 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2XPnP: Vehicle-to-Everything Spatio-Temporal Fusion for Multi-Agent Perception and Prediction
Paper and Code
Dec 02, 2024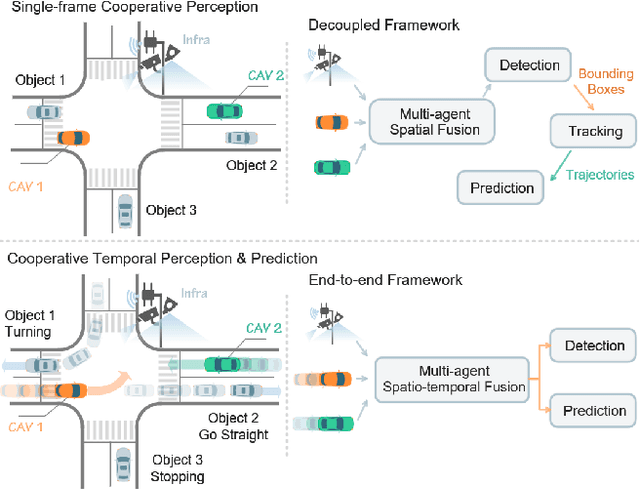
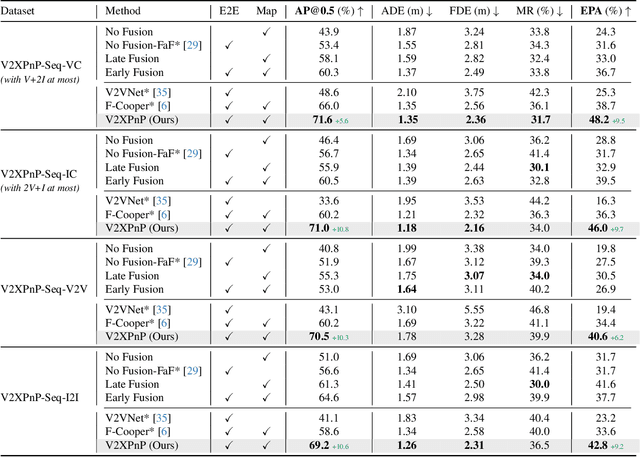
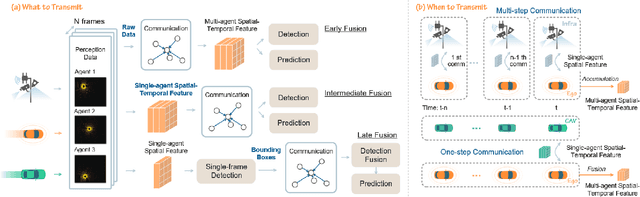
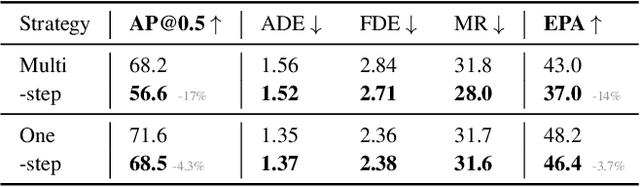
Vehicle-to-everything (V2X) technologies offer a promising paradigm to mitigate the limitations of constrained observability in single-vehicle systems. Prior work primarily focuses on single-frame cooperative perception, which fuses agents' information across different spatial locations but ignores temporal cues and temporal tasks (e.g., temporal perception and prediction). In this paper, we focus on temporal perception and prediction tasks in V2X scenarios and design one-step and multi-step communication strategies (when to transmit) as well as examine their integration with three fusion strategies - early, late, and intermediate (what to transmit), providing comprehensive benchmarks with various fusion models (how to fuse). Furthermore, we propose V2XPnP, a novel intermediate fusion framework within one-step communication for end-to-end perception and prediction. Our framework employs a unified Transformer-based architecture to effectively model complex spatiotemporal relationships across temporal per-frame, spatial per-agent, and high-definition map. Moreover, we introduce the V2XPnP Sequential Dataset that supports all V2X cooperation modes and addresses the limitations of existing real-world datasets, which are restricted to single-frame or single-mode cooperation. Extensive experiments demonstrate our framework outperforms state-of-the-art methods in both perception and prediction tasks.