 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Versatile Humanoid Manipulation with Touch Dreaming
Apr 14, 2026Humanoid robots promise general-purpose assistance, yet real-world humanoid loco-manipulation remains challenging because it requires whole-body stability, dexterous hands, and contact-aware perception under frequent contact changes. In this work, we study dexterous, contact-rich humanoid loco-manipulation. We first develop an RL-based whole-body controller that provides stable lower-body and torso execution during complex manipulation. Built on this controller, we develop a whole-body humanoid data collection system that combines VR-based teleoperation with human-to-humanoid motion mapping, enabling efficient collection of real-world demonstrations. We then propose Humanoid Transformer with Touch Dreaming (HTD), a multimodal encoder--decoder Transformer that models touch as a core modality alongside multi-view vision and proprioception. HTD is trained in a single stage with behavioral cloning augmented by touch dreaming: in addition to predicting action chunks, the policy predicts future hand-joint forces and future tactile latents, encouraging the shared Transformer trunk to learn contact-aware representations for dexterous interaction. Across five contact-rich tasks, Insert-T, Book Organization, Towel Folding, Cat Litter Scooping, and Tea Serving, HTD achieves a 90.9% relative improvement in average success rate over the stronger baseline. Ablation results further show that latent-space tactile prediction is more effective than raw tactile prediction, yielding a 30% relative gain in success rate. These results demonstrate that combining robust whole-body execution, scalable humanoid data collection, and predictive touch-centered learning enables versatile, high-dexterity humanoid manipulation in the real world. Project webpage: humanoid-touch-dream.github.io.
APEX: Learning Adaptive High-Platform Traversal for Humanoid Robots
Feb 11, 2026Humanoid locomotion has advanced rapidly with deep reinforcement learning (DRL), enabling robust feet-based traversal over uneven terrain. Yet platforms beyond leg length remain largely out of reach because current RL training paradigms often converge to jumping-like solutions that are high-impact, torque-limited, and unsafe for real-world deployment. To address this gap, we propose APEX, a system for perceptive, climbing-based high-platform traversal that composes terrain-conditioned behaviors: climb-up and climb-down at vertical edges, walking or crawling on the platform, and stand-up and lie-down for posture reconfiguration. Central to our approach is a generalized ratchet progress reward for learning contact-rich, goal-reaching maneuvers. It tracks the best-so-far task progress and penalizes non-improving steps, providing dense yet velocity-free supervision that enables efficient exploration under strong safety regularization. Based on this formulation, we train LiDAR-based full-body maneuver policies and reduce the sim-to-real perception gap through a dual strategy: modeling mapping artifacts during training and applying filtering and inpainting to elevation maps during deployment. Finally, we distill all six skills into a single policy that autonomously selects behaviors and transitions based on local geometry and commands. Experiments on a 29-DoF Unitree G1 humanoid demonstrate zero-shot sim-to-real traversal of 0.8 meter platforms (approximately 114% of leg length), with robust adaptation to platform height and initial pose, as well as smooth and stable multi-skill transitions.
LightTact: A Visual-Tactile Fingertip Sensor for Deformation-Independent Contact Sensing
Dec 23, 2025Contact often occurs without macroscopic surface deformation, such as during interaction with liquids, semi-liquids, or ultra-soft materials. Most existing tactile sensors rely on deformation to infer contact, making such light-contact interactions difficult to perceive robustly. To address this, we present LightTact, a visual-tactile fingertip sensor that makes contact directly visible via a deformation-independent, optics-based principle. LightTact uses an ambient-blocking optical configuration that suppresses both external light and internal illumination at non-contact regions, while transmitting only the diffuse light generated at true contacts. As a result, LightTact produces high-contrast raw images in which non-contact pixels remain near-black (mean gray value < 3) and contact pixels preserve the natural appearance of the contacting surface. Built on this, LightTact achieves accurate pixel-level contact segmentation that is robust to material properties, contact force, surface appearance, and environmental lighting. We further integrate LightTact on a robotic arm and demonstrate manipulation behaviors driven by extremely light contact, including water spreading, facial-cream dipping, and thin-film interaction. Finally, we show that LightTact's spatially aligned visual-tactile images can be directly interpreted by existing vision-language models, enabling resistor value reasoning for robotic sorting.
Comparative Field Deployment of Reinforcement Learning and Model Predictive Control for Residential HVAC
Oct 01, 2025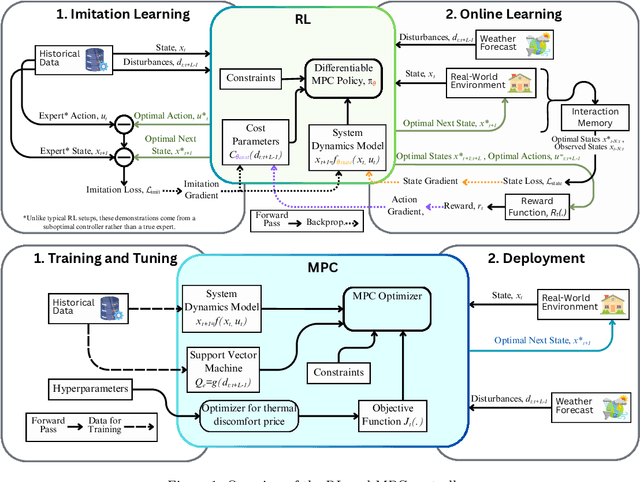



Advanced control strategies like Model Predictive Control (MPC) offer significant energy savings for HVAC systems but often require substantial engineering effort, limiting scalability. Reinforcement Learning (RL) promises greater automation and adaptability, yet its practical application in real-world residential settings remains largely undemonstrated, facing challenges related to safety, interpretability, and sample efficiency. To investigate these practical issues, we performed a direct comparison of an MPC and a model-based RL controller, with each controller deployed for a one-month period in an occupied house with a heat pump system in West Lafayette, Indiana. This investigation aimed to explore scalability of the chosen RL and MPC implementations while ensuring safety and comparability. The advanced controllers were evaluated against each other and against the existing controller. RL achieved substantial energy savings (22\% relative to the existing controller), slightly exceeding MPC's savings (20\%), albeit with modestly higher occupant discomfort. However, when energy savings were normalized for the level of comfort provided, MPC demonstrated superior performance. This study's empirical results show that while RL reduces engineering overhead, it introduces practical trade-offs in model accuracy and operational robustness. The key lessons learned concern the difficulties of safe controller initialization, navigating the mismatch between control actions and their practical implementation, and maintaining the integrity of online learning in a live environment. These insights pinpoint the essential research directions needed to advance RL from a promising concept to a truly scalable HVAC control solution.
GraphEQA: Using 3D Semantic Scene Graphs for Real-time Embodied Question Answering
Dec 19, 2024



In Embodied Question Answering (EQA), agents must explore and develop a semantic understanding of an unseen environment in order to answer a situated question with confidence. This remains a challenging problem in robotics, due to the difficulties in obtaining useful semantic representations, updating these representations online, and leveraging prior world knowledge for efficient exploration and planning. Aiming to address these limitations, we propose GraphEQA, a novel approach that utilizes real-time 3D metric-semantic scene graphs (3DSGs) and task relevant images as multi-modal memory for grounding Vision-Language Models (VLMs) to perform EQA tasks in unseen environments. We employ a hierarchical planning approach that exploits the hierarchical nature of 3DSGs for structured planning and semantic-guided exploration. Through experiments in simulation on the HM-EQA dataset and in the real world in home and office environments, we demonstrate that our method outperforms key baselines by completing EQA tasks with higher success rates and fewer planning steps.
STRAP: Robot Sub-Trajectory Retrieval for Augmented Policy Learning
Dec 19, 2024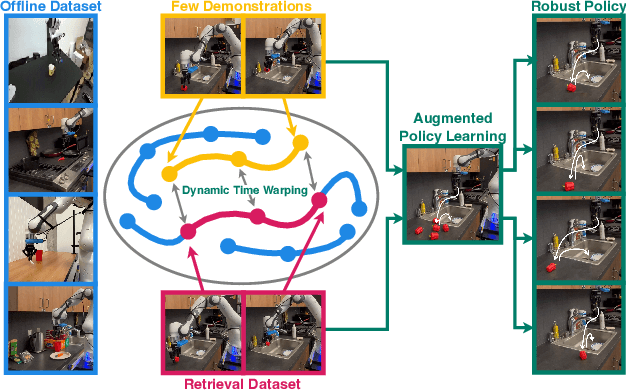
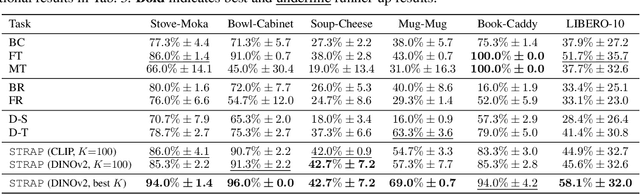
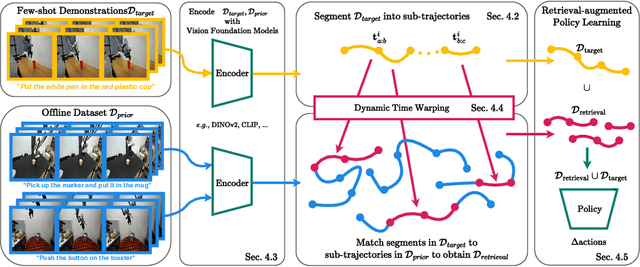
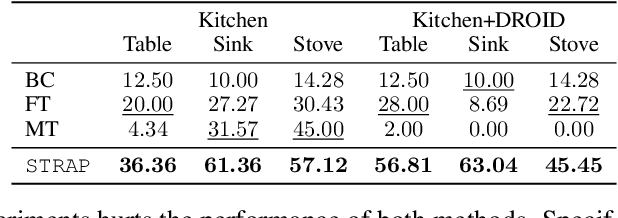
Robot learning is witnessing a significant increase in the size, diversity, and complexity of pre-collected datasets, mirroring trends in domains such as natural language processing and computer vision. Many robot learning methods treat such datasets as multi-task expert data and learn a multi-task, generalist policy by training broadly across them. Notably, while these generalist policies can improve the average performance across many tasks, the performance of generalist policies on any one task is often suboptimal due to negative transfer between partitions of the data, compared to task-specific specialist policies. In this work, we argue for the paradigm of training policies during deployment given the scenarios they encounter: rather than deploying pre-trained policies to unseen problems in a zero-shot manner, we non-parametrically retrieve and train models directly on relevant data at test time. Furthermore, we show that many robotics tasks share considerable amounts of low-level behaviors and that retrieval at the "sub"-trajectory granularity enables significantly improved data utilization, generalization, and robustness in adapting policies to novel problems. In contrast, existing full-trajectory retrieval methods tend to underutilize the data and miss out on shared cross-task content. This work proposes STRAP, a technique for leveraging pre-trained vision foundation models and dynamic time warping to retrieve sub-sequences of trajectories from large training corpora in a robust fashion. STRAP outperforms both prior retrieval algorithms and multi-task learning methods in simulated and real experiments, showing the ability to scale to much larger offline datasets in the real world as well as the ability to learn robust control policies with just a handful of real-world demonstrations.
From Variance to Veracity: Unbundling and Mitigating Gradient Variance in Differentiable Bundle Adjustment Layers
Jun 12, 2024



Various pose estimation and tracking problems in robotics can be decomposed into a correspondence estimation problem (often computed using a deep network) followed by a weighted least squares optimization problem to solve for the poses. Recent work has shown that coupling the two problems by iteratively refining one conditioned on the other's output yields SOTA results across domains. However, training these models has proved challenging, requiring a litany of tricks to stabilize and speed up training. In this work, we take the visual odometry problem as an example and identify three plausible causes: (1) flow loss interference, (2) linearization errors in the bundle adjustment (BA) layer, and (3) dependence of weight gradients on the BA residual. We show how these issues result in noisy and higher variance gradients, potentially leading to a slow down in training and instabilities. We then propose a simple, yet effective solution to reduce the gradient variance by using the weights predicted by the network in the inner optimization loop to weight the correspondence objective in the training problem. This helps the training objective `focus' on the more important points, thereby reducing the variance and mitigating the influence of outliers. We show that the resulting method leads to faster training and can be more flexibly trained in varying training setups without sacrificing performance. In particular we show $2$--$2.5\times$ training speedups over a baseline visual odometry model we modify.
CaDRE: Controllable and Diverse Generation of Safety-Critical Driving Scenarios using Real-World Trajectories
Mar 19, 2024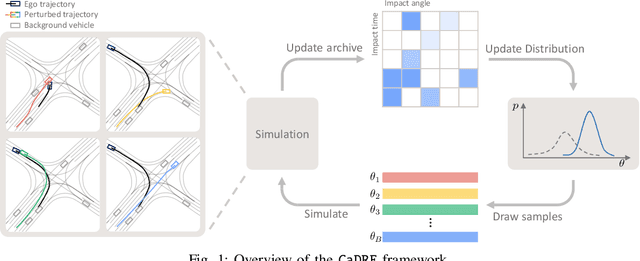
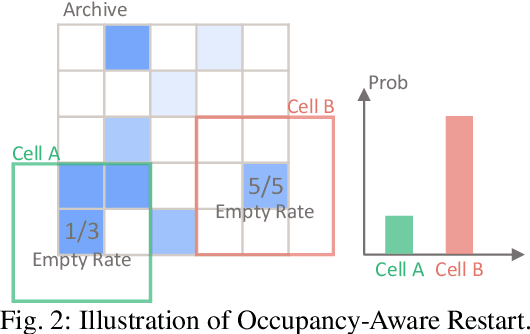
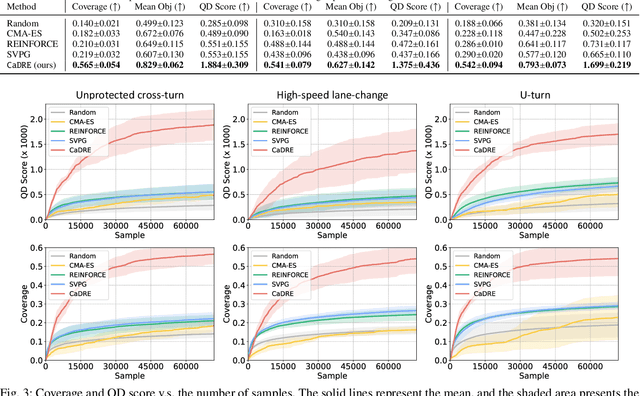
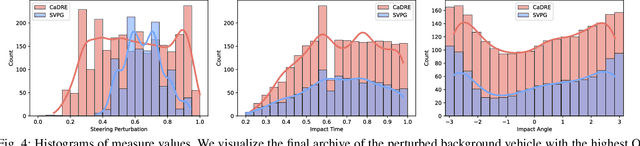
Simulation is an indispensable tool in the development and testing of autonomous vehicles (AVs), offering an efficient and safe alternative to road testing by allowing the exploration of a wide range of scenarios. Despite its advantages, a significant challenge within simulation-based testing is the generation of safety-critical scenarios, which are essential to ensure that AVs can handle rare but potentially fatal situations. This paper addresses this challenge by introducing a novel generative framework, CaDRE, which is specifically designed for generating diverse and controllable safety-critical scenarios using real-world trajectories. Our approach optimizes for both the quality and diversity of scenarios by employing a unique formulation and algorithm that integrates real-world data, domain knowledge, and black-box optimization techniques. We validate the effectiveness of our framework through extensive testing in three representative types of traffic scenarios. The results demonstrate superior performance in generating diverse and high-quality scenarios with greater sample efficiency than existing reinforcement learning and sampling-based methods.
What Went Wrong? Closing the Sim-to-Real Gap via Differentiable Causal Discovery
Jun 28, 2023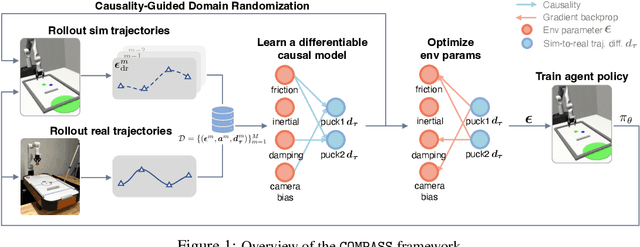

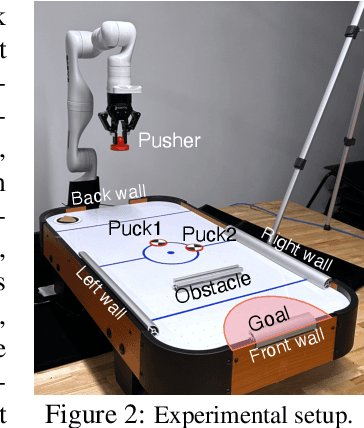

Training control policies in simulation is more appealing than on real robots directly, as it allows for exploring diverse states in a safe and efficient manner. Yet, robot simulators inevitably exhibit disparities from the real world, yielding inaccuracies that manifest as the simulation-to-real gap. Existing literature has proposed to close this gap by actively modifying specific simulator parameters to align the simulated data with real-world observations. However, the set of tunable parameters is usually manually selected to reduce the search space in a case-by-case manner, which is hard to scale up for complex systems and requires extensive domain knowledge. To address the scalability issue and automate the parameter-tuning process, we introduce an approach that aligns the simulator with the real world by discovering the causal relationship between the environment parameters and the sim-to-real gap. Concretely, our method learns a differentiable mapping from the environment parameters to the differences between simulated and real-world robot-object trajectories. This mapping is governed by a simultaneously-learned causal graph to help prune the search space of parameters, provide better interpretability, and improve generalization. We perform experiments to achieve both sim-to-sim and sim-to-real transfer, and show that our method has significant improvements in trajectory alignment and task success rate over strong baselines in a challenging manipulation task.
Distribution-aware Goal Prediction and Conformant Model-based Planning for Safe Autonomous Driving
Dec 16, 2022The feasibility of collecting a large amount of expert demonstrations has inspired growing research interests in learning-to-drive settings, where models learn by imitating the driving behaviour from experts. However, exclusively relying on imitation can limit agents' generalisability to novel scenarios that are outside the support of the training data. In this paper, we address this challenge by factorising the driving task, based on the intuition that modular architectures are more generalisable and more robust to changes in the environment compared to monolithic, end-to-end frameworks. Specifically, we draw inspiration from the trajectory forecasting community and reformulate the learning-to-drive task as obstacle-aware perception and grounding, distribution-aware goal prediction, and model-based planning. Firstly, we train the obstacle-aware perception module to extract salient representation of the visual context. Then, we learn a multi-modal goal distribution by performing conditional density-estimation using normalising flow. Finally, we ground candidate trajectory predictions road geometry, and plan the actions based on on vehicle dynamics. Under the CARLA simulator, we report state-of-the-art results on the CARNOVEL benchmark.