 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion
May 25, 2026Generating complete digital twins from videos requires precise camera control, global scene coverage, and strict spatial-temporal consistency constraints that remain challenging for perspective video generators due to their limited field of view (FoV). Their narrow FoV forces long or multi-view trajectories, amplifying cross-view inconsistency and temporal drift. We argue that 360° video generation offers a natural solution: panoramic coverage simplifies trajectory design and provides a strong global context for maintaining coherence. We introduce Pantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion, a controllable 360° video generation framework that synthesizes high-fidelity videos from sparse 360° inputs. The key idea is an explicit 3D Cache, reconstructed from the input, which serves as a geometric scaffold for any user-defined camera path. This allows the diffusion model to focus on photorealistic texture refinement while the 3D Cache enforces global geometric consistency. Experiments show that Pantheon360 achieves superior visual quality and unmatched geometric coherence, enabling reliable and flexible 360° scene generation for downstream simulation and digital-twin applications.
Adapting Reinforcement Learning for Path Planning in Constrained Parking Scenarios
Jan 30, 2026Real-time path planning in constrained environments remains a fundamental challenge for autonomous systems. Traditional classical planners, while effective under perfect perception assumptions, are often sensitive to real-world perception constraints and rely on online search procedures that incur high computational costs. In complex surroundings, this renders real-time deployment prohibitive. To overcome these limitations, we introduce a Deep Reinforcement Learning (DRL) framework for real-time path planning in parking scenarios. In particular, we focus on challenging scenes with tight spaces that require a high number of reversal maneuvers and adjustments. Unlike classical planners, our solution does not require ideal and structured perception, and in principle, could avoid the need for additional modules such as localization and tracking, resulting in a simpler and more practical implementation. Also, at test time, the policy generates actions through a single forward pass at each step, which is lightweight enough for real-time deployment. The task is formulated as a sequential decision-making problem grounded in a bicycle model dynamics, enabling the agent to directly learn navigation policies that respect vehicle kinematics and environmental constraints in the closed-loop setting. A new benchmark is developed to support both training and evaluation, capturing diverse and challenging scenarios. Our approach achieves state-of-the-art success rates and efficiency, surpassing classical planner baselines by +96% in success rate and +52% in efficiency. Furthermore, we release our benchmark as an open-source resource for the community to foster future research in autonomous systems. The benchmark and accompanying tools are available at https://github.com/dqm5rtfg9b-collab/Constrained_Parking_Scenarios.
SMART: Advancing Scalable Map Priors for Driving Topology Reasoning
Feb 06, 2025Topology reasoning is crucial for autonomous driving as it enables comprehensive understanding of connectivity and relationships between lanes and traffic elements. While recent approaches have shown success in perceiving driving topology using vehicle-mounted sensors, their scalability is hindered by the reliance on training data captured by consistent sensor configurations. We identify that the key factor in scalable lane perception and topology reasoning is the elimination of this sensor-dependent feature. To address this, we propose SMART, a scalable solution that leverages easily available standard-definition (SD) and satellite maps to learn a map prior model, supervised by large-scale geo-referenced high-definition (HD) maps independent of sensor settings. Attributed to scaled training, SMART alone achieves superior offline lane topology understanding using only SD and satellite inputs. Extensive experiments further demonstrate that SMART can be seamlessly integrated into any online topology reasoning methods, yielding significant improvements of up to 28% on the OpenLane-V2 benchmark.
MapGS: Generalizable Pretraining and Data Augmentation for Online Mapping via Novel View Synthesis
Jan 11, 2025Online mapping reduces the reliance of autonomous vehicles on high-definition (HD) maps, significantly enhancing scalability. However, recent advancements often overlook cross-sensor configuration generalization, leading to performance degradation when models are deployed on vehicles with different camera intrinsics and extrinsics. With the rapid evolution of novel view synthesis methods, we investigate the extent to which these techniques can be leveraged to address the sensor configuration generalization challenge. We propose a novel framework leveraging Gaussian splatting to reconstruct scenes and render camera images in target sensor configurations. The target config sensor data, along with labels mapped to the target config, are used to train online mapping models. Our proposed framework on the nuScenes and Argoverse 2 datasets demonstrates a performance improvement of 18% through effective dataset augmentation, achieves faster convergence and efficient training, and exceeds state-of-the-art performance when using only 25% of the original training data. This enables data reuse and reduces the need for laborious data labeling. Project page at https://henryzhangzhy.github.io/mapgs.
Enhancing Online Road Network Perception and Reasoning with Standard Definition Maps
Aug 01, 2024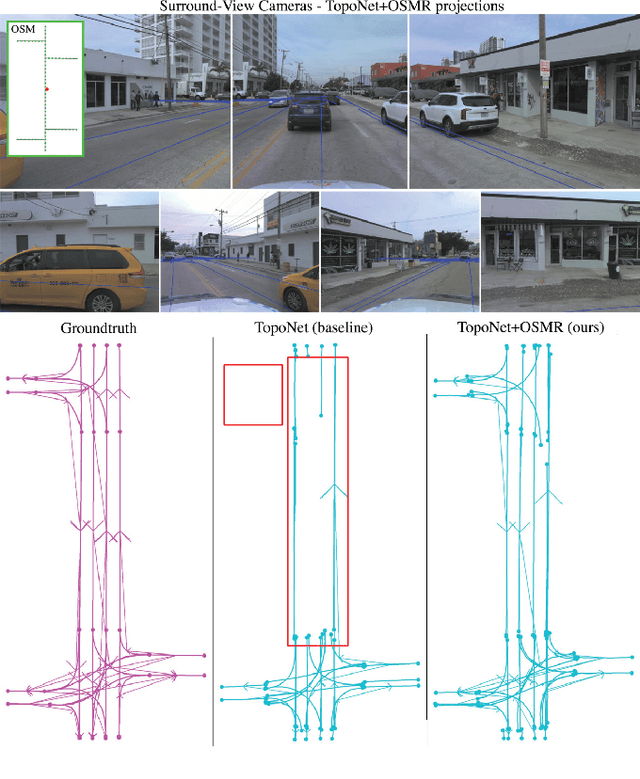
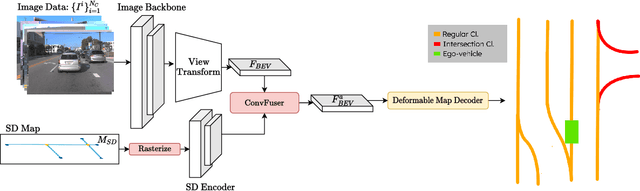
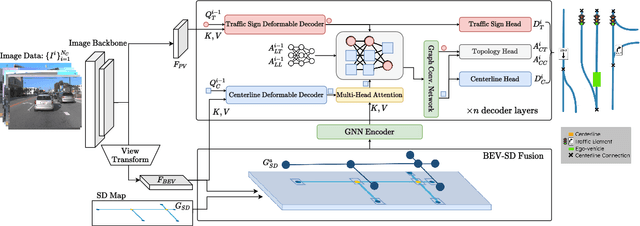
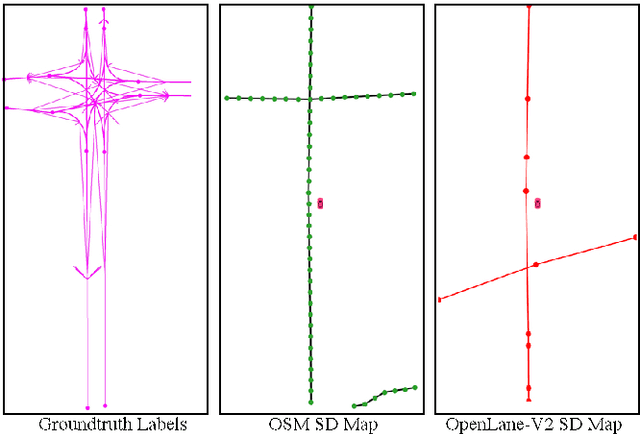
Autonomous driving for urban and highway driving applications often requires High Definition (HD) maps to generate a navigation plan. Nevertheless, various challenges arise when generating and maintaining HD maps at scale. While recent online mapping methods have started to emerge, their performance especially for longer ranges is limited by heavy occlusion in dynamic environments. With these considerations in mind, our work focuses on leveraging lightweight and scalable priors-Standard Definition (SD) maps-in the development of online vectorized HD map representations. We first examine the integration of prototypical rasterized SD map representations into various online mapping architectures. Furthermore, to identify lightweight strategies, we extend the OpenLane-V2 dataset with OpenStreetMaps and evaluate the benefits of graphical SD map representations. A key finding from designing SD map integration components is that SD map encoders are model agnostic and can be quickly adapted to new architectures that utilize bird's eye view (BEV) encoders. Our results show that making use of SD maps as priors for the online mapping task can significantly speed up convergence and boost the performance of the online centerline perception task by 30% (mAP). Furthermore, we show that the introduction of the SD maps leads to a reduction of the number of parameters in the perception and reasoning task by leveraging SD map graphs while improving the overall performance. Project Page: https://henryzhangzhy.github.io/sdhdmap/.
OSM vs HD Maps: Map Representations for Trajectory Prediction
Nov 04, 2023While High Definition (HD) Maps have long been favored for their precise depictions of static road elements, their accessibility constraints and susceptibility to rapid environmental changes impede the widespread deployment of autonomous driving, especially in the motion forecasting task. In this context, we propose to leverage OpenStreetMap (OSM) as a promising alternative to HD Maps for long-term motion forecasting. The contributions of this work are threefold: firstly, we extend the application of OSM to long-horizon forecasting, doubling the forecasting horizon compared to previous studies. Secondly, through an expanded receptive field and the integration of intersection priors, our OSM-based approach exhibits competitive performance, narrowing the gap with HD Map-based models. Lastly, we conduct an exhaustive context-aware analysis, providing deeper insights in motion forecasting across diverse scenarios as well as conducting class-aware comparisons. This research not only advances long-term motion forecasting with coarse map representations but additionally offers a potential scalable solution within the domain of autonomous driving.
Occlusion-Aware 2D and 3D Centerline Detection for Urban Driving via Automatic Label Generation
Nov 03, 2023


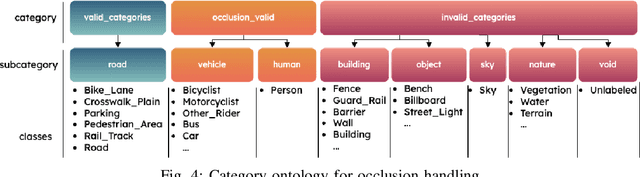
This research work seeks to explore and identify strategies that can determine road topology information in 2D and 3D under highly dynamic urban driving scenarios. To facilitate this exploration, we introduce a substantial dataset comprising nearly one million automatically labeled data frames. A key contribution of our research lies in developing an automatic label-generation process and an occlusion handling strategy. This strategy is designed to model a wide range of occlusion scenarios, from mild disruptions to severe blockages. Furthermore, we present a comprehensive ablation study wherein multiple centerline detection methods are developed and evaluated. This analysis not only benchmarks the performance of various approaches but also provides valuable insights into the interpretability of these methods. Finally, we demonstrate the practicality of our methods and assess their adaptability across different sensor configurations, highlighting their versatility and relevance in real-world scenarios. Our dataset and experimental models are publicly available.
CLiNet: Joint Detection of Road Network Centerlines in 2D and 3D
Feb 04, 2023This work introduces a new approach for joint detection of centerlines based on image data by localizing the features jointly in 2D and 3D. In contrast to existing work that focuses on detection of visual cues, we explore feature extraction methods that are directly amenable to the urban driving task. To develop and evaluate our approach, a large urban driving dataset dubbed AV Breadcrumbs is automatically labeled by leveraging vector map representations and projective geometry to annotate over 900,000 images. Our results demonstrate potential for dynamic scene modeling across various urban driving scenarios. Our model achieves an F1 score of 0.684 and an average normalized depth error of 2.083. The code and data annotations are publicly available.
Robust Human Identity Anonymization using Pose Estimation
Jan 10, 2023Many outdoor autonomous mobile platforms require more human identity anonymized data to power their data-driven algorithms. The human identity anonymization should be robust so that less manual intervention is needed, which remains a challenge for current face detection and anonymization systems. In this paper, we propose to use the skeleton generated from the state-of-the-art human pose estimation model to help localize human heads. We develop criteria to evaluate the performance and compare it with the face detection approach. We demonstrate that the proposed algorithm can reduce missed faces and thus better protect the identity information for the pedestrians. We also develop a confidence-based fusion method to further improve the performance.
* Source code will be available at https://github.com/AutonomousVehicleLaboratory/anonymization
TridentNetV2: Lightweight Graphical Global Plan Representations for Dynamic Trajectory Generation
Mar 26, 2022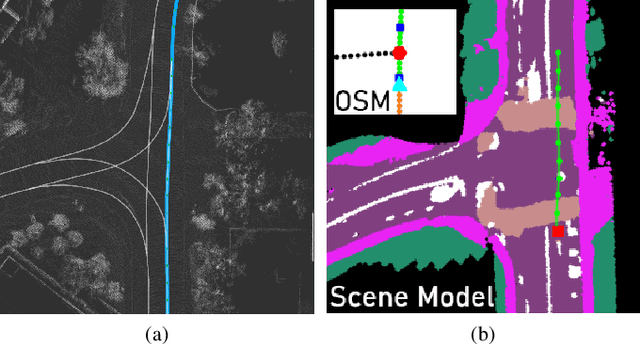
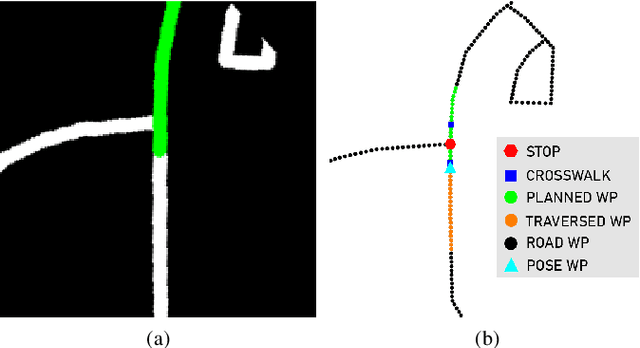
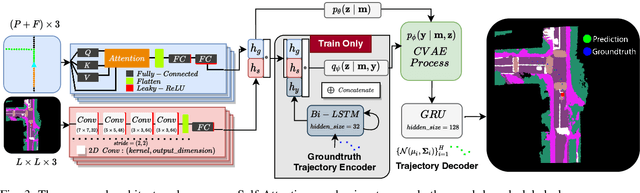
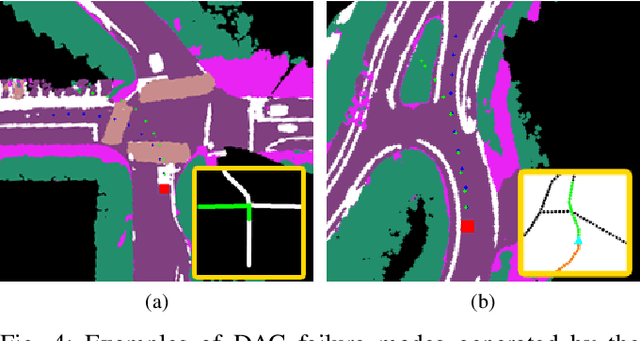
We present a framework for dynamic trajectory generation for autonomous navigation, which does not rely on HD maps as the underlying representation. High Definition (HD) maps have become a key component in most autonomous driving frameworks, which include complete road network information annotated at a centimeter-level that include traversable waypoints, lane information, and traffic signals. Instead, the presented approach models the distributions of feasible ego-centric trajectories in real-time given a nominal graph-based global plan and a lightweight scene representation. By embedding contextual information, such as crosswalks, stop signs, and traffic signals, our approach achieves low errors across multiple urban navigation datasets that include diverse intersection maneuvers, while maintaining real-time performance and reducing network complexity. Underlying datasets introduced are available online.