 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMOL-MapSeg: Show Me One Label
Aug 07, 2025Historical maps are valuable for studying changes to the Earth's surface. With the rise of deep learning, models like UNet have been used to extract information from these maps through semantic segmentation. Recently, pre-trained foundation models have shown strong performance across domains such as autonomous driving, medical imaging, and industrial inspection. However, they struggle with historical maps. These models are trained on modern or domain-specific images, where patterns can be tied to predefined concepts through common sense or expert knowledge. Historical maps lack such consistency -- similar concepts can appear in vastly different shapes and styles. To address this, we propose On-Need Declarative (OND) knowledge-based prompting, which introduces explicit prompts to guide the model on what patterns correspond to which concepts. This allows users to specify the target concept and pattern during inference (on-need inference). We implement this by replacing the prompt encoder of the foundation model SAM with our OND prompting mechanism and fine-tune it on historical maps. The resulting model is called SMOL-MapSeg (Show Me One Label). Experiments show that SMOL-MapSeg can accurately segment classes defined by OND knowledge. It can also adapt to unseen classes through few-shot fine-tuning. Additionally, it outperforms a UNet-based baseline in average segmentation performance.
Leveraging LLMs and attention-mechanism for automatic annotation of historical maps
Apr 15, 2025Historical maps are essential resources that provide insights into the geographical landscapes of the past. They serve as valuable tools for researchers across disciplines such as history, geography, and urban studies, facilitating the reconstruction of historical environments and the analysis of spatial transformations over time. However, when constrained to analogue or scanned formats, their interpretation is limited to humans and therefore not scalable. Recent advancements in machine learning, particularly in computer vision and large language models (LLMs), have opened new avenues for automating the recognition and classification of features and objects in historical maps. In this paper, we propose a novel distillation method that leverages LLMs and attention mechanisms for the automatic annotation of historical maps. LLMs are employed to generate coarse classification labels for low-resolution historical image patches, while attention mechanisms are utilized to refine these labels to higher resolutions. Experimental results demonstrate that the refined labels achieve a high recall of more than 90%. Additionally, the intersection over union (IoU) scores--84.2% for Wood and 72.0% for Settlement--along with precision scores of 87.1% and 79.5%, respectively, indicate that most labels are well-aligned with ground-truth annotations. Notably, these results were achieved without the use of fine-grained manual labels during training, underscoring the potential of our approach for efficient and scalable historical map analysis.
SparseAlign: A Fully Sparse Framework for Cooperative Object Detection
Mar 17, 2025Cooperative perception can increase the view field and decrease the occlusion of an ego vehicle, hence improving the perception performance and safety of autonomous driving. Despite the success of previous works on cooperative object detection, they mostly operate on dense Bird's Eye View (BEV) feature maps, which are computationally demanding and can hardly be extended to long-range detection problems. More efficient fully sparse frameworks are rarely explored. In this work, we design a fully sparse framework, SparseAlign, with three key features: an enhanced sparse 3D backbone, a query-based temporal context learning module, and a robust detection head specially tailored for sparse features. Extensive experimental results on both OPV2V and DairV2X datasets show that our framework, despite its sparsity, outperforms the state of the art with less communication bandwidth requirements. In addition, experiments on the OPV2Vt and DairV2Xt datasets for time-aligned cooperative object detection also show a significant performance gain compared to the baseline works.
Semantic Segmentation for Sequential Historical Maps by Learning from Only One Map
Jan 03, 2025Historical maps are valuable resources that capture detailed geographical information from the past. However, these maps are typically available in printed formats, which are not conducive to modern computer-based analyses. Digitizing these maps into a machine-readable format enables efficient computational analysis. In this paper, we propose an automated approach to digitization using deep-learning-based semantic segmentation, which assigns a semantic label to each pixel in scanned historical maps. A key challenge in this process is the lack of ground-truth annotations required for training deep neural networks, as manual labeling is time-consuming and labor-intensive. To address this issue, we introduce a weakly-supervised age-tracing strategy for model fine-tuning. This approach exploits the similarity in appearance and land-use patterns between historical maps from neighboring time periods to guide the training process. Specifically, model predictions for one map are utilized as pseudo-labels for training on maps from adjacent time periods. Experiments conducted on our newly curated \textit{Hameln} dataset demonstrate that the proposed age-tracing strategy significantly enhances segmentation performance compared to baseline models. In the best-case scenario, the mean Intersection over Union (mIoU) achieved 77.3\%, reflecting an improvement of approximately 20\% over baseline methods. Additionally, the fine-tuned model achieved an average overall accuracy of 97\%, highlighting the effectiveness of our approach for digitizing historical maps.
StreamLTS: Query-based Temporal-Spatial LiDAR Fusion for Cooperative Object Detection
Jul 04, 2024



Cooperative perception via communication among intelligent traffic agents has great potential to improve the safety of autonomous driving. However, limited communication bandwidth, localization errors and asynchronized capturing time of sensor data, all introduce difficulties to the data fusion of different agents. To some extend, previous works have attempted to reduce the shared data size, mitigate the spatial feature misalignment caused by localization errors and communication delay. However, none of them have considered the asynchronized sensor ticking times, which can lead to dynamic object misplacement of more than one meter during data fusion. In this work, we propose Time-Aligned COoperative Object Detection (TA-COOD), for which we adapt widely used dataset OPV2V and DairV2X with considering asynchronous LiDAR sensor ticking times and build an efficient fully sparse framework with modeling the temporal information of individual objects with query-based techniques. The experiment results confirmed the superior efficiency of our fully sparse framework compared to the state-of-the-art dense models. More importantly, they show that the point-wise observation timestamps of the dynamic objects are crucial for accurate modeling the object temporal context and the predictability of their time-related locations.
CoSense3D: an Agent-based Efficient Learning Framework for Collective Perception
Apr 29, 2024Collective Perception has attracted significant attention in recent years due to its advantage for mitigating occlusion and expanding the field-of-view, thereby enhancing reliability, efficiency, and, most crucially, decision-making safety. However, developing collective perception models is highly resource demanding due to extensive requirements of processing input data for many agents, usually dozens of images and point clouds for a single frame. This not only slows down the model development process for collective perception but also impedes the utilization of larger models. In this paper, we propose an agent-based training framework that handles the deep learning modules and agent data separately to have a cleaner data flow structure. This framework not only provides an API for flexibly prototyping the data processing pipeline and defining the gradient calculation for each agent, but also provides the user interface for interactive training, testing and data visualization. Training experiment results of four collective object detection models on the prominent collective perception benchmark OPV2V show that the agent-based training can significantly reduce the GPU memory consumption and training time while retaining inference performance. The framework and model implementations are available at \url{https://github.com/YuanYunshuang/CoSense3D}
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.
Generating Evidential BEV Maps in Continuous Driving Space
Feb 06, 2023
Safety is critical for autonomous driving, and one aspect of improving safety is to accurately capture the uncertainties of the perception system, especially knowing the unknown. Different from only providing deterministic or probabilistic results, e.g., probabilistic object detection, that only provide partial information for the perception scenario, we propose a complete probabilistic model named GevBEV. It interprets the 2D driving space as a probabilistic Bird's Eye View (BEV) map with point-based spatial Gaussian distributions, from which one can draw evidence as the parameters for the categorical Dirichlet distribution of any new sample point in the continuous driving space. The experimental results show that GevBEV not only provides more reliable uncertainty quantification but also outperforms the previous works on the benchmark OPV2V of BEV map interpretation for cooperative perception. A critical factor in cooperative perception is the data transmission size through the communication channels. GevBEV helps reduce communication overhead by selecting only the most important information to share from the learned uncertainty, reducing the average information communicated by 80% with a slight performance drop.
Leveraging Dynamic Objects for Relative Localization Correction in a Connected Autonomous Vehicle Network
May 30, 2022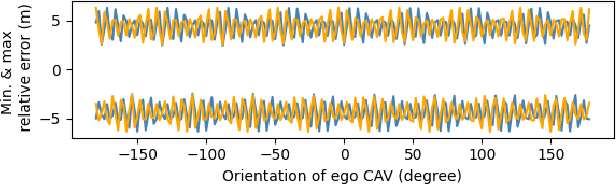
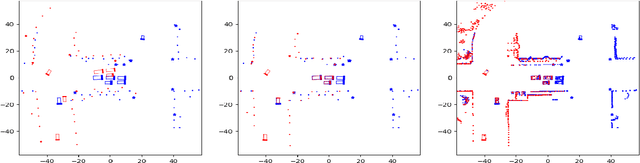
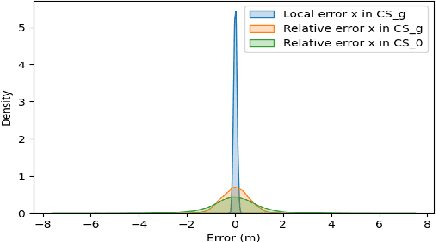
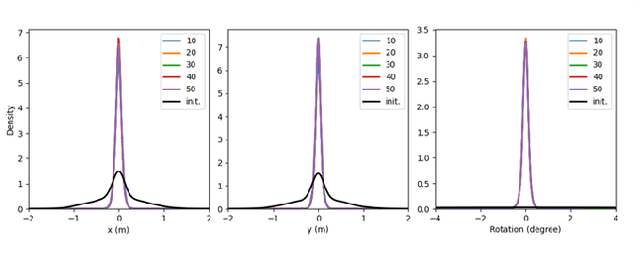
High-accurate localization is crucial for the safety and reliability of autonomous driving, especially for the information fusion of collective perception that aims to further improve road safety by sharing information in a communication network of ConnectedAutonomous Vehicles (CAV). In this scenario, small localization errors can impose additional difficulty on fusing the information from different CAVs. In this paper, we propose a RANSAC-based (RANdom SAmple Consensus) method to correct the relative localization errors between two CAVs in order to ease the information fusion among the CAVs. Different from previous LiDAR-based localization algorithms that only take the static environmental information into consideration, this method also leverages the dynamic objects for localization thanks to the real-time data sharing between CAVs. Specifically, in addition to the static objects like poles, fences, and facades, the object centers of the detected dynamic vehicles are also used as keypoints for the matching of two point sets. The experiments on the synthetic dataset COMAP show that the proposed method can greatly decrease the relative localization error between two CAVs to less than 20cmas far as there are enough vehicles and poles are correctly detected by bothCAVs. Besides, our proposed method is also highly efficient in runtime and can be used in real-time scenarios of autonomous driving.
Keypoints-Based Deep Feature Fusion for Cooperative Vehicle Detection of Autonomous Driving
Sep 23, 2021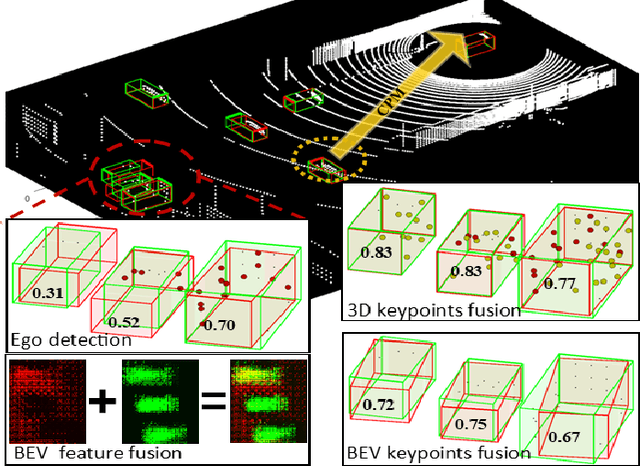
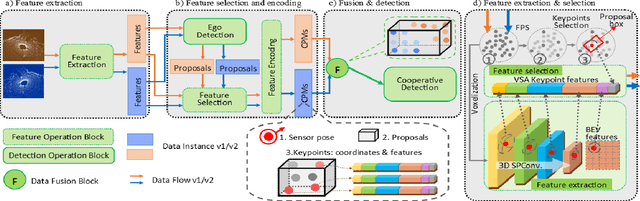
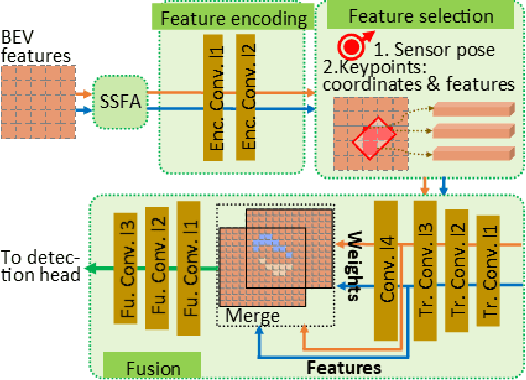
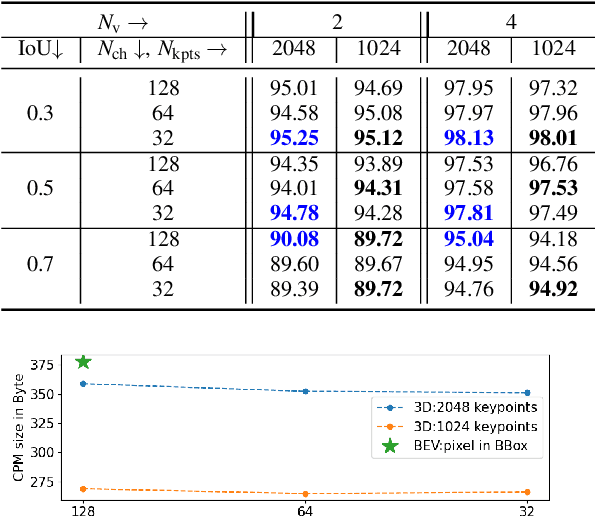
Sharing collective perception messages (CPM) between vehicles is investigated to decrease occlusions, so as to improve perception accuracy and safety of autonomous driving. However, highly accurate data sharing and low communication overhead is a big challenge for collective perception, especially when real-time communication is required among connected and automated vehicles. In this paper, we propose an efficient and effective keypoints-based deep feature fusion framework, called FPV-RCNN, for collective perception, which is built on top of the 3D object detector PV-RCNN. We introduce a bounding box proposal matching module and a keypoints selection strategy to compress the CPM size and solve the multi-vehicle data fusion problem. Compared to a bird's-eye view (BEV) keypoints feature fusion, FPV-RCNN achieves improved detection accuracy by about 14% at a high evaluation criterion (IoU 0.7) on a synthetic dataset COMAP dedicated to collective perception. Also, its performance is comparable to two raw data fusion baselines that have no data loss in sharing. Moreover, our method also significantly decreases the CPM size to less than 0.3KB, which is about 50 times smaller than the BEV feature map sharing used in previous works. Even with a further decreased number of CPM feature channels, i.e., from 128 to 32, the detection performance only drops about 1%. The code of our method is available at https://github.com/YuanYunshuang/FPV_RCNN.