 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception
Sep 03, 2025Cooperative perception through Vehicle-to-Everything (V2X) communication offers significant potential for enhancing vehicle perception by mitigating occlusions and expanding the field of view. However, past research has predominantly focused on improving accuracy metrics without addressing the crucial system-level considerations of efficiency, latency, and real-world deployability. Noticeably, most existing systems rely on full-precision models, which incur high computational and transmission costs, making them impractical for real-time operation in resource-constrained environments. In this paper, we introduce \textbf{QuantV2X}, the first fully quantized multi-agent system designed specifically for efficient and scalable deployment of multi-modal, multi-agent V2X cooperative perception. QuantV2X introduces a unified end-to-end quantization strategy across both neural network models and transmitted message representations that simultaneously reduces computational load and transmission bandwidth. Remarkably, despite operating under low-bit constraints, QuantV2X achieves accuracy comparable to full-precision systems. More importantly, when evaluated under deployment-oriented metrics, QuantV2X reduces system-level latency by 3.2$\times$ and achieves a +9.5 improvement in mAP30 over full-precision baselines. Furthermore, QuantV2X scales more effectively, enabling larger and more capable models to fit within strict memory budgets. These results highlight the viability of a fully quantized multi-agent intermediate fusion system for real-world deployment. The system will be publicly released to promote research in this field: https://github.com/ucla-mobility/QuantV2X.
RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
Jul 27, 2025Recent advancements in Large Language Models (LLMs) have shown outstanding potential for role-playing applications. Evaluating these capabilities is becoming crucial yet remains challenging. Existing benchmarks mostly adopt a \textbf{character-centric} approach, simplify user-character interactions to isolated Q&A tasks, and fail to reflect real-world applications. To address this limitation, we introduce RMTBench, a comprehensive \textbf{user-centric} bilingual role-playing benchmark featuring 80 diverse characters and over 8,000 dialogue rounds. RMTBench includes custom characters with detailed backgrounds and abstract characters defined by simple traits, enabling evaluation across various user scenarios. Our benchmark constructs dialogues based on explicit user motivations rather than character descriptions, ensuring alignment with practical user applications. Furthermore, we construct an authentic multi-turn dialogue simulation mechanism. With carefully selected evaluation dimensions and LLM-based scoring, this mechanism captures the complex intention of conversations between the user and the character. By shifting focus from character background to user intention fulfillment, RMTBench bridges the gap between academic evaluation and practical deployment requirements, offering a more effective framework for assessing role-playing capabilities in LLMs. All code and datasets will be released soon.
V2X-ReaLO: An Open Online Framework and Dataset for Cooperative Perception in Reality
Mar 13, 2025Cooperative perception enabled by Vehicle-to-Everything (V2X) communication holds significant promise for enhancing the perception capabilities of autonomous vehicles, allowing them to overcome occlusions and extend their field of view. However, existing research predominantly relies on simulated environments or static datasets, leaving the feasibility and effectiveness of V2X cooperative perception especially for intermediate fusion in real-world scenarios largely unexplored. In this work, we introduce V2X-ReaLO, an open online cooperative perception framework deployed on real vehicles and smart infrastructure that integrates early, late, and intermediate fusion methods within a unified pipeline and provides the first practical demonstration of online intermediate fusion's feasibility and performance under genuine real-world conditions. Additionally, we present an open benchmark dataset specifically designed to assess the performance of online cooperative perception systems. This new dataset extends V2X-Real dataset to dynamic, synchronized ROS bags and provides 25,028 test frames with 6,850 annotated key frames in challenging urban scenarios. By enabling real-time assessments of perception accuracy and communication lantency under dynamic conditions, V2X-ReaLO sets a new benchmark for advancing and optimizing cooperative perception systems in real-world applications. The codes and datasets will be released to further advance the field.
V2XPnP: Vehicle-to-Everything Spatio-Temporal Fusion for Multi-Agent Perception and Prediction
Dec 02, 2024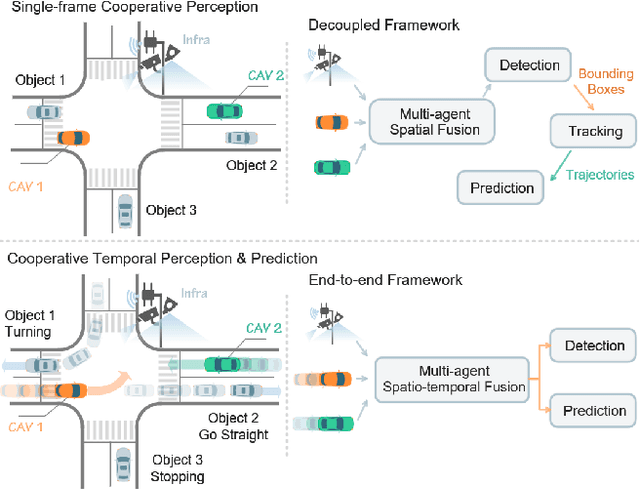
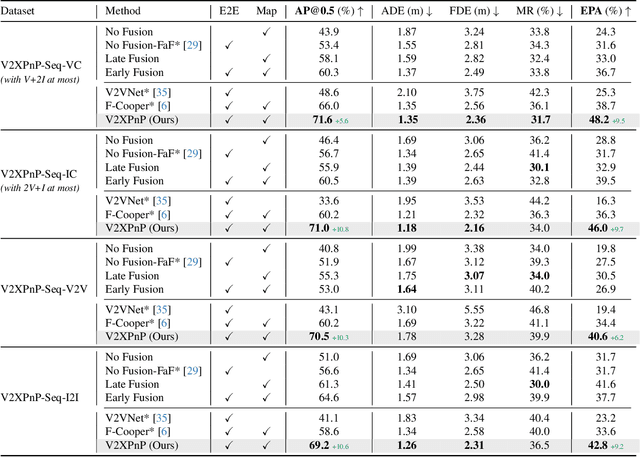
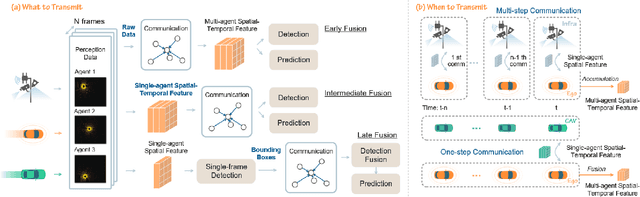
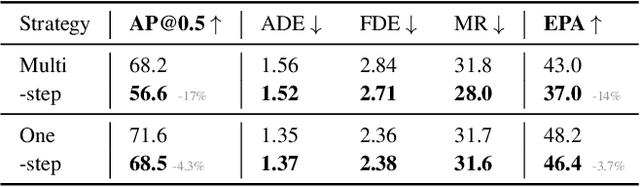
Vehicle-to-everything (V2X) technologies offer a promising paradigm to mitigate the limitations of constrained observability in single-vehicle systems. Prior work primarily focuses on single-frame cooperative perception, which fuses agents' information across different spatial locations but ignores temporal cues and temporal tasks (e.g., temporal perception and prediction). In this paper, we focus on temporal perception and prediction tasks in V2X scenarios and design one-step and multi-step communication strategies (when to transmit) as well as examine their integration with three fusion strategies - early, late, and intermediate (what to transmit), providing comprehensive benchmarks with various fusion models (how to fuse). Furthermore, we propose V2XPnP, a novel intermediate fusion framework within one-step communication for end-to-end perception and prediction. Our framework employs a unified Transformer-based architecture to effectively model complex spatiotemporal relationships across temporal per-frame, spatial per-agent, and high-definition map. Moreover, we introduce the V2XPnP Sequential Dataset that supports all V2X cooperation modes and addresses the limitations of existing real-world datasets, which are restricted to single-frame or single-mode cooperation. Extensive experiments demonstrate our framework outperforms state-of-the-art methods in both perception and prediction tasks.
Aligning Large Language Models via Self-Steering Optimization
Oct 22, 2024Automated alignment develops alignment systems with minimal human intervention. The key to automated alignment lies in providing learnable and accurate preference signals for preference learning without human annotation. In this paper, we introduce Self-Steering Optimization ($SSO$), an algorithm that autonomously generates high-quality preference signals based on predefined principles during iterative training, eliminating the need for manual annotation. $SSO$ maintains the accuracy of signals by ensuring a consistent gap between chosen and rejected responses while keeping them both on-policy to suit the current policy model's learning capacity. $SSO$ can benefit the online and offline training of the policy model, as well as enhance the training of reward models. We validate the effectiveness of $SSO$ with two foundation models, Qwen2 and Llama3.1, indicating that it provides accurate, on-policy preference signals throughout iterative training. Without any manual annotation or external models, $SSO$ leads to significant performance improvements across six subjective or objective benchmarks. Besides, the preference data generated by $SSO$ significantly enhanced the performance of the reward model on Rewardbench. Our work presents a scalable approach to preference optimization, paving the way for more efficient and effective automated alignment.
CooPre: Cooperative Pretraining for V2X Cooperative Perception
Aug 20, 2024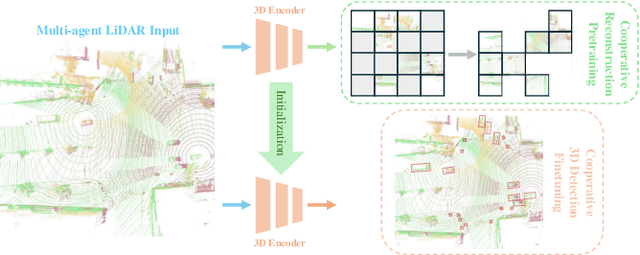
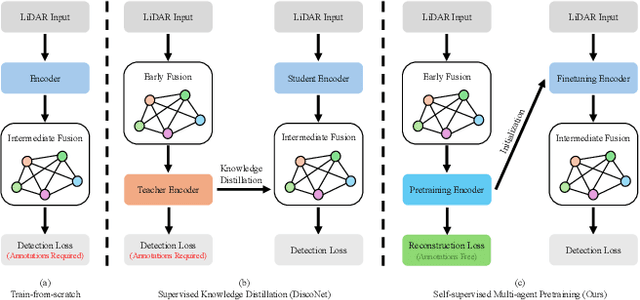

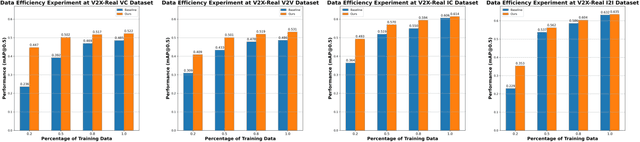
Existing Vehicle-to-Everything (V2X) cooperative perception methods rely on accurate multi-agent 3D annotations. Nevertheless, it is time-consuming and expensive to collect and annotate real-world data, especially for V2X systems. In this paper, we present a self-supervised learning method for V2X cooperative perception, which utilizes the vast amount of unlabeled 3D V2X data to enhance the perception performance. Beyond simply extending the previous pre-training methods for point-cloud representation learning, we introduce a novel self-supervised Cooperative Pretraining framework (termed as CooPre) customized for a collaborative scenario. We point out that cooperative point-cloud sensing compensates for information loss among agents. This motivates us to design a novel proxy task for the 3D encoder to reconstruct LiDAR point clouds across different agents. Besides, we develop a V2X bird-eye-view (BEV) guided masking strategy which effectively allows the model to pay attention to 3D features across heterogeneous V2X agents (i.e., vehicles and infrastructure) in the BEV space. Noticeably, such a masking strategy effectively pretrains the 3D encoder and is compatible with mainstream cooperative perception backbones. Our approach, validated through extensive experiments on representative datasets (i.e., V2X-Real, V2V4Real, and OPV2V), leads to a performance boost across all V2X settings. Additionally, we demonstrate the framework's improvements in cross-domain transferability, data efficiency, and robustness under challenging scenarios. The code will be made publicly available.
Towards Scalable Automated Alignment of LLMs: A Survey
Jun 03, 2024Alignment is the most critical step in building large language models (LLMs) that meet human needs. With the rapid development of LLMs gradually surpassing human capabilities, traditional alignment methods based on human-annotation are increasingly unable to meet the scalability demands. Therefore, there is an urgent need to explore new sources of automated alignment signals and technical approaches. In this paper, we systematically review the recently emerging methods of automated alignment, attempting to explore how to achieve effective, scalable, automated alignment once the capabilities of LLMs exceed those of humans. Specifically, we categorize existing automated alignment methods into 4 major categories based on the sources of alignment signals and discuss the current status and potential development of each category. Additionally, we explore the underlying mechanisms that enable automated alignment and discuss the essential factors that make automated alignment technologies feasible and effective from the fundamental role of alignment.
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.
Meta-Cognitive Analysis: Evaluating Declarative and Procedural Knowledge in Datasets and Large Language Models
Mar 14, 2024Declarative knowledge and procedural knowledge are two key parts in meta-cognitive theory, and these two hold significant importance in pre-training and inference of LLMs. However, a comprehensive analysis comparing these two types of knowledge is lacking, primarily due to challenges in definition, probing and quantitative assessment. In this paper, we explore from a new perspective by providing ground-truth knowledge for LLMs and evaluating the effective score. Through extensive experiments with widely-used datasets and models, we get conclusions: (1) In most tasks, benefits from declarative knowledge are greater than those from procedural knowledge. (2) Profits of procedural knowledge are larger than declarative knowledge only in reasoning tasks with simple logic. (3) As pre-training progresses and size increases, model ability to utilize both kinds of knowledge significantly improves, but in different speed. We do detailed analysis for the findings and this can provide primary guidance for evaluation and enhancement of large language models.
Optimizing the Placement of Roadside LiDARs for Autonomous Driving
Oct 11, 2023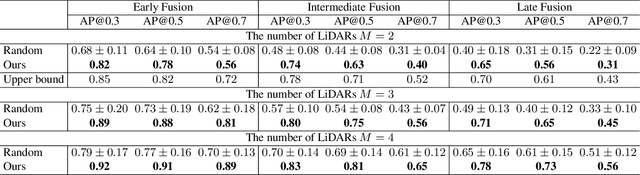
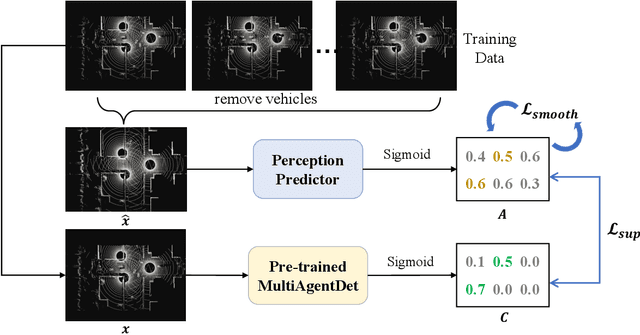
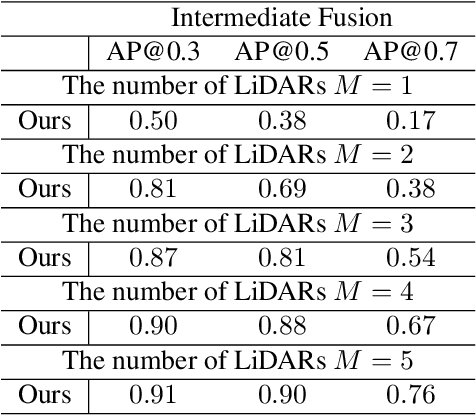

Multi-agent cooperative perception is an increasingly popular topic in the field of autonomous driving, where roadside LiDARs play an essential role. However, how to optimize the placement of roadside LiDARs is a crucial but often overlooked problem. This paper proposes an approach to optimize the placement of roadside LiDARs by selecting optimized positions within the scene for better perception performance. To efficiently obtain the best combination of locations, a greedy algorithm based on perceptual gain is proposed, which selects the location that can maximize the perceptual gain sequentially. We define perceptual gain as the increased perceptual capability when a new LiDAR is placed. To obtain the perception capability, we propose a perception predictor that learns to evaluate LiDAR placement using only a single point cloud frame. A dataset named Roadside-Opt is created using the CARLA simulator to facilitate research on the roadside LiDAR placement problem.