 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Nov 17, 20253D modeling is shifting from static visual representations toward physical, articulated assets that can be directly used in simulation and interaction. However, most existing 3D generation methods overlook key physical and articulation properties, thereby limiting their utility in embodied AI. To bridge this gap, we introduce PhysX-Anything, the first simulation-ready physical 3D generative framework that, given a single in-the-wild image, produces high-quality sim-ready 3D assets with explicit geometry, articulation, and physical attributes. Specifically, we propose the first VLM-based physical 3D generative model, along with a new 3D representation that efficiently tokenizes geometry. It reduces the number of tokens by 193x, enabling explicit geometry learning within standard VLM token budgets without introducing any special tokens during fine-tuning and significantly improving generative quality. In addition, to overcome the limited diversity of existing physical 3D datasets, we construct a new dataset, PhysX-Mobility, which expands the object categories in prior physical 3D datasets by over 2x and includes more than 2K common real-world objects with rich physical annotations. Extensive experiments on PhysX-Mobility and in-the-wild images demonstrate that PhysX-Anything delivers strong generative performance and robust generalization. Furthermore, simulation-based experiments in a MuJoCo-style environment validate that our sim-ready assets can be directly used for contact-rich robotic policy learning. We believe PhysX-Anything can substantially empower a broad range of downstream applications, especially in embodied AI and physics-based simulation.
Collaborative Multi-Modal Coding for High-Quality 3D Generation
Aug 21, 20253D content inherently encompasses multi-modal characteristics and can be projected into different modalities (e.g., RGB images, RGBD, and point clouds). Each modality exhibits distinct advantages in 3D asset modeling: RGB images contain vivid 3D textures, whereas point clouds define fine-grained 3D geometries. However, most existing 3D-native generative architectures either operate predominantly within single-modality paradigms-thus overlooking the complementary benefits of multi-modality data-or restrict themselves to 3D structures, thereby limiting the scope of available training datasets. To holistically harness multi-modalities for 3D modeling, we present TriMM, the first feed-forward 3D-native generative model that learns from basic multi-modalities (e.g., RGB, RGBD, and point cloud). Specifically, 1) TriMM first introduces collaborative multi-modal coding, which integrates modality-specific features while preserving their unique representational strengths. 2) Furthermore, auxiliary 2D and 3D supervision are introduced to raise the robustness and performance of multi-modal coding. 3) Based on the embedded multi-modal code, TriMM employs a triplane latent diffusion model to generate 3D assets of superior quality, enhancing both the texture and the geometric detail. Extensive experiments on multiple well-known datasets demonstrate that TriMM, by effectively leveraging multi-modality, achieves competitive performance with models trained on large-scale datasets, despite utilizing a small amount of training data. Furthermore, we conduct additional experiments on recent RGB-D datasets, verifying the feasibility of incorporating other multi-modal datasets into 3D generation.
PhysX: Physical-Grounded 3D Asset Generation
Jul 16, 2025



3D modeling is moving from virtual to physical. Existing 3D generation primarily emphasizes geometries and textures while neglecting physical-grounded modeling. Consequently, despite the rapid development of 3D generative models, the synthesized 3D assets often overlook rich and important physical properties, hampering their real-world application in physical domains like simulation and embodied AI. As an initial attempt to address this challenge, we propose \textbf{PhysX}, an end-to-end paradigm for physical-grounded 3D asset generation. 1) To bridge the critical gap in physics-annotated 3D datasets, we present PhysXNet - the first physics-grounded 3D dataset systematically annotated across five foundational dimensions: absolute scale, material, affordance, kinematics, and function description. In particular, we devise a scalable human-in-the-loop annotation pipeline based on vision-language models, which enables efficient creation of physics-first assets from raw 3D assets.2) Furthermore, we propose \textbf{PhysXGen}, a feed-forward framework for physics-grounded image-to-3D asset generation, injecting physical knowledge into the pre-trained 3D structural space. Specifically, PhysXGen employs a dual-branch architecture to explicitly model the latent correlations between 3D structures and physical properties, thereby producing 3D assets with plausible physical predictions while preserving the native geometry quality. Extensive experiments validate the superior performance and promising generalization capability of our framework. All the code, data, and models will be released to facilitate future research in generative physical AI.
DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
May 13, 2024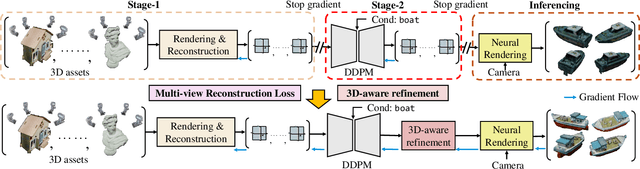
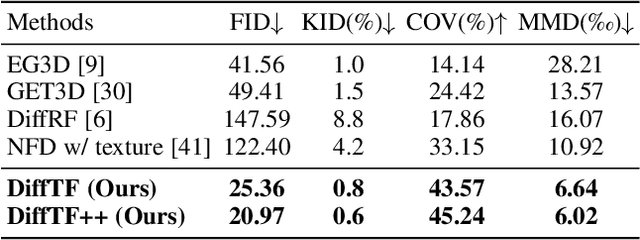

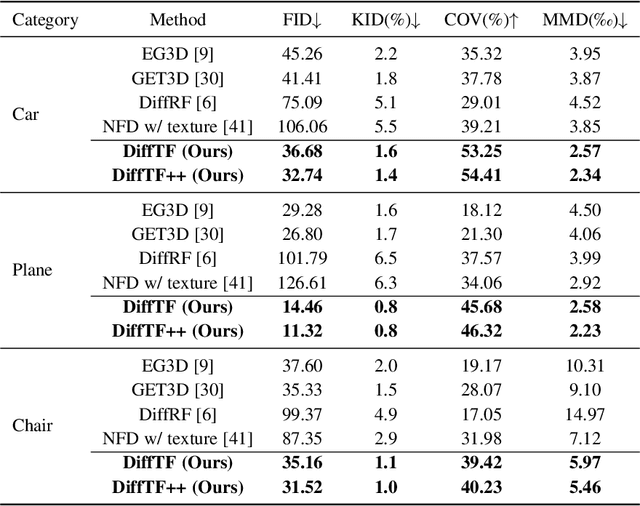
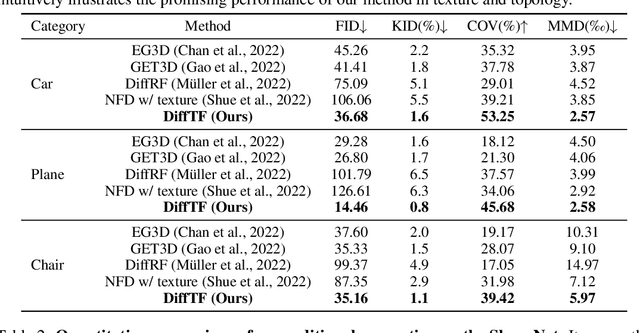
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors
Mar 04, 2024



We present a two-stage text-to-3D generation system, namely 3DTopia, which generates high-quality general 3D assets within 5 minutes using hybrid diffusion priors. The first stage samples from a 3D diffusion prior directly learned from 3D data. Specifically, it is powered by a text-conditioned tri-plane latent diffusion model, which quickly generates coarse 3D samples for fast prototyping. The second stage utilizes 2D diffusion priors to further refine the texture of coarse 3D models from the first stage. The refinement consists of both latent and pixel space optimization for high-quality texture generation. To facilitate the training of the proposed system, we clean and caption the largest open-source 3D dataset, Objaverse, by combining the power of vision language models and large language models. Experiment results are reported qualitatively and quantitatively to show the performance of the proposed system. Our codes and models are available at https://github.com/3DTopia/3DTopia
Large-Vocabulary 3D Diffusion Model with Transformer
Sep 15, 2023
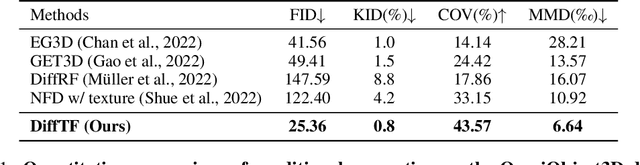
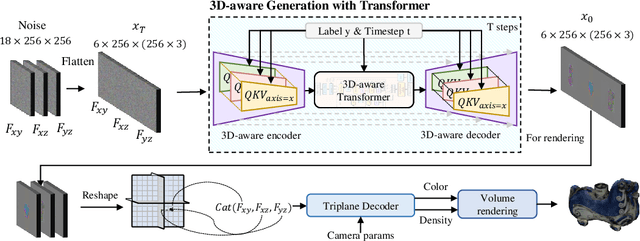
Creating diverse and high-quality 3D assets with an automatic generative model is highly desirable. Despite extensive efforts on 3D generation, most existing works focus on the generation of a single category or a few categories. In this paper, we introduce a diffusion-based feed-forward framework for synthesizing massive categories of real-world 3D objects with a single generative model. Notably, there are three major challenges for this large-vocabulary 3D generation: a) the need for expressive yet efficient 3D representation; b) large diversity in geometry and texture across categories; c) complexity in the appearances of real-world objects. To this end, we propose a novel triplane-based 3D-aware Diffusion model with TransFormer, DiffTF, for handling challenges via three aspects. 1) Considering efficiency and robustness, we adopt a revised triplane representation and improve the fitting speed and accuracy. 2) To handle the drastic variations in geometry and texture, we regard the features of all 3D objects as a combination of generalized 3D knowledge and specialized 3D features. To extract generalized 3D knowledge from diverse categories, we propose a novel 3D-aware transformer with shared cross-plane attention. It learns the cross-plane relations across different planes and aggregates the generalized 3D knowledge with specialized 3D features. 3) In addition, we devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge in the encoded triplanes for handling categories with complex appearances. Extensive experiments on ShapeNet and OmniObject3D (over 200 diverse real-world categories) convincingly demonstrate that a single DiffTF model achieves state-of-the-art large-vocabulary 3D object generation performance with large diversity, rich semantics, and high quality.
Towards Real-World Visual Tracking with Temporal Contexts
Aug 20, 2023Visual tracking has made significant improvements in the past few decades. Most existing state-of-the-art trackers 1) merely aim for performance in ideal conditions while overlooking the real-world conditions; 2) adopt the tracking-by-detection paradigm, neglecting rich temporal contexts; 3) only integrate the temporal information into the template, where temporal contexts among consecutive frames are far from being fully utilized. To handle those problems, we propose a two-level framework (TCTrack) that can exploit temporal contexts efficiently. Based on it, we propose a stronger version for real-world visual tracking, i.e., TCTrack++. It boils down to two levels: features and similarity maps. Specifically, for feature extraction, we propose an attention-based temporally adaptive convolution to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights. For similarity map refinement, we introduce an adaptive temporal transformer to encode the temporal knowledge efficiently and decode it for the accurate refinement of the similarity map. To further improve the performance, we additionally introduce a curriculum learning strategy. Also, we adopt online evaluation to measure performance in real-world conditions. Exhaustive experiments on 8 wellknown benchmarks demonstrate the superiority of TCTrack++. Real-world tests directly verify that TCTrack++ can be readily used in real-world applications.
What Went Wrong? Closing the Sim-to-Real Gap via Differentiable Causal Discovery
Jun 28, 2023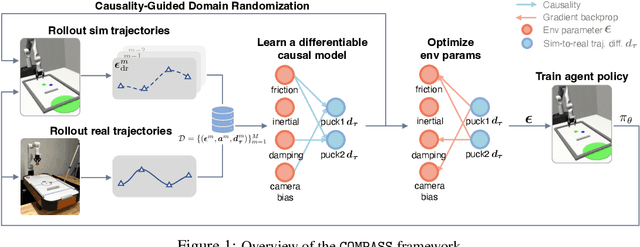

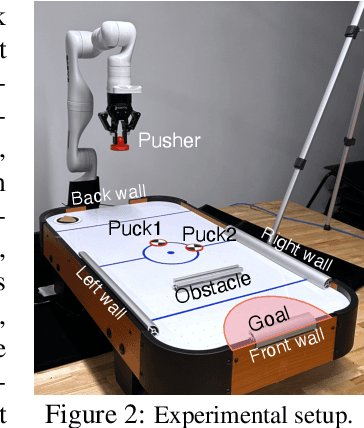

Training control policies in simulation is more appealing than on real robots directly, as it allows for exploring diverse states in a safe and efficient manner. Yet, robot simulators inevitably exhibit disparities from the real world, yielding inaccuracies that manifest as the simulation-to-real gap. Existing literature has proposed to close this gap by actively modifying specific simulator parameters to align the simulated data with real-world observations. However, the set of tunable parameters is usually manually selected to reduce the search space in a case-by-case manner, which is hard to scale up for complex systems and requires extensive domain knowledge. To address the scalability issue and automate the parameter-tuning process, we introduce an approach that aligns the simulator with the real world by discovering the causal relationship between the environment parameters and the sim-to-real gap. Concretely, our method learns a differentiable mapping from the environment parameters to the differences between simulated and real-world robot-object trajectories. This mapping is governed by a simultaneously-learned causal graph to help prune the search space of parameters, provide better interpretability, and improve generalization. We perform experiments to achieve both sim-to-sim and sim-to-real transfer, and show that our method has significant improvements in trajectory alignment and task success rate over strong baselines in a challenging manipulation task.
Tracker Meets Night: A Transformer Enhancer for UAV Tracking
Mar 20, 2023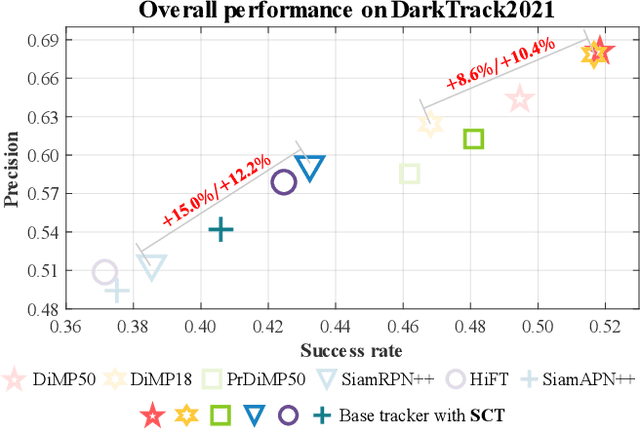
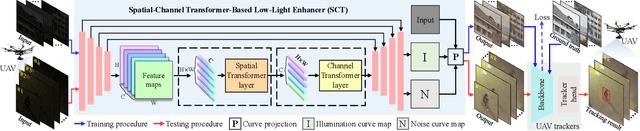
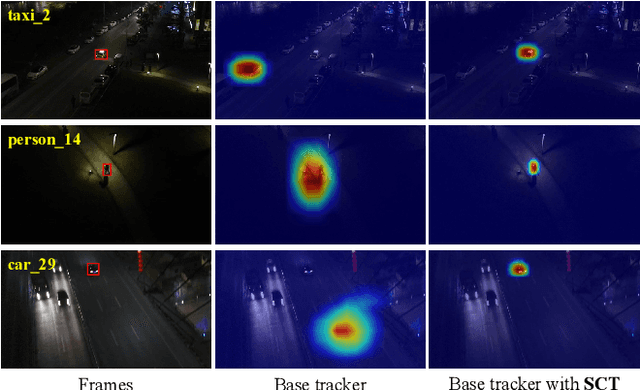
Most previous progress in object tracking is realized in daytime scenes with favorable illumination. State-of-the-arts can hardly carry on their superiority at night so far, thereby considerably blocking the broadening of visual tracking-related unmanned aerial vehicle (UAV) applications. To realize reliable UAV tracking at night, a spatial-channel Transformer-based low-light enhancer (namely SCT), which is trained in a novel task-inspired manner, is proposed and plugged prior to tracking approaches. To achieve semantic-level low-light enhancement targeting the high-level task, the novel spatial-channel attention module is proposed to model global information while preserving local context. In the enhancement process, SCT denoises and illuminates nighttime images simultaneously through a robust non-linear curve projection. Moreover, to provide a comprehensive evaluation, we construct a challenging nighttime tracking benchmark, namely DarkTrack2021, which contains 110 challenging sequences with over 100 K frames in total. Evaluations on both the public UAVDark135 benchmark and the newly constructed DarkTrack2021 benchmark show that the task-inspired design enables SCT with significant performance gains for nighttime UAV tracking compared with other top-ranked low-light enhancers. Real-world tests on a typical UAV platform further verify the practicability of the proposed approach. The DarkTrack2021 benchmark and the code of the proposed approach are publicly available at https://github.com/vision4robotics/SCT.
Local Perception-Aware Transformer for Aerial Tracking
Aug 06, 2022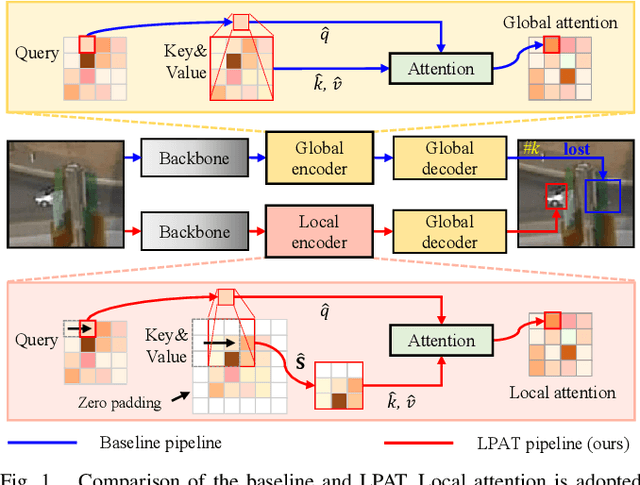
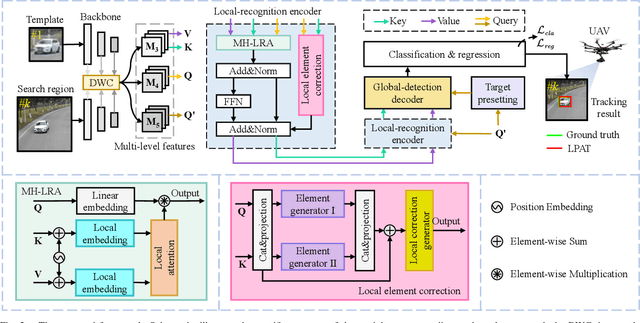
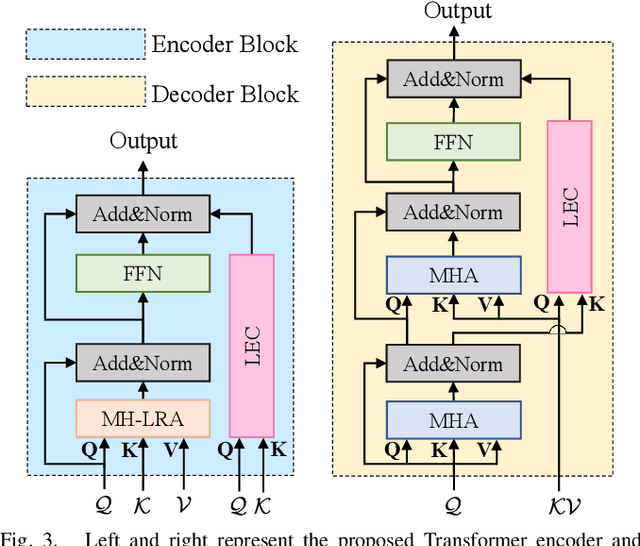

Transformer-based visual object tracking has been utilized extensively. However, the Transformer structure is lack of enough inductive bias. In addition, only focusing on encoding the global feature does harm to modeling local details, which restricts the capability of tracking in aerial robots. Specifically, with local-modeling to global-search mechanism, the proposed tracker replaces the global encoder by a novel local-recognition encoder. In the employed encoder, a local-recognition attention and a local element correction network are carefully designed for reducing the global redundant information interference and increasing local inductive bias. Meanwhile, the latter can model local object details precisely under aerial view through detail-inquiry net. The proposed method achieves competitive accuracy and robustness in several authoritative aerial benchmarks with 316 sequences in total. The proposed tracker's practicability and efficiency have been validated by the real-world tests.