 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMOL-MapSeg: Show Me One Label
Aug 07, 2025Historical maps are valuable for studying changes to the Earth's surface. With the rise of deep learning, models like UNet have been used to extract information from these maps through semantic segmentation. Recently, pre-trained foundation models have shown strong performance across domains such as autonomous driving, medical imaging, and industrial inspection. However, they struggle with historical maps. These models are trained on modern or domain-specific images, where patterns can be tied to predefined concepts through common sense or expert knowledge. Historical maps lack such consistency -- similar concepts can appear in vastly different shapes and styles. To address this, we propose On-Need Declarative (OND) knowledge-based prompting, which introduces explicit prompts to guide the model on what patterns correspond to which concepts. This allows users to specify the target concept and pattern during inference (on-need inference). We implement this by replacing the prompt encoder of the foundation model SAM with our OND prompting mechanism and fine-tune it on historical maps. The resulting model is called SMOL-MapSeg (Show Me One Label). Experiments show that SMOL-MapSeg can accurately segment classes defined by OND knowledge. It can also adapt to unseen classes through few-shot fine-tuning. Additionally, it outperforms a UNet-based baseline in average segmentation performance.
Leveraging LLMs and attention-mechanism for automatic annotation of historical maps
Apr 15, 2025Historical maps are essential resources that provide insights into the geographical landscapes of the past. They serve as valuable tools for researchers across disciplines such as history, geography, and urban studies, facilitating the reconstruction of historical environments and the analysis of spatial transformations over time. However, when constrained to analogue or scanned formats, their interpretation is limited to humans and therefore not scalable. Recent advancements in machine learning, particularly in computer vision and large language models (LLMs), have opened new avenues for automating the recognition and classification of features and objects in historical maps. In this paper, we propose a novel distillation method that leverages LLMs and attention mechanisms for the automatic annotation of historical maps. LLMs are employed to generate coarse classification labels for low-resolution historical image patches, while attention mechanisms are utilized to refine these labels to higher resolutions. Experimental results demonstrate that the refined labels achieve a high recall of more than 90%. Additionally, the intersection over union (IoU) scores--84.2% for Wood and 72.0% for Settlement--along with precision scores of 87.1% and 79.5%, respectively, indicate that most labels are well-aligned with ground-truth annotations. Notably, these results were achieved without the use of fine-grained manual labels during training, underscoring the potential of our approach for efficient and scalable historical map analysis.
SparseAlign: A Fully Sparse Framework for Cooperative Object Detection
Mar 17, 2025Cooperative perception can increase the view field and decrease the occlusion of an ego vehicle, hence improving the perception performance and safety of autonomous driving. Despite the success of previous works on cooperative object detection, they mostly operate on dense Bird's Eye View (BEV) feature maps, which are computationally demanding and can hardly be extended to long-range detection problems. More efficient fully sparse frameworks are rarely explored. In this work, we design a fully sparse framework, SparseAlign, with three key features: an enhanced sparse 3D backbone, a query-based temporal context learning module, and a robust detection head specially tailored for sparse features. Extensive experimental results on both OPV2V and DairV2X datasets show that our framework, despite its sparsity, outperforms the state of the art with less communication bandwidth requirements. In addition, experiments on the OPV2Vt and DairV2Xt datasets for time-aligned cooperative object detection also show a significant performance gain compared to the baseline works.
Semantic Segmentation for Sequential Historical Maps by Learning from Only One Map
Jan 03, 2025Historical maps are valuable resources that capture detailed geographical information from the past. However, these maps are typically available in printed formats, which are not conducive to modern computer-based analyses. Digitizing these maps into a machine-readable format enables efficient computational analysis. In this paper, we propose an automated approach to digitization using deep-learning-based semantic segmentation, which assigns a semantic label to each pixel in scanned historical maps. A key challenge in this process is the lack of ground-truth annotations required for training deep neural networks, as manual labeling is time-consuming and labor-intensive. To address this issue, we introduce a weakly-supervised age-tracing strategy for model fine-tuning. This approach exploits the similarity in appearance and land-use patterns between historical maps from neighboring time periods to guide the training process. Specifically, model predictions for one map are utilized as pseudo-labels for training on maps from adjacent time periods. Experiments conducted on our newly curated \textit{Hameln} dataset demonstrate that the proposed age-tracing strategy significantly enhances segmentation performance compared to baseline models. In the best-case scenario, the mean Intersection over Union (mIoU) achieved 77.3\%, reflecting an improvement of approximately 20\% over baseline methods. Additionally, the fine-tuned model achieved an average overall accuracy of 97\%, highlighting the effectiveness of our approach for digitizing historical maps.
Gap Completion in Point Cloud Scene occluded by Vehicles using SGC-Net
Jul 11, 2024Recent advances in mobile mapping systems have greatly enhanced the efficiency and convenience of acquiring urban 3D data. These systems utilize LiDAR sensors mounted on vehicles to capture vast cityscapes. However, a significant challenge arises due to occlusions caused by roadside parked vehicles, leading to the loss of scene information, particularly on the roads, sidewalks, curbs, and the lower sections of buildings. In this study, we present a novel approach that leverages deep neural networks to learn a model capable of filling gaps in urban scenes that are obscured by vehicle occlusion. We have developed an innovative technique where we place virtual vehicle models along road boundaries in the gap-free scene and utilize a ray-casting algorithm to create a new scene with occluded gaps. This allows us to generate diverse and realistic urban point cloud scenes with and without vehicle occlusion, surpassing the limitations of real-world training data collection and annotation. Furthermore, we introduce the Scene Gap Completion Network (SGC-Net), an end-to-end model that can generate well-defined shape boundaries and smooth surfaces within occluded gaps. The experiment results reveal that 97.66% of the filled points fall within a range of 5 centimeters relative to the high-density ground truth point cloud scene. These findings underscore the efficacy of our proposed model in gap completion and reconstructing urban scenes affected by vehicle occlusions.
StreamLTS: Query-based Temporal-Spatial LiDAR Fusion for Cooperative Object Detection
Jul 04, 2024



Cooperative perception via communication among intelligent traffic agents has great potential to improve the safety of autonomous driving. However, limited communication bandwidth, localization errors and asynchronized capturing time of sensor data, all introduce difficulties to the data fusion of different agents. To some extend, previous works have attempted to reduce the shared data size, mitigate the spatial feature misalignment caused by localization errors and communication delay. However, none of them have considered the asynchronized sensor ticking times, which can lead to dynamic object misplacement of more than one meter during data fusion. In this work, we propose Time-Aligned COoperative Object Detection (TA-COOD), for which we adapt widely used dataset OPV2V and DairV2X with considering asynchronous LiDAR sensor ticking times and build an efficient fully sparse framework with modeling the temporal information of individual objects with query-based techniques. The experiment results confirmed the superior efficiency of our fully sparse framework compared to the state-of-the-art dense models. More importantly, they show that the point-wise observation timestamps of the dynamic objects are crucial for accurate modeling the object temporal context and the predictability of their time-related locations.
CoSense3D: an Agent-based Efficient Learning Framework for Collective Perception
Apr 29, 2024Collective Perception has attracted significant attention in recent years due to its advantage for mitigating occlusion and expanding the field-of-view, thereby enhancing reliability, efficiency, and, most crucially, decision-making safety. However, developing collective perception models is highly resource demanding due to extensive requirements of processing input data for many agents, usually dozens of images and point clouds for a single frame. This not only slows down the model development process for collective perception but also impedes the utilization of larger models. In this paper, we propose an agent-based training framework that handles the deep learning modules and agent data separately to have a cleaner data flow structure. This framework not only provides an API for flexibly prototyping the data processing pipeline and defining the gradient calculation for each agent, but also provides the user interface for interactive training, testing and data visualization. Training experiment results of four collective object detection models on the prominent collective perception benchmark OPV2V show that the agent-based training can significantly reduce the GPU memory consumption and training time while retaining inference performance. The framework and model implementations are available at \url{https://github.com/YuanYunshuang/CoSense3D}
3D Uncertain Distance Field Mapping using GMM and GP
Mar 12, 2024



In this study, we address the challenge of constructing continuous three-dimensional (3D) models that accurately represent uncertain surfaces, derived from noisy and incomplete LiDAR scanning data. Building upon our prior work, which utilized the Gaussian Process (GP) and Gaussian Mixture Model (GMM) for structured building models, we introduce a more generalized approach tailored for complex surfaces in urban scenes, where four-dimensional (4D) GMM Regression and GP with derivative observations are applied. A Hierarchical GMM (HGMM) is employed to optimize the number of GMM components and speed up the GMM training. With the prior map obtained from HGMM, GP inference is followed for the refinement of the final map. Our approach models the implicit surface of the geo-object and enables the inference of the regions that are not completely covered by measurements. The integration of GMM and GP yields well-calibrated uncertainty estimates alongside the surface model, enhancing both accuracy and reliability. The proposed method is evaluated on the real data collected by a mobile mapping system. Compared to the performance in mapping accuracy and uncertainty quantification of other methods such as Gaussian Process Implicit Surface map (GPIS) and log-Gaussian Process Implicit Surface map (Log-GPIS), the proposed method achieves lower RMSEs, higher log-likelihood values and fewer computational costs for the evaluated datasets.
Controllable Diverse Sampling for Diffusion Based Motion Behavior Forecasting
Feb 06, 2024
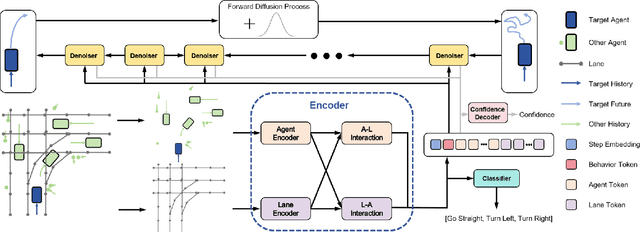

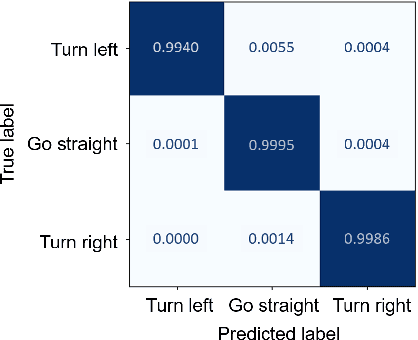
In autonomous driving tasks, trajectory prediction in complex traffic environments requires adherence to real-world context conditions and behavior multimodalities. Existing methods predominantly rely on prior assumptions or generative models trained on curated data to learn road agents' stochastic behavior bounded by scene constraints. However, they often face mode averaging issues due to data imbalance and simplistic priors, and could even suffer from mode collapse due to unstable training and single ground truth supervision. These issues lead the existing methods to a loss of predictive diversity and adherence to the scene constraints. To address these challenges, we introduce a novel trajectory generator named Controllable Diffusion Trajectory (CDT), which integrates map information and social interactions into a Transformer-based conditional denoising diffusion model to guide the prediction of future trajectories. To ensure multimodality, we incorporate behavioral tokens to direct the trajectory's modes, such as going straight, turning right or left. Moreover, we incorporate the predicted endpoints as an alternative behavioral token into the CDT model to facilitate the prediction of accurate trajectories. Extensive experiments on the Argoverse 2 benchmark demonstrate that CDT excels in generating diverse and scene-compliant trajectories in complex urban settings.
LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints
Feb 27, 2023Trajectory prediction for autonomous driving must continuously reason the motion stochasticity of road agents and comply with scene constraints. Existing methods typically rely on one-stage trajectory prediction models, which condition future trajectories on observed trajectories combined with fused scene information. However, they often struggle with complex scene constraints, such as those encountered at intersections. To this end, we present a novel method, called LAformer. It uses a temporally dense lane-aware estimation module to select only the top highly potential lane segments in an HD map, which effectively and continuously aligns motion dynamics with scene information, reducing the representation requirements for the subsequent attention-based decoder by filtering out irrelevant lane segments. Additionally, unlike one-stage prediction models, LAformer utilizes predictions from the first stage as anchor trajectories and adds a second-stage motion refinement module to further explore temporal consistency across the complete time horizon. Extensive experiments on Argoverse 1 and nuScenes demonstrate that LAformer achieves excellent performance for multimodal trajectory prediction.