 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalization of Continuous Relaxation in Structured Pruning
Aug 28, 2023



Deep learning harnesses massive parallel floating-point processing to train and evaluate large neural networks. Trends indicate that deeper and larger neural networks with an increasing number of parameters achieve higher accuracy than smaller neural networks. This performance improvement, which often requires heavy compute for both training and evaluation, eventually needs to translate well to resource-constrained hardware for practical value. Structured pruning asserts that while large networks enable us to find solutions to complex computer vision problems, a smaller, computationally efficient sub-network can be derived from the large neural network that retains model accuracy but significantly improves computational efficiency. We generalize structured pruning with algorithms for network augmentation, pruning, sub-network collapse and removal. In addition, we demonstrate efficient and stable convergence up to 93% sparsity and 95% FLOPs reduction without loss of inference accuracy using with continuous relaxation matching or exceeding the state of the art for all structured pruning methods. The resulting CNN executes efficiently on GPU hardware without computationally expensive sparse matrix operations. We achieve this with routine automatable operations on classification and segmentation problems using CIFAR-10, ImageNet, and CityScapes datasets with the ResNet and U-NET network architectures.
AI-Enhanced Data Processing and Discovery Crowd Sourcing for Meteor Shower Mapping
Aug 02, 2023The Cameras for Allsky Meteor Surveillance (CAMS) project, funded by NASA starting in 2010, aims to map our meteor showers by triangulating meteor trajectories detected in low-light video cameras from multiple locations across 16 countries in both the northern and southern hemispheres. Its mission is to validate, discover, and predict the upcoming returns of meteor showers. Our research aimed to streamline the data processing by implementing an automated cloud-based AI-enabled pipeline and improve the data visualization to improve the rate of discoveries by involving the public in monitoring the meteor detections. This article describes the process of automating the data ingestion, processing, and insight generation using an interpretable Active Learning and AI pipeline. This work also describes the development of an interactive web portal (the NASA Meteor Shower portal) to facilitate the visualization of meteor radiant maps. To date, CAMS has discovered over 200 new meteor showers and has validated dozens of previously reported showers.
Curator: Creating Large-Scale Curated Labelled Datasets using Self-Supervised Learning
Dec 28, 2022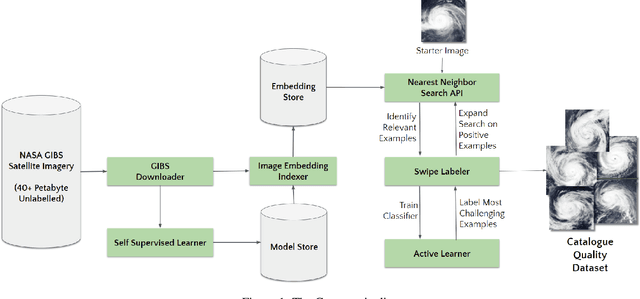
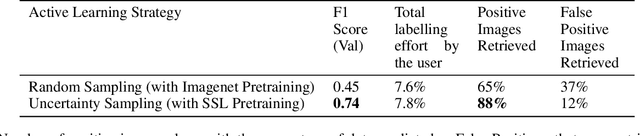


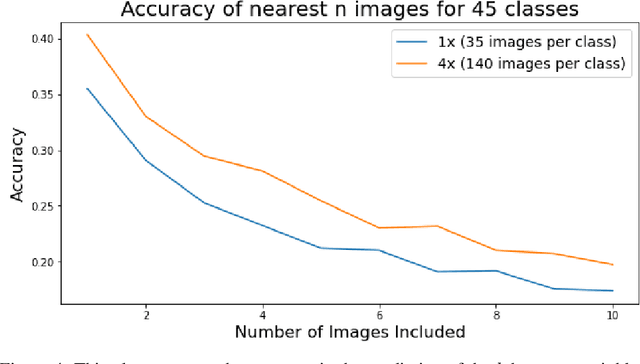
Applying Machine learning to domains like Earth Sciences is impeded by the lack of labeled data, despite a large corpus of raw data available in such domains. For instance, training a wildfire classifier on satellite imagery requires curating a massive and diverse dataset, which is an expensive and time-consuming process that can span from weeks to months. Searching for relevant examples in over 40 petabytes of unlabelled data requires researchers to manually hunt for such images, much like finding a needle in a haystack. We present a no-code end-to-end pipeline, Curator, which dramatically minimizes the time taken to curate an exhaustive labeled dataset. Curator is able to search massive amounts of unlabelled data by combining self-supervision, scalable nearest neighbor search, and active learning to learn and differentiate image representations. The pipeline can also be readily applied to solve problems across different domains. Overall, the pipeline makes it practical for researchers to go from just one reference image to a comprehensive dataset in a diminutive span of time.
Deep learning based landslide density estimation on SAR data for rapid response
Nov 18, 2022



This work aims to produce landslide density estimates using Synthetic Aperture Radar (SAR) satellite imageries to prioritise emergency resources for rapid response. We use the United States Geological Survey (USGS) Landslide Inventory data annotated by experts after Hurricane Mar\'ia in Puerto Rico on Sept 20, 2017, and their subsequent susceptibility study which uses extensive additional information such as precipitation, soil moisture, geological terrain features, closeness to waterways and roads, etc. Since such data might not be available during other events or regions, we aimed to produce a landslide density map using only elevation and SAR data to be useful to decision-makers in rapid response scenarios. The USGS Landslide Inventory contains the coordinates of 71,431 landslide heads (not their full extent) and was obtained by manual inspection of aerial and satellite imagery. It is estimated that around 45\% of the landslides are smaller than a Sentinel-1 typical pixel which is 10m $\times$ 10m, although many are long and thin, probably leaving traces across several pixels. Our method obtains 0.814 AUC in predicting the correct density estimation class at the chip level (128$\times$128 pixels, at Sentinel-1 resolution) using only elevation data and up to three SAR acquisitions pre- and post-hurricane, thus enabling rapid assessment after a disaster. The USGS Susceptibility Study reports a 0.87 AUC, but it is measured at the landslide level and uses additional information sources (such as proximity to fluvial channels, roads, precipitation, etc.) which might not regularly be available in an rapid response emergency scenario.
SAR-based landslide classification pretraining leads to better segmentation
Nov 17, 2022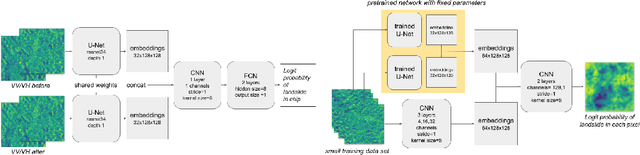
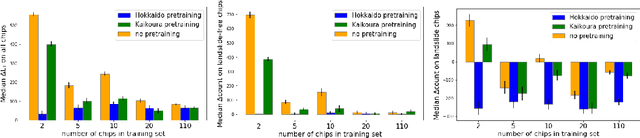
Rapid assessment after a natural disaster is key for prioritizing emergency resources. In the case of landslides, rapid assessment involves determining the extent of the area affected and measuring the size and location of individual landslides. Synthetic Aperture Radar (SAR) is an active remote sensing technique that is unaffected by weather conditions. Deep Learning algorithms can be applied to SAR data, but training them requires large labeled datasets. In the case of landslides, these datasets are laborious to produce for segmentation, and often they are not available for the specific region in which the event occurred. Here, we study how deep learning algorithms for landslide segmentation on SAR products can benefit from pretraining on a simpler task and from data from different regions. The method we explore consists of two training stages. First, we learn the task of identifying whether a SAR image contains any landslides or not. Then, we learn to segment in a sparsely labeled scenario where half of the data do not contain landslides. We test whether the inclusion of feature embeddings derived from stage-1 helps with landslide detection in stage-2. We find that it leads to minor improvements in the Area Under the Precision-Recall Curve, but also to a significantly lower false positive rate in areas without landslides and an improved estimate of the average number of landslide pixels in a chip. A more accurate pixel count allows to identify the most affected areas with higher confidence. This could be valuable in rapid response scenarios where prioritization of resources at a global scale is important. We make our code publicly available at https://github.com/VMBoehm/SAR-landslide-detection-pretraining.
Deep Learning for Rapid Landslide Detection using Synthetic Aperture Radar (SAR) Datacubes
Nov 05, 2022

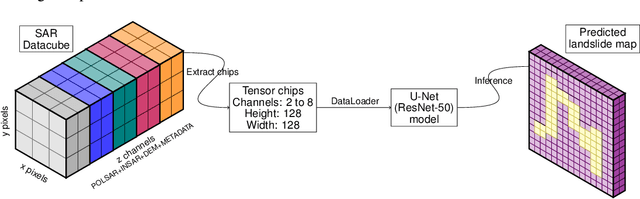
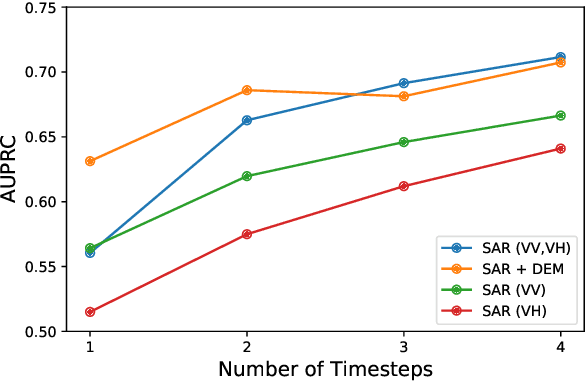
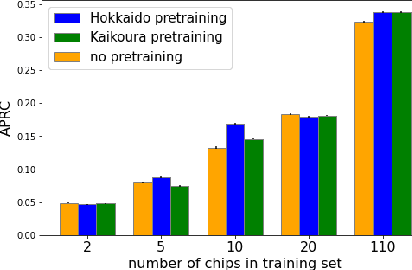
With climate change predicted to increase the likelihood of landslide events, there is a growing need for rapid landslide detection technologies that help inform emergency responses. Synthetic Aperture Radar (SAR) is a remote sensing technique that can provide measurements of affected areas independent of weather or lighting conditions. Usage of SAR, however, is hindered by domain knowledge that is necessary for the pre-processing steps and its interpretation requires expert knowledge. We provide simplified, pre-processed, machine-learning ready SAR datacubes for four globally located landslide events obtained from several Sentinel-1 satellite passes before and after a landslide triggering event together with segmentation maps of the landslides. From this dataset, using the Hokkaido, Japan datacube, we study the feasibility of SAR-based landslide detection with supervised deep learning (DL). Our results demonstrate that DL models can be used to detect landslides from SAR data, achieving an Area under the Precision-Recall curve exceeding 0.7. We find that additional satellite visits enhance detection performance, but that early detection is possible when SAR data is combined with terrain information from a digital elevation model. This can be especially useful for time-critical emergency interventions. Code is made publicly available at https://github.com/iprapas/landslide-sar-unet.
Learn-to-Race Challenge 2022: Benchmarking Safe Learning and Cross-domain Generalisation in Autonomous Racing
May 10, 2022
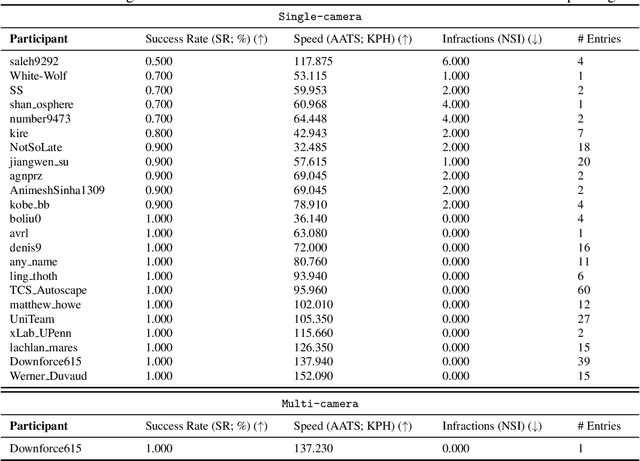

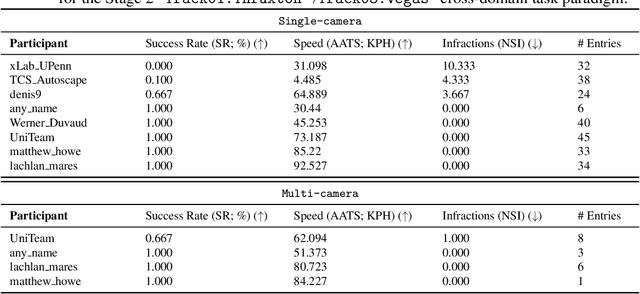
We present the results of our autonomous racing virtual challenge, based on the newly-released Learn-to-Race (L2R) simulation framework, which seeks to encourage interdisciplinary research in autonomous driving and to help advance the state of the art on a realistic benchmark. Analogous to racing being used to test cutting-edge vehicles, we envision autonomous racing to serve as a particularly challenging proving ground for autonomous agents as: (i) they need to make sub-second, safety-critical decisions in a complex, fast-changing environment; and (ii) both perception and control must be robust to distribution shifts, novel road features, and unseen obstacles. Thus, the main goal of the challenge is to evaluate the joint safety, performance, and generalisation capabilities of reinforcement learning agents on multi-modal perception, through a two-stage process. In the first stage of the challenge, we evaluate an autonomous agent's ability to drive as fast as possible, while adhering to safety constraints. In the second stage, we additionally require the agent to adapt to an unseen racetrack through safe exploration. In this paper, we describe the new L2R Task 2.0 benchmark, with refined metrics and baseline approaches. We also provide an overview of deployment, evaluation, and rankings for the inaugural instance of the L2R Autonomous Racing Virtual Challenge (supported by Carnegie Mellon University, Arrival Ltd., AICrowd, Amazon Web Services, and Honda Research), which officially used the new L2R Task 2.0 benchmark and received over 20,100 views, 437 active participants, 46 teams, and 733 model submissions -- from 88+ unique institutions, in 58+ different countries. Finally, we release leaderboard results from the challenge and provide description of the two top-ranking approaches in cross-domain model transfer, across multiple sensor configurations and simulated races.
CELESTIAL: Classification Enabled via Labelless Embeddings with Self-supervised Telescope Image Analysis Learning
Jan 20, 2022
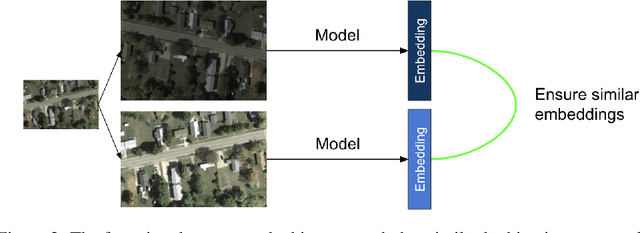

A common class of problems in remote sensing is scene classification, a fundamentally important task for natural hazards identification, geographic image retrieval, and environment monitoring. Recent developments in this field rely label-dependent supervised learning techniques which is antithetical to the 35 petabytes of unlabelled satellite imagery in NASA GIBS. To solve this problem, we establish CELESTIAL-a self-supervised learning pipeline for effectively leveraging sparsely-labeled satellite imagery. This pipeline successfully adapts SimCLR, an algorithm that first learns image representations on unlabelled data and then fine-tunes this knowledge on the provided labels. Our results show CELESTIAL requires only a third of the labels that the supervised method needs to attain the same accuracy on an experimental dataset. The first unsupervised tier can enable applications such as reverse image search for NASA Worldview (i.e. searching similar atmospheric phenomenon over years of unlabelled data with minimal samples) and the second supervised tier can lower the necessity of expensive data annotation significantly. In the future, we hope we can generalize the CELESTIAL pipeline to other data types, algorithms, and applications.
Flood Segmentation on Sentinel-1 SAR Imagery with Semi-Supervised Learning
Aug 19, 2021

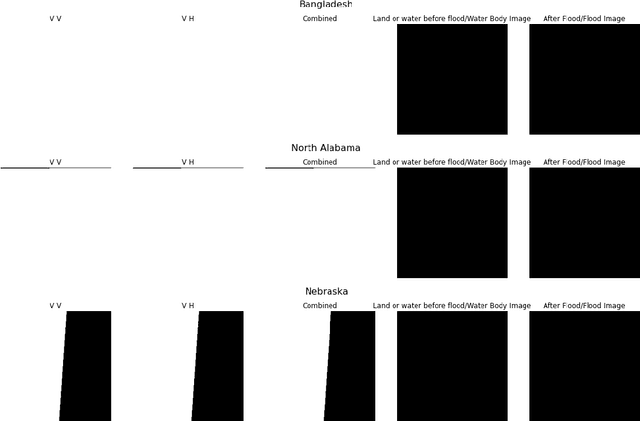

Floods wreak havoc throughout the world, causing billions of dollars in damages, and uprooting communities, ecosystems and economies. Accurate and robust flood detection including delineating open water flood areas and identifying flood levels can aid in disaster response and mitigation. However, estimating flood levels remotely is of essence as physical access to flooded areas is limited and the ability to deploy instruments in potential flood zones can be dangerous. Aligning flood extent mapping with local topography can provide a plan-of-action that the disaster response team can consider. Thus, remote flood level estimation via satellites like Sentinel-1 can prove to be remedial. The Emerging Techniques in Computational Intelligence (ETCI) competition on Flood Detection tasked participants with predicting flooded pixels after training with synthetic aperture radar (SAR) images in a supervised setting. We use a cyclical approach involving two stages (1) training an ensemble model of multiple UNet architectures with available high and low confidence labeled data and, generating pseudo labels or low confidence labels on the entire unlabeled test dataset, and then, (2) filter out quality generated labels and, (3) combining the generated labels with the previously available high confidence labeled dataset. This assimilated dataset is used for the next round of training ensemble models. This cyclical process is repeated until the performance improvement plateaus. Additionally, we post process our results with Conditional Random Fields. Our approach sets the second highest score on the public hold-out test leaderboard for the ETCI competition with 0.7654 IoU. To the best of our knowledge we believe this is one of the first works to try out semi-supervised learning to improve flood segmentation models.
Scalable Reverse Image Search Engine for NASAWorldview
Aug 10, 2021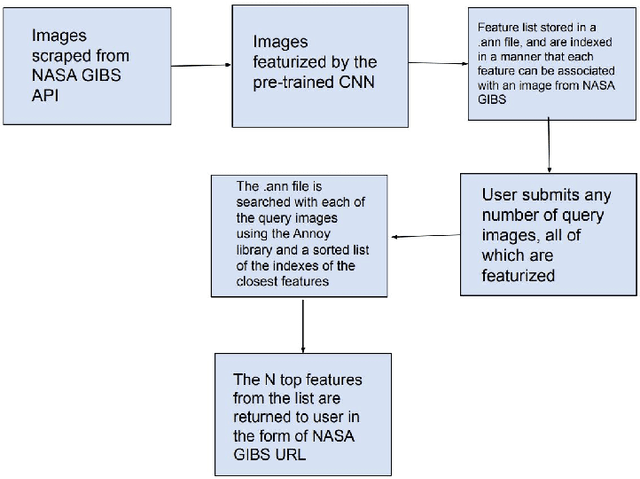
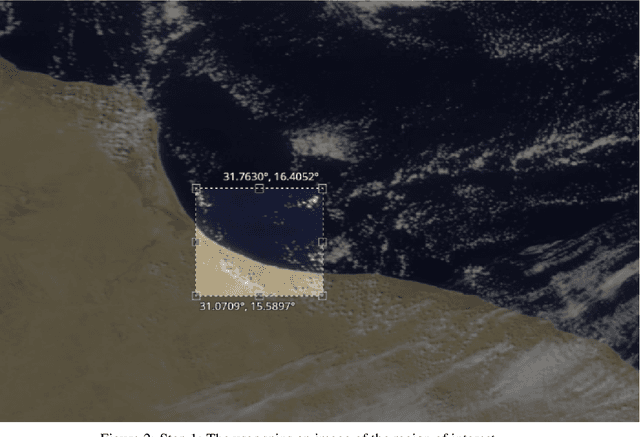


Researchers often spend weeks sifting through decades of unlabeled satellite imagery(on NASA Worldview) in order to develop datasets on which they can start conducting research. We developed an interactive, scalable and fast image similarity search engine (which can take one or more images as the query image) that automatically sifts through the unlabeled dataset reducing dataset generation time from weeks to minutes. In this work, we describe key components of the end to end pipeline. Our similarity search system was created to be able to identify similar images from a potentially petabyte scale database that are similar to an input image, and for this we had to break down each query image into its features, which were generated by a classification layer stripped CNN trained in a supervised manner. To store and search these features efficiently, we had to make several scalability improvements. To improve the speed, reduce the storage, and shrink memory requirements for embedding search, we add a fully connected layer to our CNN make all images into a 128 length vector before entering the classification layers. This helped us compress the size of our image features from 2048 (for ResNet, which was initially tried as our featurizer) to 128 for our new custom model. Additionally, we utilize existing approximate nearest neighbor search libraries to significantly speed up embedding search. Our system currently searches over our entire database of images at 5 seconds per query on a single virtual machine in the cloud. In the future, we would like to incorporate a SimCLR based featurizing model which could be trained without any labelling by a human (since the classification aspect of the model is irrelevant to this use case).