 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping an AI-based Integrated System for Bee Health Evaluation
Jan 18, 2024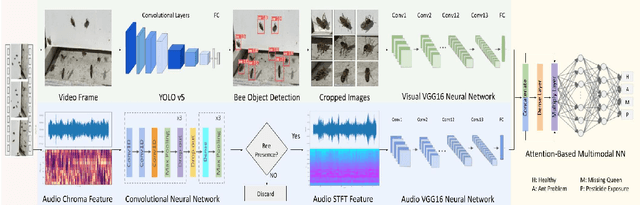
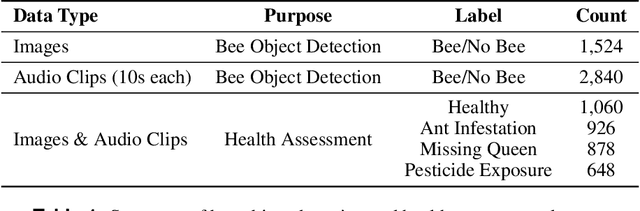
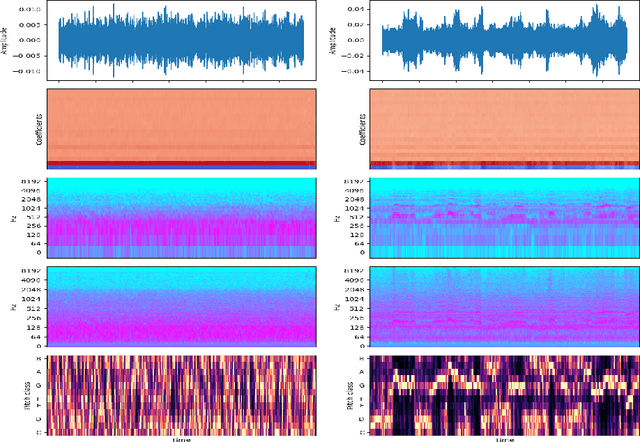
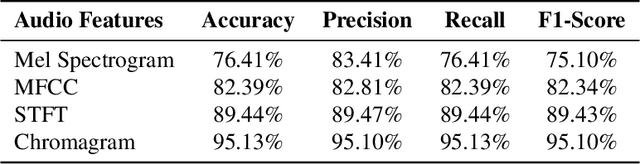
Honey bees pollinate about one-third of the world's food supply, but bee colonies have alarmingly declined by nearly 40% over the past decade due to several factors, including pesticides and pests. Traditional methods for monitoring beehives, such as human inspection, are subjective, disruptive, and time-consuming. To overcome these limitations, artificial intelligence has been used to assess beehive health. However, previous studies have lacked an end-to-end solution and primarily relied on data from a single source, either bee images or sounds. This study introduces a comprehensive system consisting of bee object detection and health evaluation. Additionally, it utilized a combination of visual and audio signals to analyze bee behaviors. An Attention-based Multimodal Neural Network (AMNN) was developed to adaptively focus on key features from each type of signal for accurate bee health assessment. The AMNN achieved an overall accuracy of 92.61%, surpassing eight existing single-signal Convolutional Neural Networks and Recurrent Neural Networks. It outperformed the best image-based model by 32.51% and the top sound-based model by 13.98% while maintaining efficient processing times. Furthermore, it improved prediction robustness, attaining an F1-score higher than 90% across all four evaluated health conditions. The study also shows that audio signals are more reliable than images for assessing bee health. By seamlessly integrating AMNN with image and sound data in a comprehensive bee health monitoring system, this approach provides a more efficient and non-invasive solution for the early detection of bee diseases and the preservation of bee colonies.
TridentNetV2: Lightweight Graphical Global Plan Representations for Dynamic Trajectory Generation
Mar 26, 2022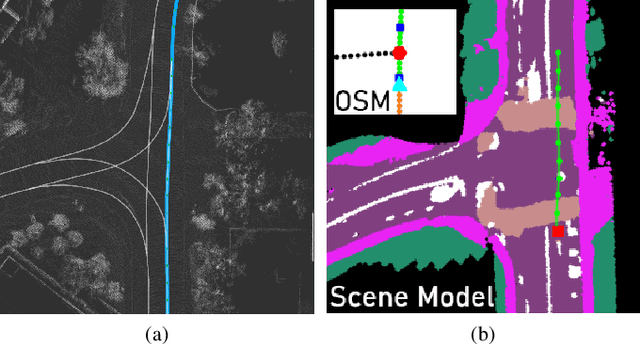
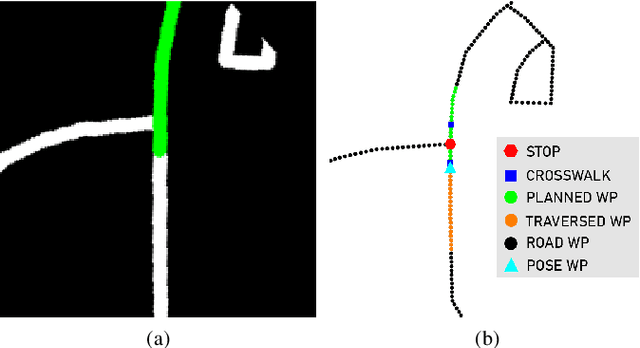
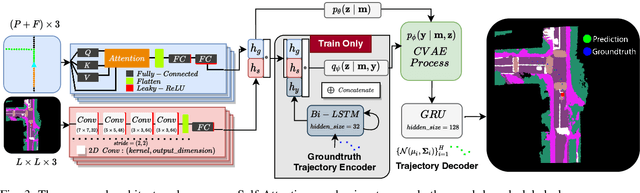
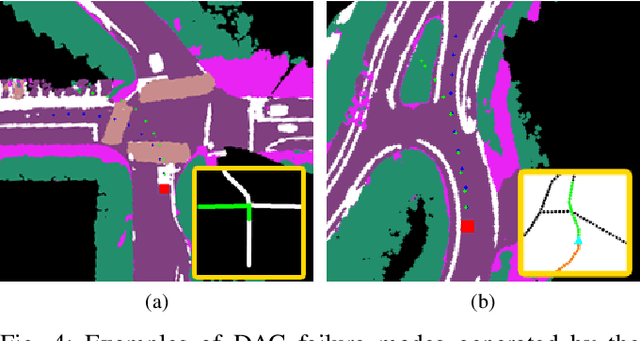
We present a framework for dynamic trajectory generation for autonomous navigation, which does not rely on HD maps as the underlying representation. High Definition (HD) maps have become a key component in most autonomous driving frameworks, which include complete road network information annotated at a centimeter-level that include traversable waypoints, lane information, and traffic signals. Instead, the presented approach models the distributions of feasible ego-centric trajectories in real-time given a nominal graph-based global plan and a lightweight scene representation. By embedding contextual information, such as crosswalks, stop signs, and traffic signals, our approach achieves low errors across multiple urban navigation datasets that include diverse intersection maneuvers, while maintaining real-time performance and reducing network complexity. Underlying datasets introduced are available online.
Egocentric Prediction of Action Target in 3D
Mar 24, 2022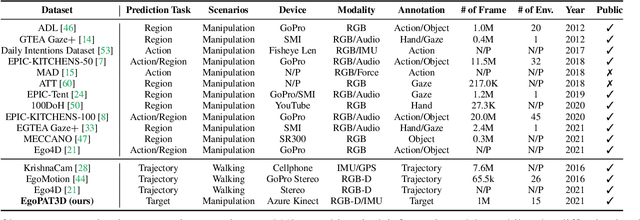
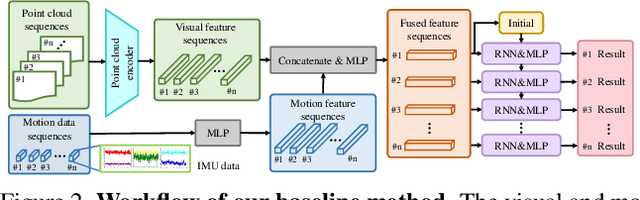
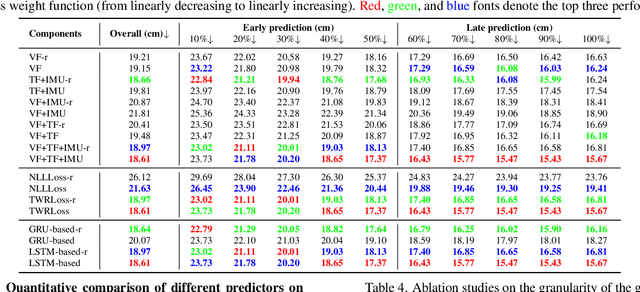

We are interested in anticipating as early as possible the target location of a person's object manipulation action in a 3D workspace from egocentric vision. It is important in fields like human-robot collaboration, but has not yet received enough attention from vision and learning communities. To stimulate more research on this challenging egocentric vision task, we propose a large multimodality dataset of more than 1 million frames of RGB-D and IMU streams, and provide evaluation metrics based on our high-quality 2D and 3D labels from semi-automatic annotation. Meanwhile, we design baseline methods using recurrent neural networks and conduct various ablation studies to validate their effectiveness. Our results demonstrate that this new task is worthy of further study by researchers in robotics, vision, and learning communities.