 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
Vanishing Bias Heuristic-guided Reinforcement Learning Algorithm
Jun 17, 2023

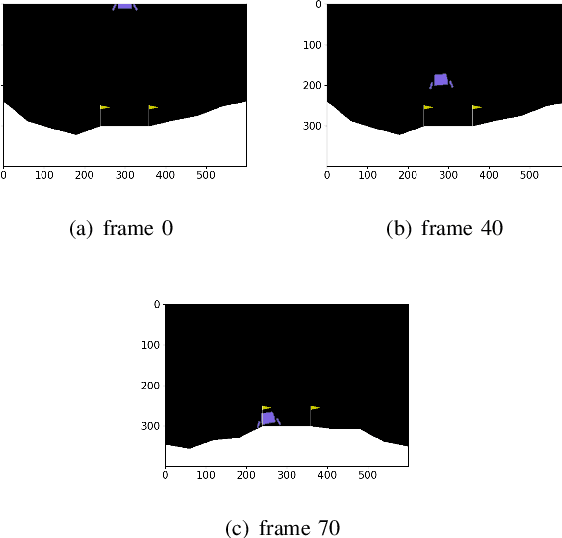
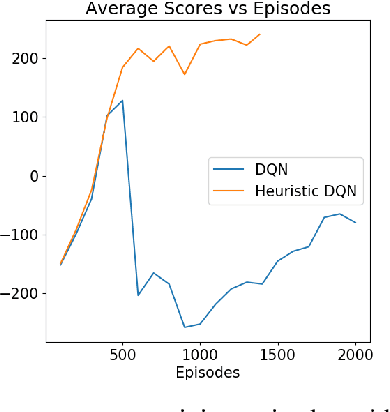
Reinforcement Learning has achieved tremendous success in the many Atari games. In this paper we explored with the lunar lander environment and implemented classical methods including Q-Learning, SARSA, MC as well as tiling coding. We also implemented Neural Network based methods including DQN, Double DQN, Clipped DQN. On top of these, we proposed a new algorithm called Heuristic RL which utilizes heuristic to guide the early stage training while alleviating the introduced human bias. Our experiments showed promising results for our proposed methods in the lunar lander environment.
Probabilistic Semantic Mapping for Urban Autonomous Driving Applications
Jun 08, 2020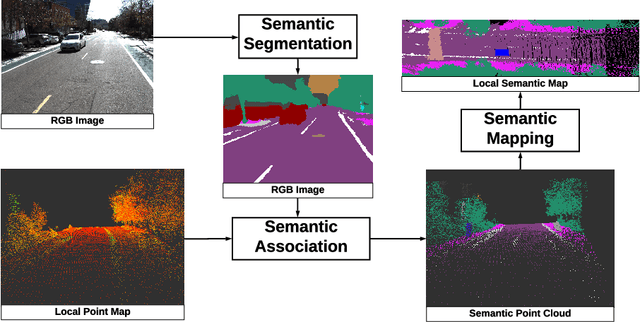
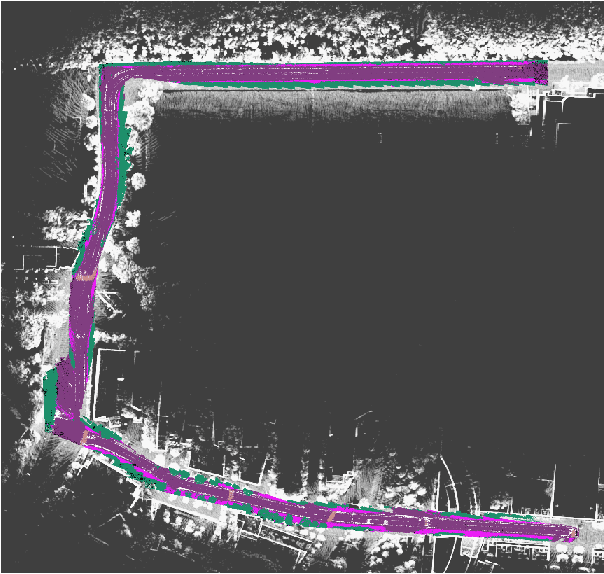

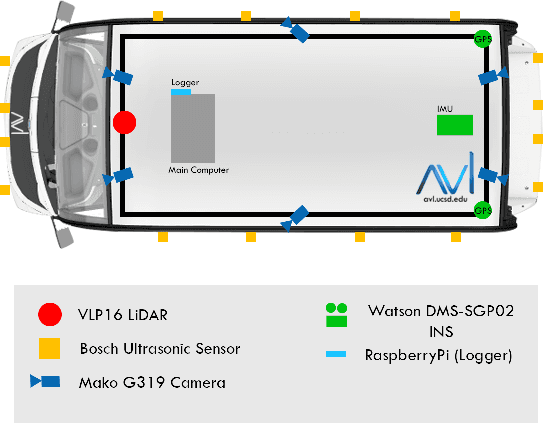
Recent advancement in statistical learning and computational ability has enabled autonomous vehicle technology to develop at a much faster rate and become widely adopted. While many of the architectures previously introduced are capable of operating under highly dynamic environments, many of these are constrained to smaller-scale deployments and require constant maintenance due to the associated scalability cost with high-definition (HD) maps. HD maps provide critical information for self-driving cars to drive safely. However, traditional approaches for creating HD maps involves tedious manual labeling. As an attempt to tackle this problem, we fuse 2D image semantic segmentation with pre-built point cloud maps collected from a relatively inexpensive 16 channel LiDAR sensor to construct a local probabilistic semantic map in bird's eye view that encodes static landmarks such as roads, sidewalks, crosswalks, and lanes in the driving environment. Experiments from data collected in an urban environment show that this model can be extended for automatically incorporating road features into HD maps with potential future work directions.