 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInSPE: Rapid Evaluation of Heterogeneous Multi-Modal Infrastructure Sensor Placement
Apr 11, 2025Infrastructure sensing is vital for traffic monitoring at safety hotspots (e.g., intersections) and serves as the backbone of cooperative perception in autonomous driving. While vehicle sensing has been extensively studied, infrastructure sensing has received little attention, especially given the unique challenges of diverse intersection geometries, complex occlusions, varying traffic conditions, and ambient environments like lighting and weather. To address these issues and ensure cost-effective sensor placement, we propose Heterogeneous Multi-Modal Infrastructure Sensor Placement Evaluation (InSPE), a perception surrogate metric set that rapidly assesses perception effectiveness across diverse infrastructure and environmental scenarios with combinations of multi-modal sensors. InSPE systematically evaluates perception capabilities by integrating three carefully designed metrics, i.e., sensor coverage, perception occlusion, and information gain. To support large-scale evaluation, we develop a data generation tool within the CARLA simulator and also introduce Infra-Set, a dataset covering diverse intersection types and environmental conditions. Benchmarking experiments with state-of-the-art perception algorithms demonstrate that InSPE enables efficient and scalable sensor placement analysis, providing a robust solution for optimizing intelligent intersection infrastructure.
V2X-ReaLO: An Open Online Framework and Dataset for Cooperative Perception in Reality
Mar 13, 2025Cooperative perception enabled by Vehicle-to-Everything (V2X) communication holds significant promise for enhancing the perception capabilities of autonomous vehicles, allowing them to overcome occlusions and extend their field of view. However, existing research predominantly relies on simulated environments or static datasets, leaving the feasibility and effectiveness of V2X cooperative perception especially for intermediate fusion in real-world scenarios largely unexplored. In this work, we introduce V2X-ReaLO, an open online cooperative perception framework deployed on real vehicles and smart infrastructure that integrates early, late, and intermediate fusion methods within a unified pipeline and provides the first practical demonstration of online intermediate fusion's feasibility and performance under genuine real-world conditions. Additionally, we present an open benchmark dataset specifically designed to assess the performance of online cooperative perception systems. This new dataset extends V2X-Real dataset to dynamic, synchronized ROS bags and provides 25,028 test frames with 6,850 annotated key frames in challenging urban scenarios. By enabling real-time assessments of perception accuracy and communication lantency under dynamic conditions, V2X-ReaLO sets a new benchmark for advancing and optimizing cooperative perception systems in real-world applications. The codes and datasets will be released to further advance the field.
AgentAlign: Misalignment-Adapted Multi-Agent Perception for Resilient Inter-Agent Sensor Correlations
Dec 09, 2024Cooperative perception has attracted wide attention given its capability to leverage shared information across connected automated vehicles (CAVs) and smart infrastructures to address sensing occlusion and range limitation issues. However, existing research overlooks the fragile multi-sensor correlations in multi-agent settings, as the heterogeneous agent sensor measurements are highly susceptible to environmental factors, leading to weakened inter-agent sensor interactions. The varying operational conditions and other real-world factors inevitably introduce multifactorial noise and consequentially lead to multi-sensor misalignment, making the deployment of multi-agent multi-modality perception particularly challenging in the real world. In this paper, we propose AgentAlign, a real-world heterogeneous agent cross-modality feature alignment framework, to effectively address these multi-modality misalignment issues. Our method introduces a cross-modality feature alignment space (CFAS) and heterogeneous agent feature alignment (HAFA) mechanism to harmonize multi-modality features across various agents dynamically. Additionally, we present a novel V2XSet-noise dataset that simulates realistic sensor imperfections under diverse environmental conditions, facilitating a systematic evaluation of our approach's robustness. Extensive experiments on the V2X-Real and V2XSet-Noise benchmarks demonstrate that our framework achieves state-of-the-art performance, underscoring its potential for real-world applications in cooperative autonomous driving. The controllable V2XSet-Noise dataset and generation pipeline will be released in the future.
V2XPnP: Vehicle-to-Everything Spatio-Temporal Fusion for Multi-Agent Perception and Prediction
Dec 02, 2024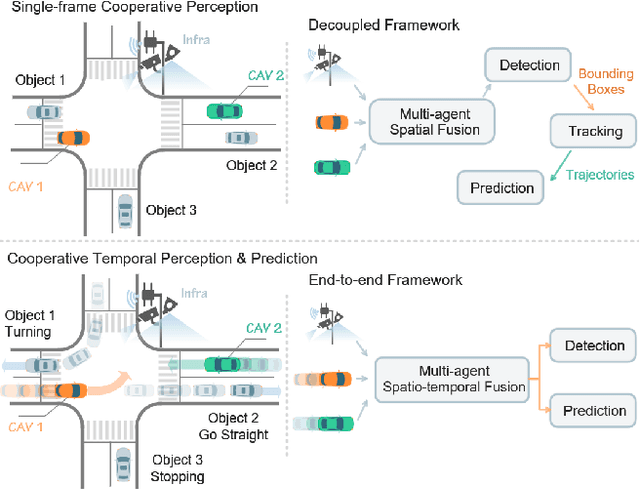
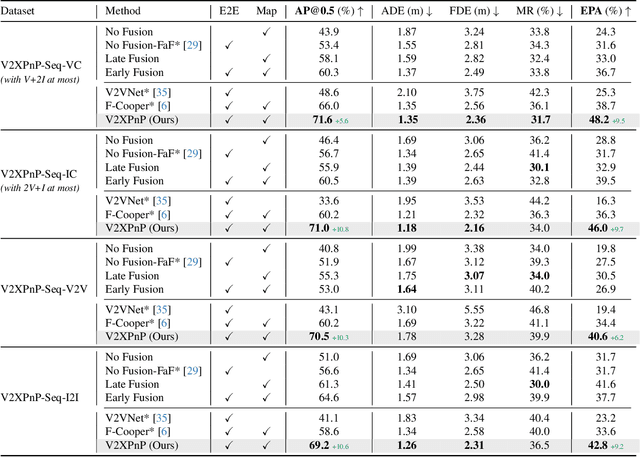
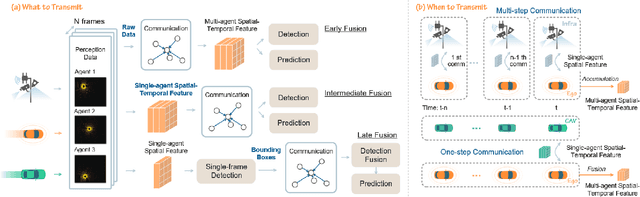
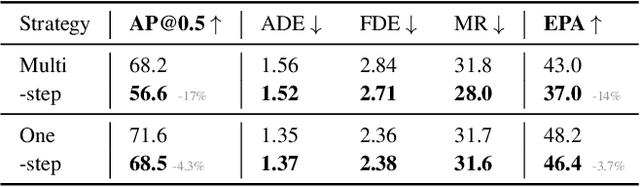
Vehicle-to-everything (V2X) technologies offer a promising paradigm to mitigate the limitations of constrained observability in single-vehicle systems. Prior work primarily focuses on single-frame cooperative perception, which fuses agents' information across different spatial locations but ignores temporal cues and temporal tasks (e.g., temporal perception and prediction). In this paper, we focus on temporal perception and prediction tasks in V2X scenarios and design one-step and multi-step communication strategies (when to transmit) as well as examine their integration with three fusion strategies - early, late, and intermediate (what to transmit), providing comprehensive benchmarks with various fusion models (how to fuse). Furthermore, we propose V2XPnP, a novel intermediate fusion framework within one-step communication for end-to-end perception and prediction. Our framework employs a unified Transformer-based architecture to effectively model complex spatiotemporal relationships across temporal per-frame, spatial per-agent, and high-definition map. Moreover, we introduce the V2XPnP Sequential Dataset that supports all V2X cooperation modes and addresses the limitations of existing real-world datasets, which are restricted to single-frame or single-mode cooperation. Extensive experiments demonstrate our framework outperforms state-of-the-art methods in both perception and prediction tasks.
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.
BTO-RRT: A rapid, optimal, smooth and point cloud-based path planning algorithm
Nov 13, 2022


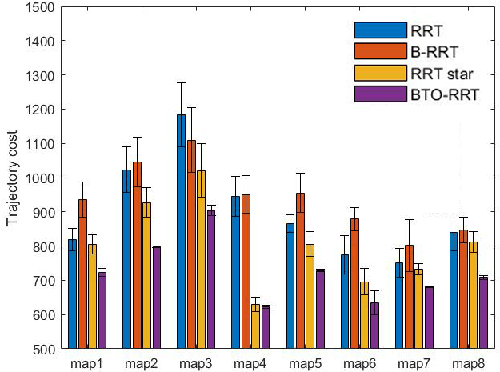
This paper explores a rapid, optimal smooth path-planning algorithm for robots (e.g., autonomous vehicles) in point cloud environments. Derivative maps such as dense point clouds, mesh maps, Octomaps, etc. are frequently used for path planning purposes. A bi-directional target-oriented point planning algorithm, directly using point clouds to compute the optimized and dynamically feasible trajectories, is presented in this paper. This approach searches for obstacle-free, low computational cost, smooth, and dynamically feasible paths by analyzing a point cloud of the target environment, using a modified bi-directional and RRT-connect-based path planning algorithm, with a k-d tree-based obstacle avoidance strategy and three-step optimization. This presented approach bypasses the common 3D map discretization, directly leveraging point cloud data and it can be separated into two parts: modified RRT-based algorithm core and the three-step optimization. Simulations on 8 2D maps with different configurations and characteristics are presented to show the efficiency and 2D performance of the proposed algorithm. Benchmark comparison and evaluation with other RRT-based algorithms like RRT, B-RRT, and RRT star are also shown in the paper. Finally, the proposed algorithm successfully achieved different levels of mission goals on three 3D point cloud maps with different densities. The whole simulation proves that not only can our algorithm achieves a better performance on 2D maps compared with other algorithms, but also it can handle different tasks(ground vehicles and UAV applications) on different 3D point cloud maps, which shows the high performance and robustness of the proposed algorithm. The algorithm is open-sourced at \url{https://github.com/zhz03/BTO-RRT}
V2XP-ASG: Generating Adversarial Scenes for Vehicle-to-Everything Perception
Sep 27, 2022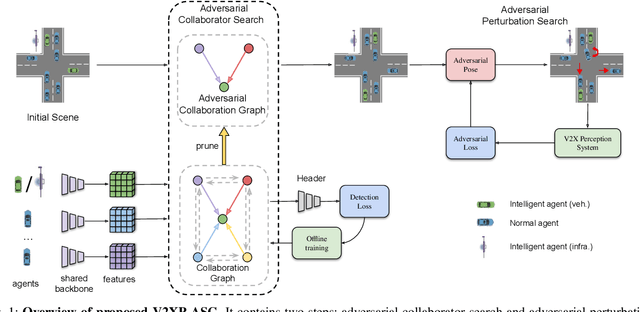
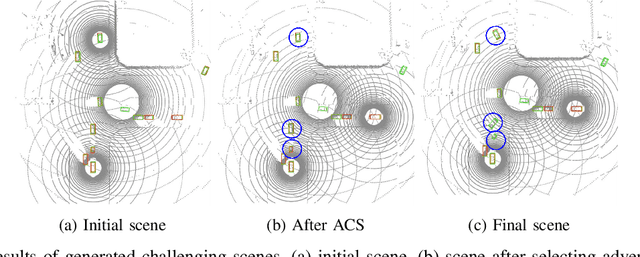
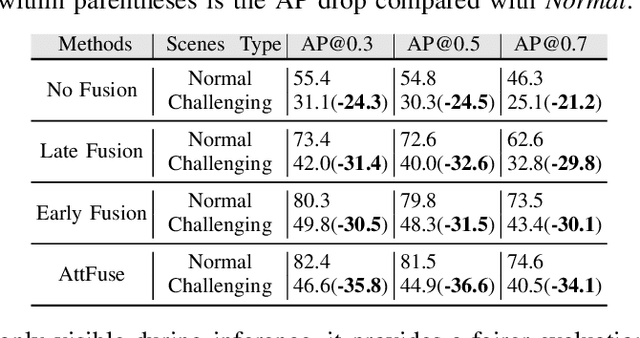

Recent advancements in Vehicle-to-Everything communication technology have enabled autonomous vehicles to share sensory information to obtain better perception performance. With the rapid growth of autonomous vehicles and intelligent infrastructure, the V2X perception systems will soon be deployed at scale, which raises a safety-critical question: how can we evaluate and improve its performance under challenging traffic scenarios before the real-world deployment? Collecting diverse large-scale real-world test scenes seems to be the most straightforward solution, but it is expensive and time-consuming, and the collections can only cover limited scenarios. To this end, we propose the first open adversarial scene generator V2XP-ASG that can produce realistic, challenging scenes for modern LiDAR-based multi-agent perception system. V2XP-ASG learns to construct an adversarial collaboration graph and simultaneously perturb multiple agents' poses in an adversarial and plausible manner. The experiments demonstrate that V2XP-ASG can effectively identify challenging scenes for a large range of V2X perception systems. Meanwhile, by training on the limited number of generated challenging scenes, the accuracy of V2X perception systems can be further improved by 12.3% on challenging and 4% on normal scenes.
Joint State and Input Estimation of Agent Based on Recursive Kalman Filter Given Prior Knowledge
Nov 15, 2021
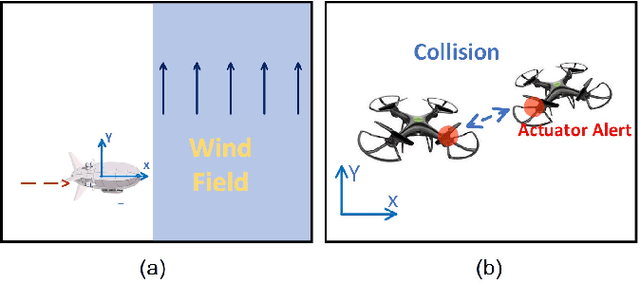
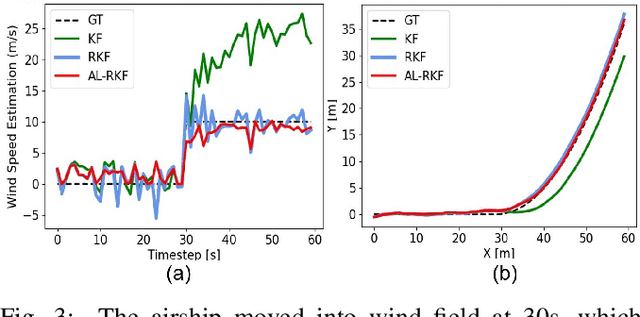
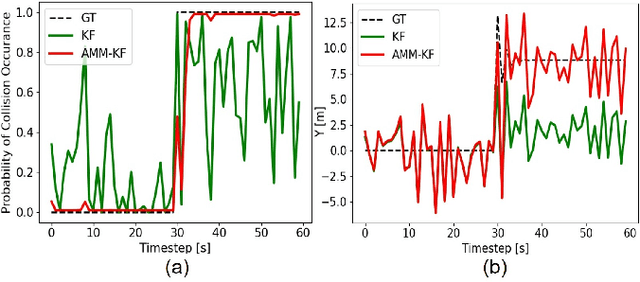
Modern autonomous systems are purposed for many challenging scenarios, where agents will face unexpected events and complicated tasks. The presence of disturbance noise with control command and unknown inputs can negatively impact robot performance. Previous research of joint input and state estimation separately study the continuous and discrete cases without any prior information. This paper combines the continuous space and discrete space estimation into a unified theory based on the Expectation-Maximum (EM) algorithm. By introducing prior knowledge of events as the constraint, inequality optimization problems are formulated to determine a gain matrix or dynamic weights to realize an optimal input estimation with lower variance and more accurate decision-making. Finally, statistical results from experiments show that our algorithm owns 81\% improvement of the variance than KF and 47\% improvement than RKF in continuous space; a remarkable improvement of right decision-making probability of our input estimator in discrete space, identification ability is also analyzed by experiments.