 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooPre: Cooperative Pretraining for V2X Cooperative Perception
Paper and Code
Aug 20, 2024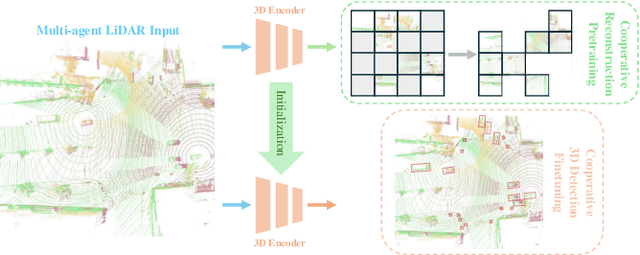
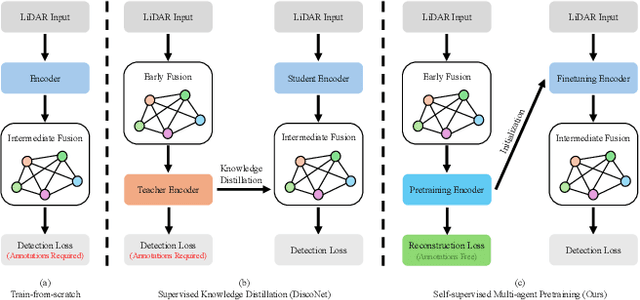

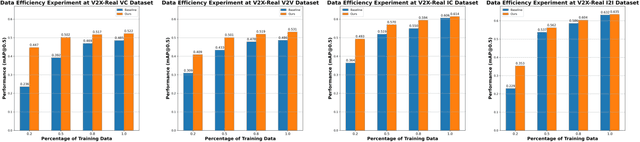
Existing Vehicle-to-Everything (V2X) cooperative perception methods rely on accurate multi-agent 3D annotations. Nevertheless, it is time-consuming and expensive to collect and annotate real-world data, especially for V2X systems. In this paper, we present a self-supervised learning method for V2X cooperative perception, which utilizes the vast amount of unlabeled 3D V2X data to enhance the perception performance. Beyond simply extending the previous pre-training methods for point-cloud representation learning, we introduce a novel self-supervised Cooperative Pretraining framework (termed as CooPre) customized for a collaborative scenario. We point out that cooperative point-cloud sensing compensates for information loss among agents. This motivates us to design a novel proxy task for the 3D encoder to reconstruct LiDAR point clouds across different agents. Besides, we develop a V2X bird-eye-view (BEV) guided masking strategy which effectively allows the model to pay attention to 3D features across heterogeneous V2X agents (i.e., vehicles and infrastructure) in the BEV space. Noticeably, such a masking strategy effectively pretrains the 3D encoder and is compatible with mainstream cooperative perception backbones. Our approach, validated through extensive experiments on representative datasets (i.e., V2X-Real, V2V4Real, and OPV2V), leads to a performance boost across all V2X settings. Additionally, we demonstrate the framework's improvements in cross-domain transferability, data efficiency, and robustness under challenging scenarios. The code will be made publicly available.