates contextual information with detailed pixel-level visual features. By leveraging a set of learnable contextual queries, our method automatically learns the high-level contexts with respect to landmarks and their surrounding areas. Heatmaps depicting regions that each query attends to serve as context-aware features, offering cues that could enhance the understanding of each scene. We further propose a query matching loss to supervise the extraction process of contextual queries. Extensive experiments on several datasets demonstrate that the proposed method outperforms other state-of-the-art methods, especially in challenging scenarios.
Generalizable Semantic Vision Query Generation for Zero-shot Panoptic and Semantic Segmentation
Feb 21, 2024



Zero-shot Panoptic Segmentation (ZPS) aims to recognize foreground instances and background stuff without images containing unseen categories in training. Due to the visual data sparsity and the difficulty of generalizing from seen to unseen categories, this task remains challenging. To better generalize to unseen classes, we propose Conditional tOken aligNment and Cycle trAnsiTion (CONCAT), to produce generalizable semantic vision queries. First, a feature extractor is trained by CON to link the vision and semantics for providing target queries. Formally, CON is proposed to align the semantic queries with the CLIP visual CLS token extracted from complete and masked images. To address the lack of unseen categories, a generator is required. However, one of the gaps in synthesizing pseudo vision queries, ie, vision queries for unseen categories, is describing fine-grained visual details through semantic embeddings. Therefore, we approach CAT to train the generator in semantic-vision and vision-semantic manners. In semantic-vision, visual query contrast is proposed to model the high granularity of vision by pulling the pseudo vision queries with the corresponding targets containing segments while pushing those without segments away. To ensure the generated queries retain semantic information, in vision-semantic, the pseudo vision queries are mapped back to semantic and supervised by real semantic embeddings. Experiments on ZPS achieve a 5.2% hPQ increase surpassing SOTA. We also examine inductive ZPS and open-vocabulary semantic segmentation and obtain comparative results while being 2 times faster in testing.
CLIP Is Also a Good Teacher: A New Learning Framework for Inductive Zero-shot Semantic Segmentation
Oct 03, 2023Existing Generalized Zero-shot Semantic Segmentation (GZLSS) methods apply either finetuning the CLIP paradigm or formulating it as a mask classification task, benefiting from the Vision-Language Models (VLMs). However, the fine-tuning methods are restricted with fixed backbone models which are not flexible for segmentation, and mask classification methods heavily rely on additional explicit mask proposers. Meanwhile, prevalent methods utilize only seen categories which is a great waste, i.e., neglecting the area exists but not annotated. To this end, we propose CLIPTeacher, a new learning framework that can be applied to various per-pixel classification segmentation models without introducing any explicit mask proposer or changing the structure of CLIP, and utilize both seen and ignoring areas. Specifically, CLIPTeacher consists of two key modules: Global Learning Module (GLM) and Pixel Learning Module (PLM). Specifically, GLM aligns the dense features from an image encoder with the CLS token, i.e., the only token trained in CLIP, which is a simple but effective way to probe global information from the CLIP models. In contrast, PLM only leverages dense tokens from CLIP to produce high-level pseudo annotations for ignoring areas without introducing any extra mask proposer. Meanwhile, PLM can fully take advantage of the whole image based on the pseudo annotations. Experimental results on three benchmark datasets: PASCAL VOC 2012, COCO-Stuff 164k, and PASCAL Context show large performance gains, i.e., 2.2%, 1.3%, and 8.8%
SDOF-Tracker: Fast and Accurate Multiple Human Tracking by Skipped-Detection and Optical-Flow
Jun 29, 2021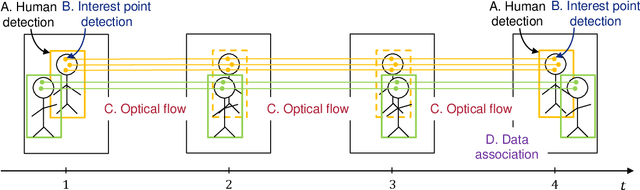
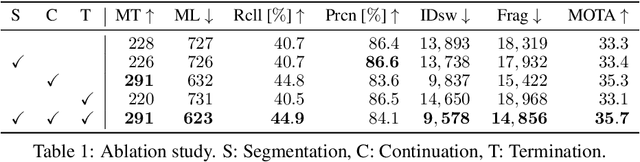
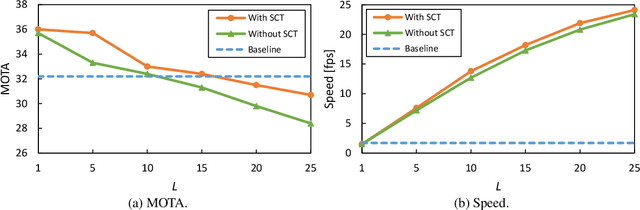
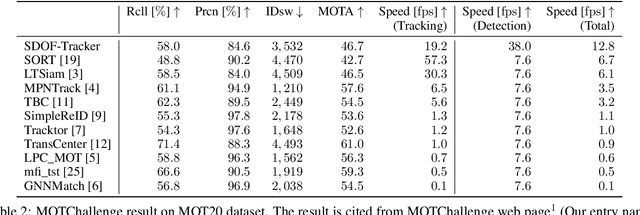
Multiple human tracking is a fundamental problem for scene understanding. Although both accuracy and speed are required in real-world applications, recent tracking methods based on deep learning have focused on accuracy and require substantial running time. This study aims to improve running speed by performing human detection at a certain frame interval because it accounts for most of the running time. The question is how to maintain accuracy while skipping human detection. In this paper, we propose a method that complements the detection results with optical flow, based on the fact that someone's appearance does not change much between adjacent frames. To maintain the tracking accuracy, we introduce robust interest point selection within human regions and a tracking termination metric calculated by the distribution of the interest points. On the MOT20 dataset in the MOTChallenge, the proposed SDOF-Tracker achieved the best performance in terms of the total running speed while maintaining the MOTA metric. Our code is available at https://anonymous.4open.science/r/sdof-tracker-75AE.
Interaction Detection Between Vehicles and Vulnerable Road Users: A Deep Generative Approach with Attention
May 09, 2021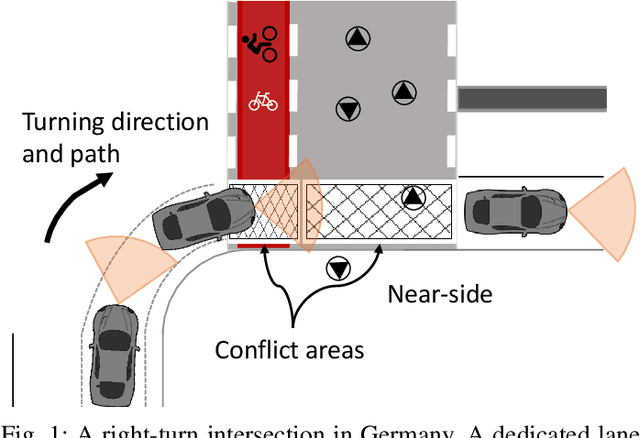
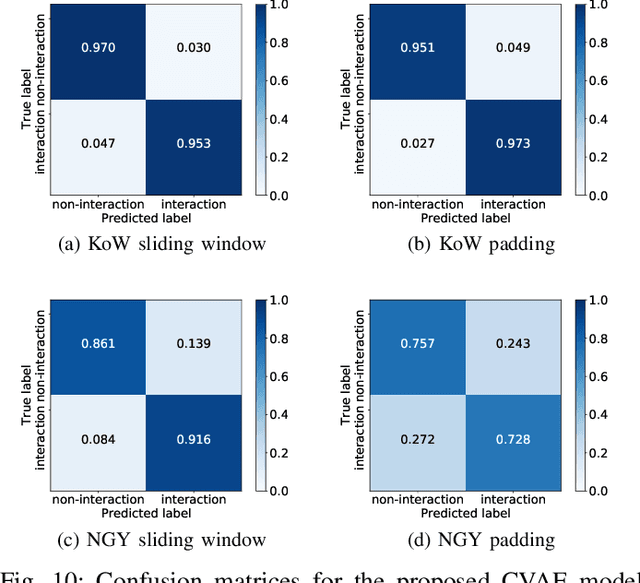
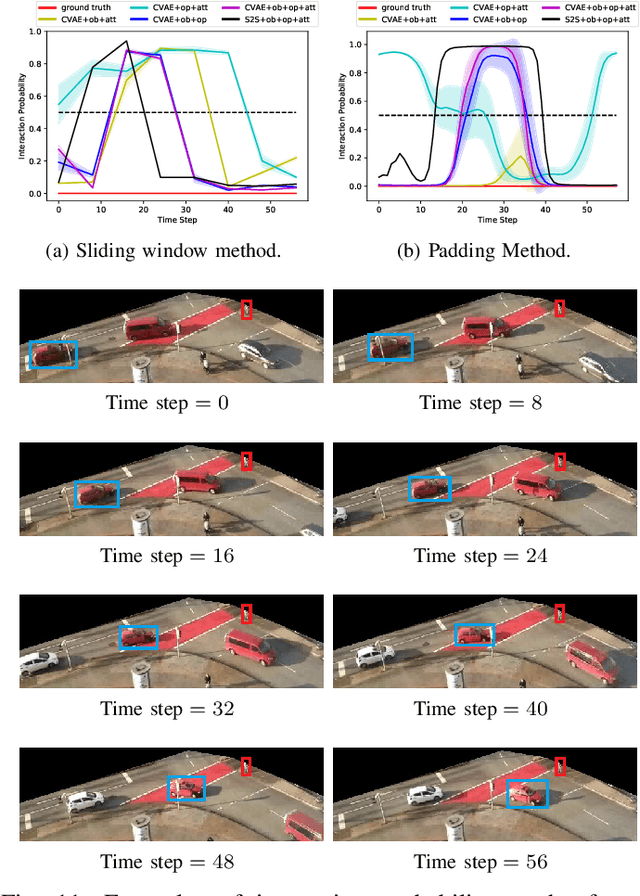
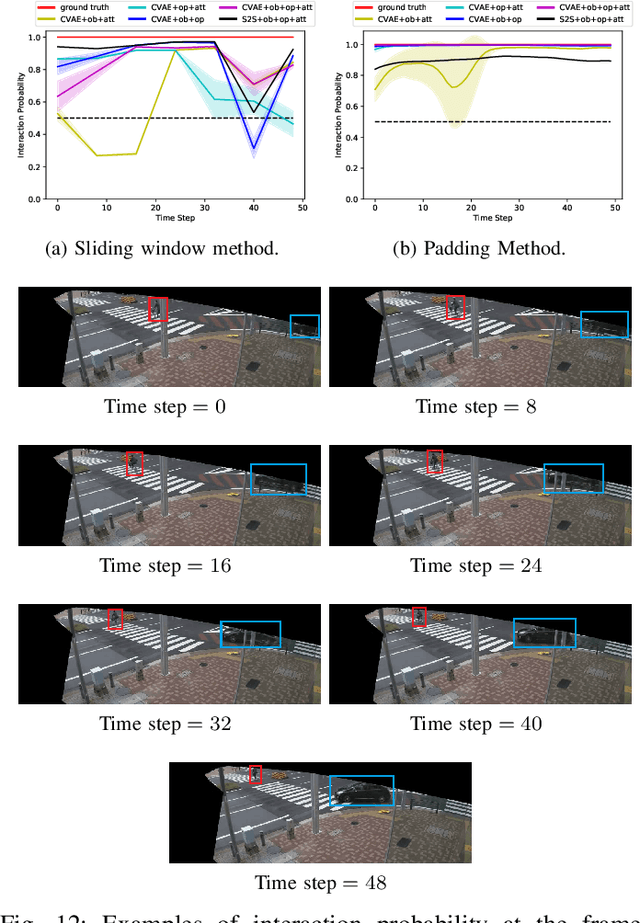
Intersections where vehicles are permitted to turn and interact with vulnerable road users (VRUs) like pedestrians and cyclists are among some of the most challenging locations for automated and accurate recognition of road users' behavior. In this paper, we propose a deep conditional generative model for interaction detection at such locations. It aims to automatically analyze massive video data about the continuity of road users' behavior. This task is essential for many intelligent transportation systems such as traffic safety control and self-driving cars that depend on the understanding of road users' locomotion. A Conditional Variational Auto-Encoder based model with Gaussian latent variables is trained to encode road users' behavior and perform probabilistic and diverse predictions of interactions. The model takes as input the information of road users' type, position and motion automatically extracted by a deep learning object detector and optical flow from videos, and generates frame-wise probabilities that represent the dynamics of interactions between a turning vehicle and any VRUs involved. The model's efficacy was validated by testing on real--world datasets acquired from two different intersections. It achieved an F1-score above 0.96 at a right--turn intersection in Germany and 0.89 at a left--turn intersection in Japan, both with very busy traffic flows.
Multiple Human Tracking using Multi-Cues including Primitive Action Features
Sep 18, 2019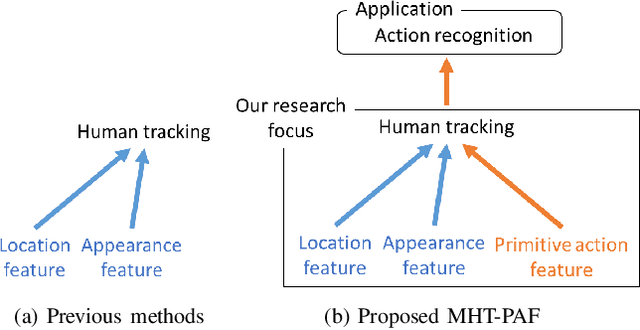
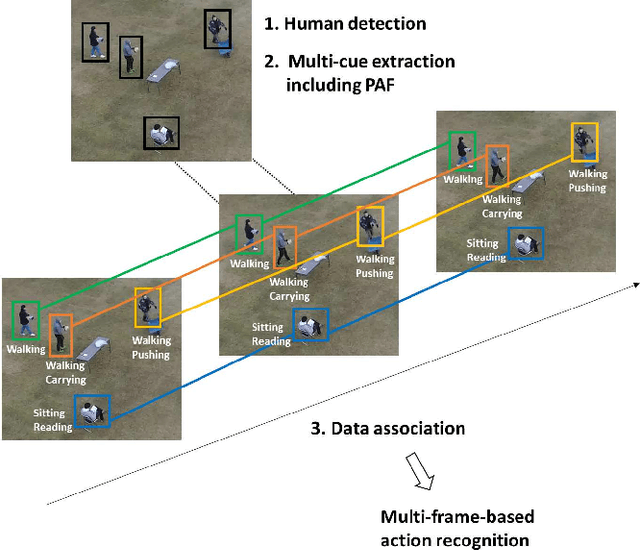
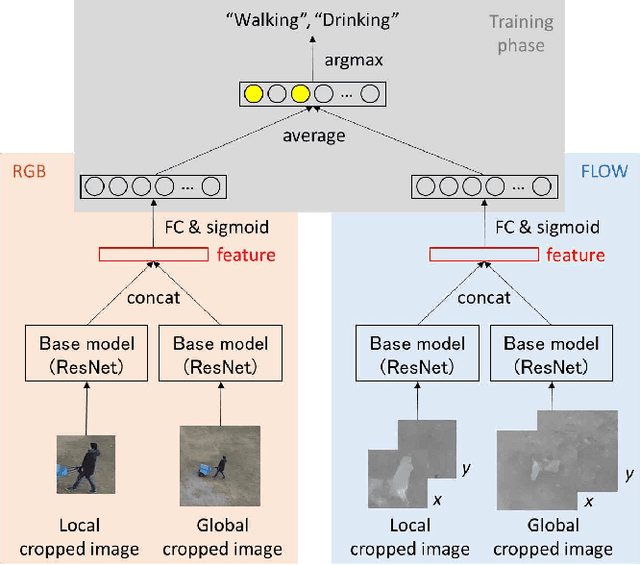
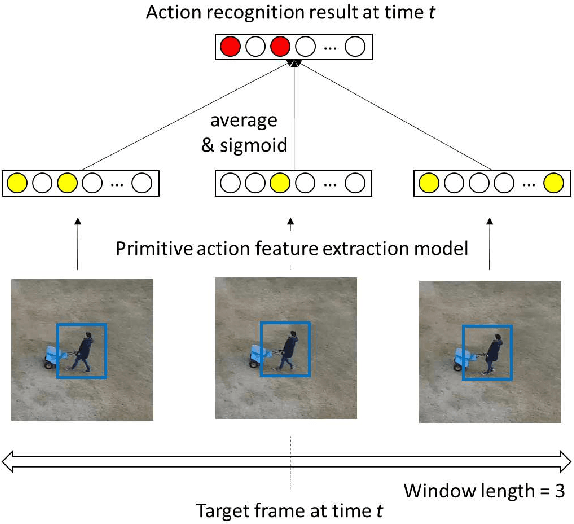
In this paper, we propose a Multiple Human Tracking method using multi-cues including Primitive Action Features (MHT-PAF). MHT-PAF can perform the accurate human tracking in dynamic aerial videos captured by a drone. PAF employs a global context, rich information by multi-label actions, and a middle level feature. The accurate human tracking result using PAF helps multi-frame-based action recognition. In the experiments, we verified the effectiveness of the proposed method using the Okutama-Action dataset. Our code is available online.