 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Path-following Control of Remotely Operated Underwater Robots for Human Visual Inspection Task
Mar 25, 2022
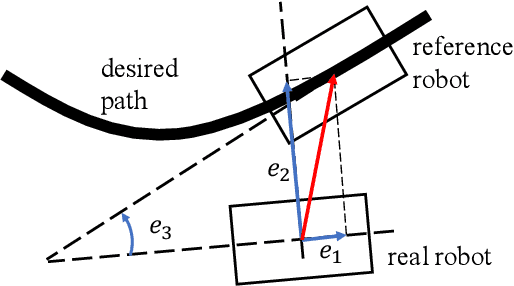
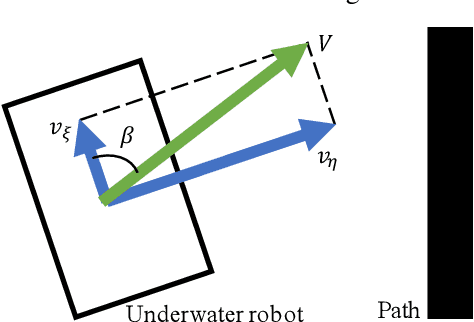
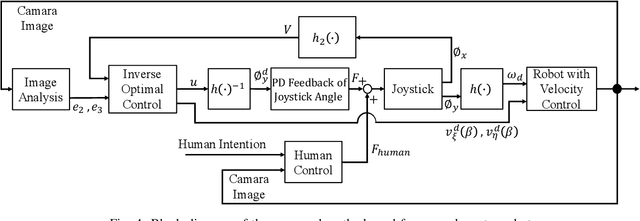
Remotely operated vehicles (ROVs) have drawn much attention to underwater tasks, such as the inspection and maintenance of infrastructure. The workload of ROV operators tends to be high, even for the skilled ones. Therefore, assistance methods for the operators are desired. This study focuses on a task in which a human operator controls an underwater robot to follow a certain path while visually inspecting objects in the vicinity of the path. In such a task, it is desirable to realize the speed of trajectory control manually because the visual inspection is performed by a human operator. However, to allocate resources to visual inspection, it is desirable to minimize the workload on the path-following by assisting with the automatic control. Therefore, the objective of this study was to develop a cooperative path-following control method that achieves the above-mentioned task by expanding a robust path-following control law of nonholonomic wheeled vehicles. To simplify this problem, we considered a path-following and visual objects recognition task in a two-dimensional plane. We conducted an experiment with participants (n=16) who completed the task using the proposed method and manual control. The results showed that both the path-following errors and the workload of the participants were significantly smaller with the proposed method than with manual control. In addition, subjective responses demonstrated that operator attention tended to be allocated to objects recognition rather than robot operation tasks with the proposed method. These results indicate the effectiveness of the proposed cooperative path-following control method.
Motion Sickness Modeling with Visual Vertical Estimation and Its Application to Autonomous Personal Mobility Vehicles
Feb 20, 2022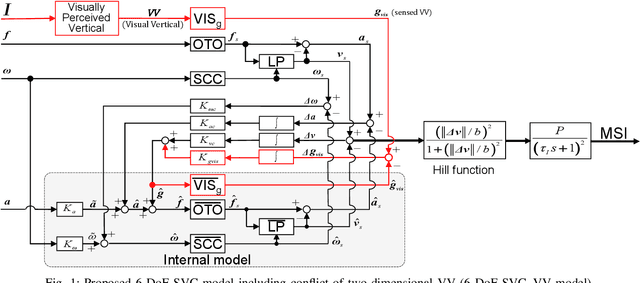


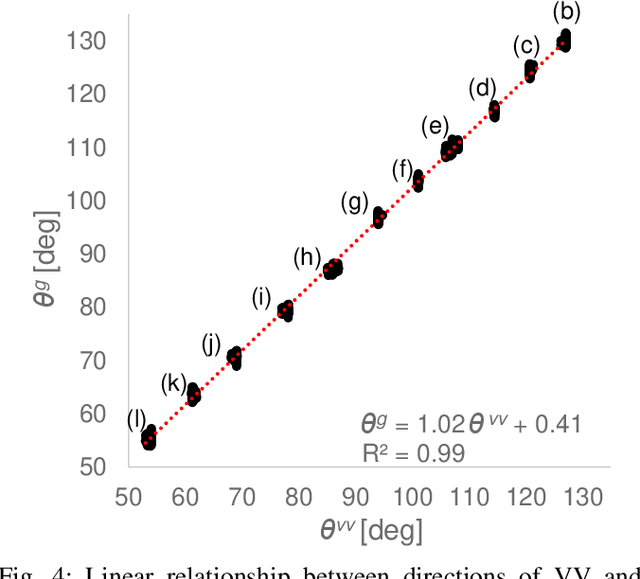
Passengers (drivers) of level 3-5 autonomous personal mobility vehicles (APMV) and cars can perform non-driving tasks, such as reading books and smartphones, while driving. It has been pointed out that such activities may increase motion sickness. Many studies have been conducted to build countermeasures, of which various computational motion sickness models have been developed. Many of these are based on subjective vertical conflict (SVC) theory, which describes vertical changes in direction sensed by human sensory organs vs. those expected by the central nervous system. Such models are expected to be applied to autonomous driving scenarios. However, no current computational model can integrate visual vertical information with vestibular sensations. We proposed a 6 DoF SVC-VV model which add a visually perceived vertical block into a conventional six-degrees-of-freedom SVC model to predict VV directions from image data simulating the visual input of a human. Hence, a simple image-based VV estimation method is proposed. As the validation of the proposed model, this paper focuses on describing the fact that the motion sickness increases as a passenger reads a book while using an AMPV, assuming that visual vertical (VV) plays an important role. In the static experiment, it is demonstrated that the estimated VV by the proposed method accurately described the gravitational acceleration direction with a low mean absolute deviation. In addition, the results of the driving experiment using an APMV demonstrated that the proposed 6 DoF SVC-VV model could describe that the increased motion sickness experienced when the VV and gravitational acceleration directions were different.
Interaction Detection Between Vehicles and Vulnerable Road Users: A Deep Generative Approach with Attention
May 09, 2021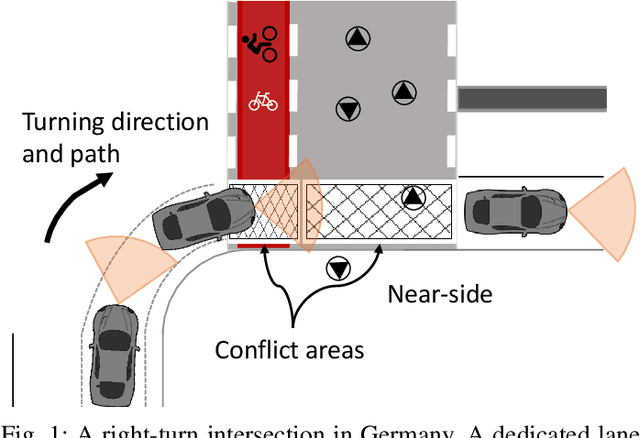
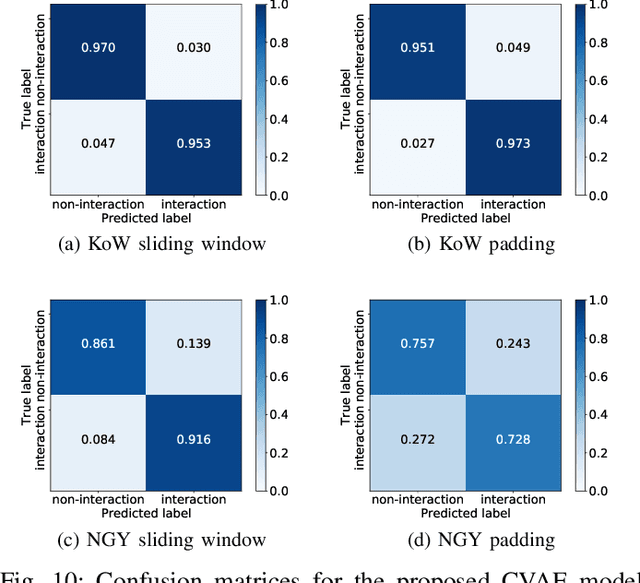
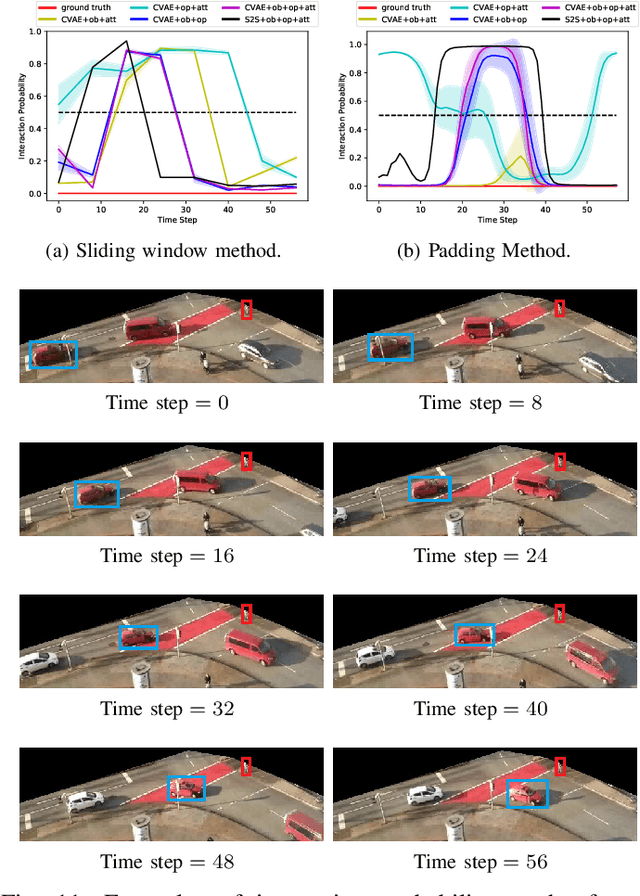
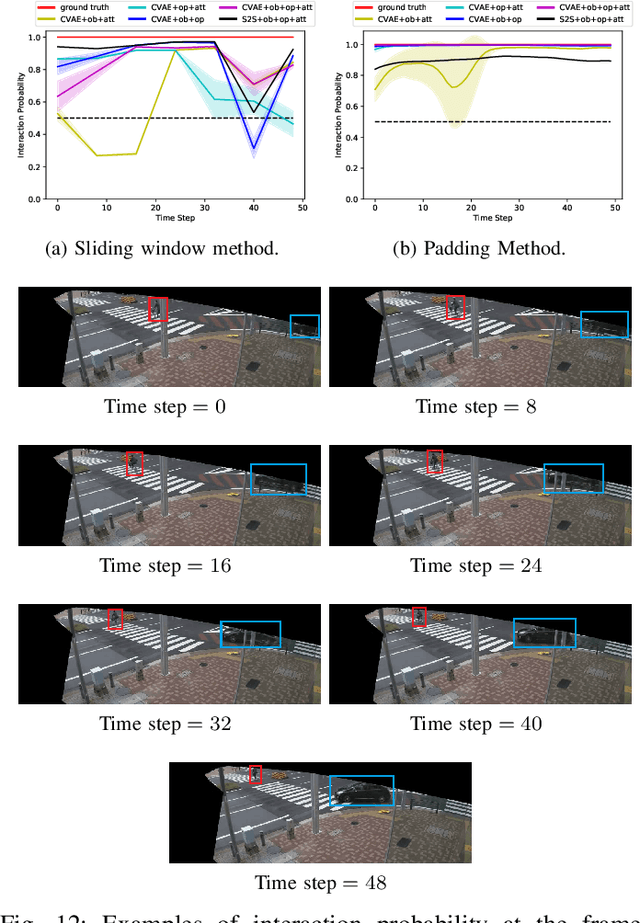
Intersections where vehicles are permitted to turn and interact with vulnerable road users (VRUs) like pedestrians and cyclists are among some of the most challenging locations for automated and accurate recognition of road users' behavior. In this paper, we propose a deep conditional generative model for interaction detection at such locations. It aims to automatically analyze massive video data about the continuity of road users' behavior. This task is essential for many intelligent transportation systems such as traffic safety control and self-driving cars that depend on the understanding of road users' locomotion. A Conditional Variational Auto-Encoder based model with Gaussian latent variables is trained to encode road users' behavior and perform probabilistic and diverse predictions of interactions. The model takes as input the information of road users' type, position and motion automatically extracted by a deep learning object detector and optical flow from videos, and generates frame-wise probabilities that represent the dynamics of interactions between a turning vehicle and any VRUs involved. The model's efficacy was validated by testing on real--world datasets acquired from two different intersections. It achieved an F1-score above 0.96 at a right--turn intersection in Germany and 0.89 at a left--turn intersection in Japan, both with very busy traffic flows.