 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalFake: A Multimodal Fake News Identification for Malayalam using Recurrent Neural Networks and VGG-16
Oct 27, 2023The amount of news being consumed online has substantially expanded in recent years. Fake news has become increasingly common, especially in regional languages like Malayalam, due to the rapid publication and lack of editorial standards on some online sites. Fake news may have a terrible effect on society, causing people to make bad judgments, lose faith in authorities, and even engage in violent behavior. When we take into the context of India, there are many regional languages, and fake news is spreading in every language. Therefore, providing efficient techniques for identifying false information in regional tongues is crucial. Until now, little to no work has been done in Malayalam, extracting features from multiple modalities to classify fake news. Multimodal approaches are more accurate in detecting fake news, as features from multiple modalities are extracted to build the deep learning classification model. As far as we know, this is the first piece of work in Malayalam that uses multimodal deep learning to tackle false information. Models trained with more than one modality typically outperform models taught with only one modality. Our study in the Malayalam language utilizing multimodal deep learning is a significant step toward more effective misinformation detection and mitigation.
EmoDiarize: Speaker Diarization and Emotion Identification from Speech Signals using Convolutional Neural Networks
Oct 19, 2023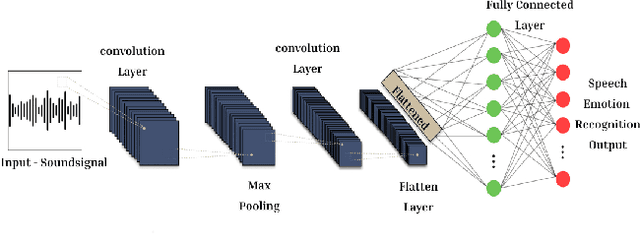
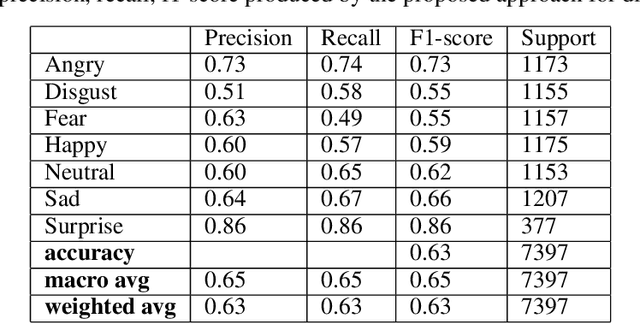
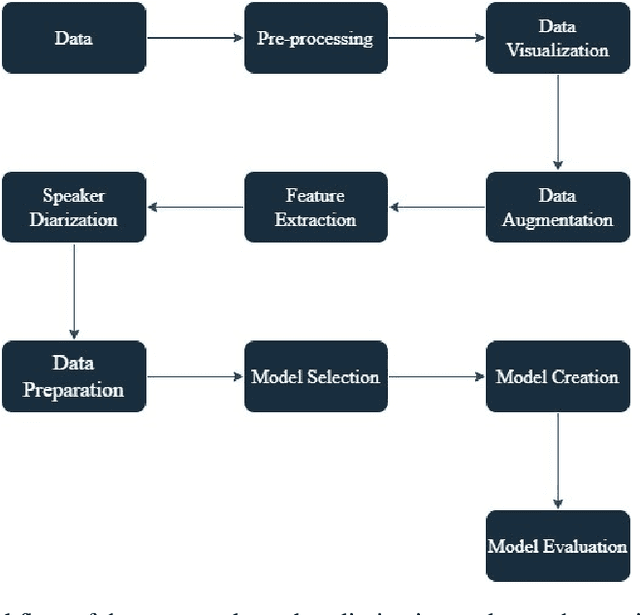
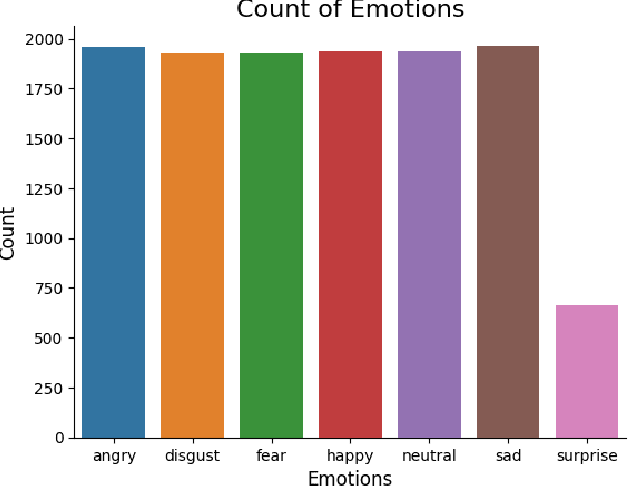
In the era of advanced artificial intelligence and human-computer interaction, identifying emotions in spoken language is paramount. This research explores the integration of deep learning techniques in speech emotion recognition, offering a comprehensive solution to the challenges associated with speaker diarization and emotion identification. It introduces a framework that combines a pre-existing speaker diarization pipeline and an emotion identification model built on a Convolutional Neural Network (CNN) to achieve higher precision. The proposed model was trained on data from five speech emotion datasets, namely, RAVDESS, CREMA-D, SAVEE, TESS, and Movie Clips, out of which the latter is a speech emotion dataset created specifically for this research. The features extracted from each sample include Mel Frequency Cepstral Coefficients (MFCC), Zero Crossing Rate (ZCR), Root Mean Square (RMS), and various data augmentation algorithms like pitch, noise, stretch, and shift. This feature extraction approach aims to enhance prediction accuracy while reducing computational complexity. The proposed model yields an unweighted accuracy of 63%, demonstrating remarkable efficiency in accurately identifying emotional states within speech signals.
ClimateNLP: Analyzing Public Sentiment Towards Climate Change Using Natural Language Processing
Oct 19, 2023



Climate change's impact on human health poses unprecedented and diverse challenges. Unless proactive measures based on solid evidence are implemented, these threats will likely escalate and continue to endanger human well-being. The escalating advancements in information and communication technologies have facilitated the widespread availability and utilization of social media platforms. Individuals utilize platforms such as Twitter and Facebook to express their opinions, thoughts, and critiques on diverse subjects, encompassing the pressing issue of climate change. The proliferation of climate change-related content on social media necessitates comprehensive analysis to glean meaningful insights. This paper employs natural language processing (NLP) techniques to analyze climate change discourse and quantify the sentiment of climate change-related tweets. We use ClimateBERT, a pretrained model fine-tuned specifically for the climate change domain. The objective is to discern the sentiment individuals express and uncover patterns in public opinion concerning climate change. Analyzing tweet sentiments allows a deeper comprehension of public perceptions, concerns, and emotions about this critical global challenge. The findings from this experiment unearth valuable insights into public sentiment and the entities associated with climate change discourse. Policymakers, researchers, and organizations can leverage such analyses to understand public perceptions, identify influential actors, and devise informed strategies to address climate change challenges.
An Analysis on Large Language Models in Healthcare: A Case Study of BioBERT
Oct 12, 2023This paper conducts a comprehensive investigation into applying large language models, particularly on BioBERT, in healthcare. It begins with thoroughly examining previous natural language processing (NLP) approaches in healthcare, shedding light on the limitations and challenges these methods face. Following that, this research explores the path that led to the incorporation of BioBERT into healthcare applications, highlighting its suitability for addressing the specific requirements of tasks related to biomedical text mining. The analysis outlines a systematic methodology for fine-tuning BioBERT to meet the unique needs of the healthcare domain. This approach includes various components, including the gathering of data from a wide range of healthcare sources, data annotation for tasks like identifying medical entities and categorizing them, and the application of specialized preprocessing techniques tailored to handle the complexities found in biomedical texts. Additionally, the paper covers aspects related to model evaluation, with a focus on healthcare benchmarks and functions like processing of natural language in biomedical, question-answering, clinical document classification, and medical entity recognition. It explores techniques to improve the model's interpretability and validates its performance compared to existing healthcare-focused language models. The paper thoroughly examines ethical considerations, particularly patient privacy and data security. It highlights the benefits of incorporating BioBERT into healthcare contexts, including enhanced clinical decision support and more efficient information retrieval. Nevertheless, it acknowledges the impediments and complexities of this integration, encompassing concerns regarding data privacy, transparency, resource-intensive requirements, and the necessity for model customization to align with diverse healthcare domains.
Learning Concept Hierarchies through Probabilistic Topic Modeling
Nov 29, 2016
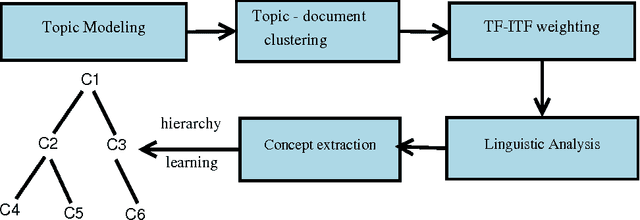
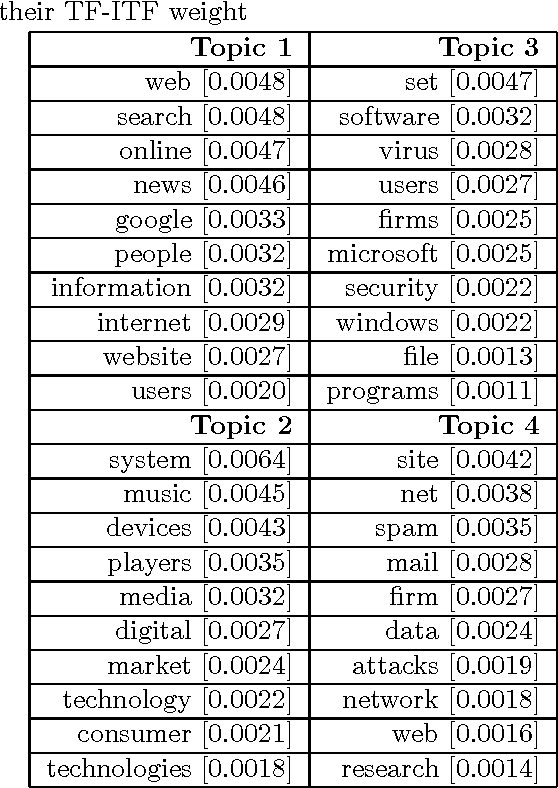

With the advent of semantic web, various tools and techniques have been introduced for presenting and organizing knowledge. Concept hierarchies are one such technique which gained significant attention due to its usefulness in creating domain ontologies that are considered as an integral part of semantic web. Automated concept hierarchy learning algorithms focus on extracting relevant concepts from unstructured text corpus and connect them together by identifying some potential relations exist between them. In this paper, we propose a novel approach for identifying relevant concepts from plain text and then learns hierarchy of concepts by exploiting subsumption relation between them. To start with, we model topics using a probabilistic topic model and then make use of some lightweight linguistic process to extract semantically rich concepts. Then we connect concepts by identifying an "is-a" relationship between pair of concepts. The proposed method is completely unsupervised and there is no need for a domain specific training corpus for concept extraction and learning. Experiments on large and real-world text corpora such as BBC News dataset and Reuters News corpus shows that the proposed method outperforms some of the existing methods for concept extraction and efficient concept hierarchy learning is possible if the overall task is guided by a probabilistic topic modeling algorithm.