 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimateNLP: Analyzing Public Sentiment Towards Climate Change Using Natural Language Processing
Oct 19, 2023



Climate change's impact on human health poses unprecedented and diverse challenges. Unless proactive measures based on solid evidence are implemented, these threats will likely escalate and continue to endanger human well-being. The escalating advancements in information and communication technologies have facilitated the widespread availability and utilization of social media platforms. Individuals utilize platforms such as Twitter and Facebook to express their opinions, thoughts, and critiques on diverse subjects, encompassing the pressing issue of climate change. The proliferation of climate change-related content on social media necessitates comprehensive analysis to glean meaningful insights. This paper employs natural language processing (NLP) techniques to analyze climate change discourse and quantify the sentiment of climate change-related tweets. We use ClimateBERT, a pretrained model fine-tuned specifically for the climate change domain. The objective is to discern the sentiment individuals express and uncover patterns in public opinion concerning climate change. Analyzing tweet sentiments allows a deeper comprehension of public perceptions, concerns, and emotions about this critical global challenge. The findings from this experiment unearth valuable insights into public sentiment and the entities associated with climate change discourse. Policymakers, researchers, and organizations can leverage such analyses to understand public perceptions, identify influential actors, and devise informed strategies to address climate change challenges.
Curator: Creating Large-Scale Curated Labelled Datasets using Self-Supervised Learning
Dec 28, 2022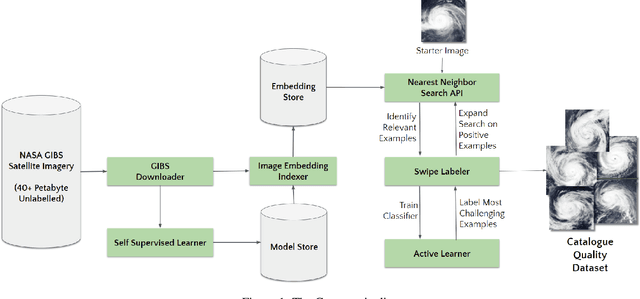
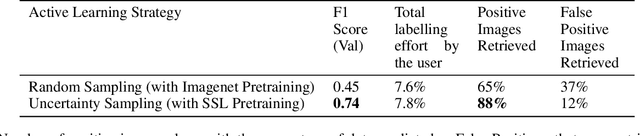


Applying Machine learning to domains like Earth Sciences is impeded by the lack of labeled data, despite a large corpus of raw data available in such domains. For instance, training a wildfire classifier on satellite imagery requires curating a massive and diverse dataset, which is an expensive and time-consuming process that can span from weeks to months. Searching for relevant examples in over 40 petabytes of unlabelled data requires researchers to manually hunt for such images, much like finding a needle in a haystack. We present a no-code end-to-end pipeline, Curator, which dramatically minimizes the time taken to curate an exhaustive labeled dataset. Curator is able to search massive amounts of unlabelled data by combining self-supervision, scalable nearest neighbor search, and active learning to learn and differentiate image representations. The pipeline can also be readily applied to solve problems across different domains. Overall, the pipeline makes it practical for researchers to go from just one reference image to a comprehensive dataset in a diminutive span of time.
Using reinforcement learning to design an AI assistantfor a satisfying co-op experience
May 07, 2021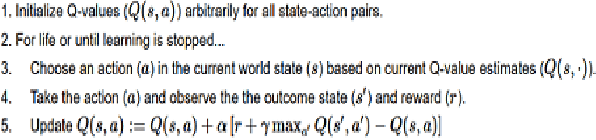
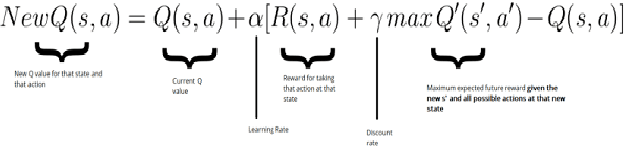

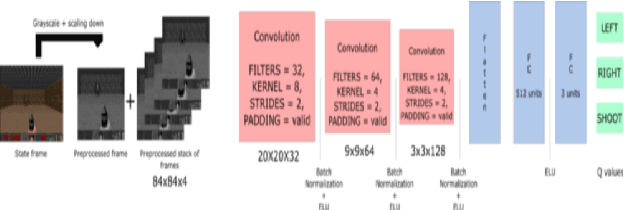
In this project, we designed an intelligent assistant player for the single-player game Space Invaders with the aim to provide a satisfying co-op experience. The agent behaviour was designed using reinforcement learning techniques and evaluated based on several criteria. We validate the hypothesis that an AI-driven computer player can provide a satisfying co-op experience.