 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Sickness Modeling with Visual Vertical Estimation and Its Application to Autonomous Personal Mobility Vehicles
Feb 20, 2022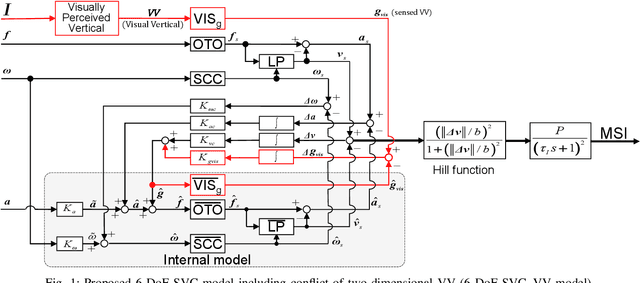


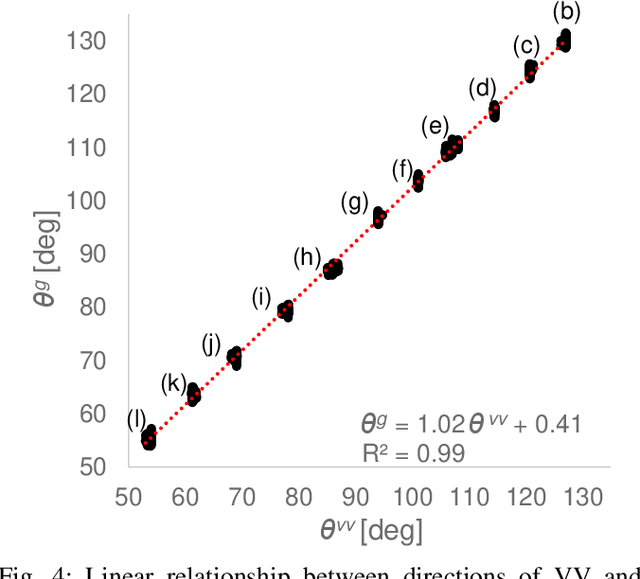
Passengers (drivers) of level 3-5 autonomous personal mobility vehicles (APMV) and cars can perform non-driving tasks, such as reading books and smartphones, while driving. It has been pointed out that such activities may increase motion sickness. Many studies have been conducted to build countermeasures, of which various computational motion sickness models have been developed. Many of these are based on subjective vertical conflict (SVC) theory, which describes vertical changes in direction sensed by human sensory organs vs. those expected by the central nervous system. Such models are expected to be applied to autonomous driving scenarios. However, no current computational model can integrate visual vertical information with vestibular sensations. We proposed a 6 DoF SVC-VV model which add a visually perceived vertical block into a conventional six-degrees-of-freedom SVC model to predict VV directions from image data simulating the visual input of a human. Hence, a simple image-based VV estimation method is proposed. As the validation of the proposed model, this paper focuses on describing the fact that the motion sickness increases as a passenger reads a book while using an AMPV, assuming that visual vertical (VV) plays an important role. In the static experiment, it is demonstrated that the estimated VV by the proposed method accurately described the gravitational acceleration direction with a low mean absolute deviation. In addition, the results of the driving experiment using an APMV demonstrated that the proposed 6 DoF SVC-VV model could describe that the increased motion sickness experienced when the VV and gravitational acceleration directions were different.
Adversarial attacks on audio source separation
Oct 09, 2020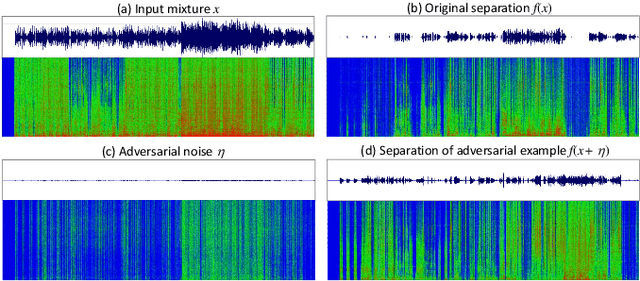

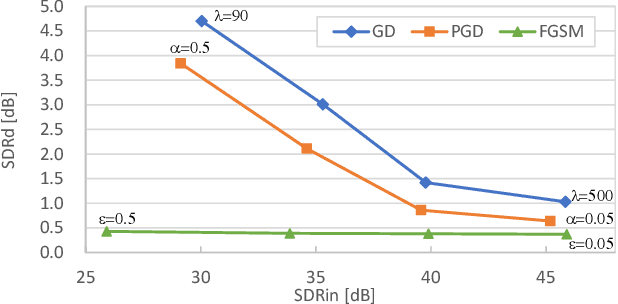
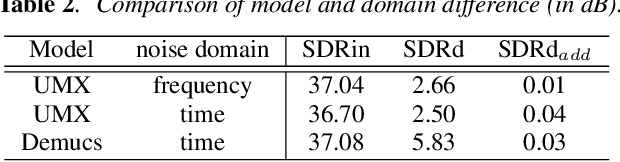
Despite the excellent performance of neural-network-based audio source separation methods and their wide range of applications, their robustness against intentional attacks has been largely neglected. In this work, we reformulate various adversarial attack methods for the audio source separation problem and intensively investigate them under different attack conditions and target models. We further propose a simple yet effective regularization method to obtain imperceptible adversarial noise while maximizing the impact on separation quality with low computational complexity. Experimental results show that it is possible to largely degrade the separation quality by adding imperceptibly small noise when the noise is crafted for the target model. We also show the robustness of source separation models against a black-box attack. This study provides potentially useful insights for developing content protection methods against the abuse of separated signals and improving the separation performance and robustness.
Semi-blind source separation with multichannel variational autoencoder
Aug 26, 2018
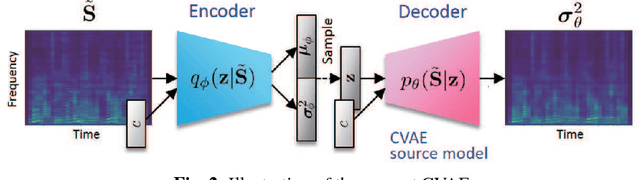
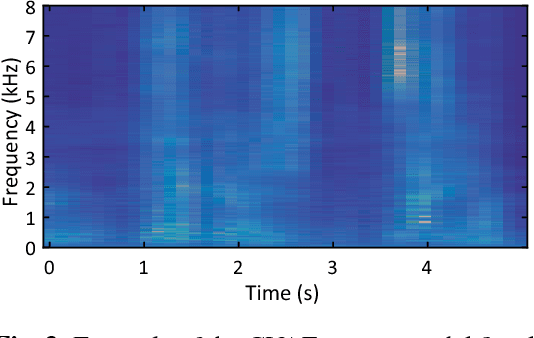
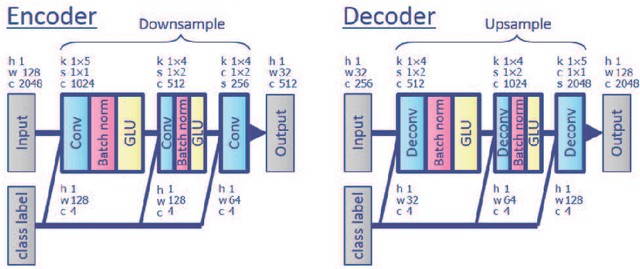
This paper proposes a multichannel source separation technique called the multichannel variational autoencoder (MVAE) method, which uses a conditional VAE (CVAE) to model and estimate the power spectrograms of the sources in a mixture. By training the CVAE using the spectrograms of training examples with source-class labels, we can use the trained decoder distribution as a universal generative model capable of generating spectrograms conditioned on a specified class label. By treating the latent space variables and the class label as the unknown parameters of this generative model, we can develop a convergence-guaranteed semi-blind source separation algorithm that consists of iteratively estimating the power spectrograms of the underlying sources as well as the separation matrices. In experimental evaluations, our MVAE produced better separation performance than a baseline method.