 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Guide Dog: Egocentric Path Prediction on Smartphone
Jan 14, 2025



This paper introduces AI Guide Dog (AIGD), a lightweight egocentric navigation assistance system for visually impaired individuals, designed for real-time deployment on smartphones. AIGD addresses key challenges in blind navigation by employing a vision-only, multi-label classification approach to predict directional commands, ensuring safe traversal across diverse environments. We propose a novel technique to enable goal-based outdoor navigation by integrating GPS signals and high-level directions, while also addressing uncertain multi-path predictions for destination-free indoor navigation. Our generalized model is the first navigation assistance system to handle both goal-oriented and exploratory navigation scenarios across indoor and outdoor settings, establishing a new state-of-the-art in blind navigation. We present methods, datasets, evaluations, and deployment insights to encourage further innovations in assistive navigation systems.
Curator: Creating Large-Scale Curated Labelled Datasets using Self-Supervised Learning
Dec 28, 2022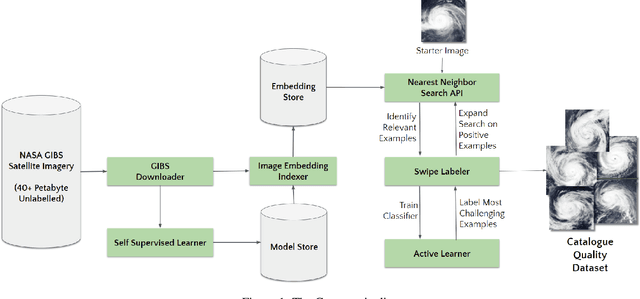
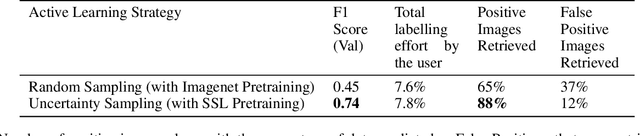


Applying Machine learning to domains like Earth Sciences is impeded by the lack of labeled data, despite a large corpus of raw data available in such domains. For instance, training a wildfire classifier on satellite imagery requires curating a massive and diverse dataset, which is an expensive and time-consuming process that can span from weeks to months. Searching for relevant examples in over 40 petabytes of unlabelled data requires researchers to manually hunt for such images, much like finding a needle in a haystack. We present a no-code end-to-end pipeline, Curator, which dramatically minimizes the time taken to curate an exhaustive labeled dataset. Curator is able to search massive amounts of unlabelled data by combining self-supervision, scalable nearest neighbor search, and active learning to learn and differentiate image representations. The pipeline can also be readily applied to solve problems across different domains. Overall, the pipeline makes it practical for researchers to go from just one reference image to a comprehensive dataset in a diminutive span of time.
Learn-to-Race Challenge 2022: Benchmarking Safe Learning and Cross-domain Generalisation in Autonomous Racing
May 10, 2022
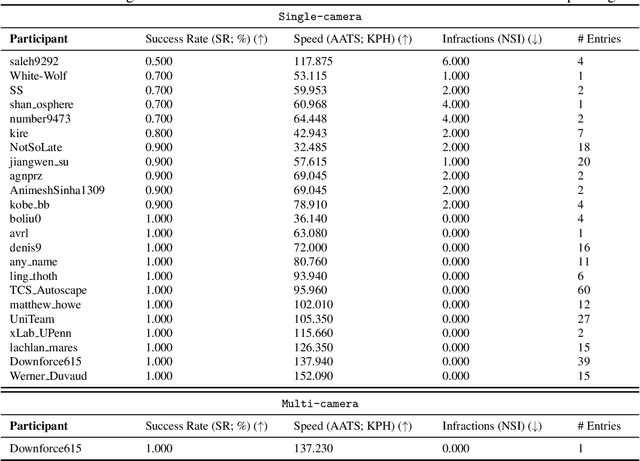

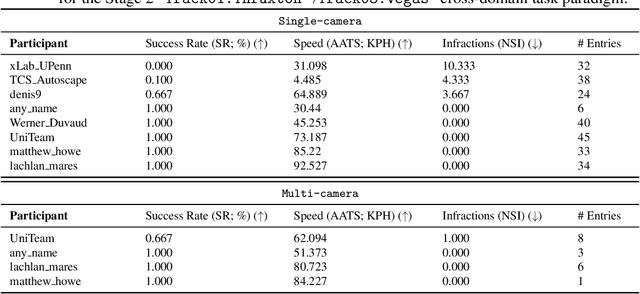
We present the results of our autonomous racing virtual challenge, based on the newly-released Learn-to-Race (L2R) simulation framework, which seeks to encourage interdisciplinary research in autonomous driving and to help advance the state of the art on a realistic benchmark. Analogous to racing being used to test cutting-edge vehicles, we envision autonomous racing to serve as a particularly challenging proving ground for autonomous agents as: (i) they need to make sub-second, safety-critical decisions in a complex, fast-changing environment; and (ii) both perception and control must be robust to distribution shifts, novel road features, and unseen obstacles. Thus, the main goal of the challenge is to evaluate the joint safety, performance, and generalisation capabilities of reinforcement learning agents on multi-modal perception, through a two-stage process. In the first stage of the challenge, we evaluate an autonomous agent's ability to drive as fast as possible, while adhering to safety constraints. In the second stage, we additionally require the agent to adapt to an unseen racetrack through safe exploration. In this paper, we describe the new L2R Task 2.0 benchmark, with refined metrics and baseline approaches. We also provide an overview of deployment, evaluation, and rankings for the inaugural instance of the L2R Autonomous Racing Virtual Challenge (supported by Carnegie Mellon University, Arrival Ltd., AICrowd, Amazon Web Services, and Honda Research), which officially used the new L2R Task 2.0 benchmark and received over 20,100 views, 437 active participants, 46 teams, and 733 model submissions -- from 88+ unique institutions, in 58+ different countries. Finally, we release leaderboard results from the challenge and provide description of the two top-ranking approaches in cross-domain model transfer, across multiple sensor configurations and simulated races.
CELESTIAL: Classification Enabled via Labelless Embeddings with Self-supervised Telescope Image Analysis Learning
Jan 20, 2022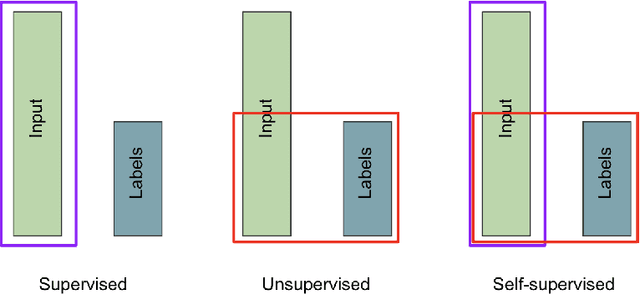
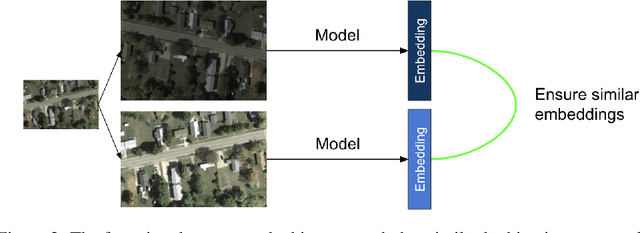

A common class of problems in remote sensing is scene classification, a fundamentally important task for natural hazards identification, geographic image retrieval, and environment monitoring. Recent developments in this field rely label-dependent supervised learning techniques which is antithetical to the 35 petabytes of unlabelled satellite imagery in NASA GIBS. To solve this problem, we establish CELESTIAL-a self-supervised learning pipeline for effectively leveraging sparsely-labeled satellite imagery. This pipeline successfully adapts SimCLR, an algorithm that first learns image representations on unlabelled data and then fine-tunes this knowledge on the provided labels. Our results show CELESTIAL requires only a third of the labels that the supervised method needs to attain the same accuracy on an experimental dataset. The first unsupervised tier can enable applications such as reverse image search for NASA Worldview (i.e. searching similar atmospheric phenomenon over years of unlabelled data with minimal samples) and the second supervised tier can lower the necessity of expensive data annotation significantly. In the future, we hope we can generalize the CELESTIAL pipeline to other data types, algorithms, and applications.
Scalable Reverse Image Search Engine for NASAWorldview
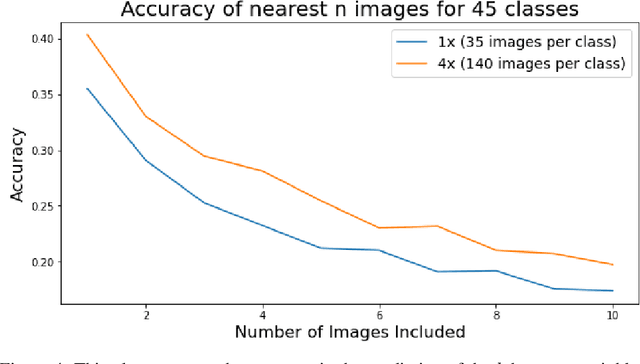
Aug 10, 2021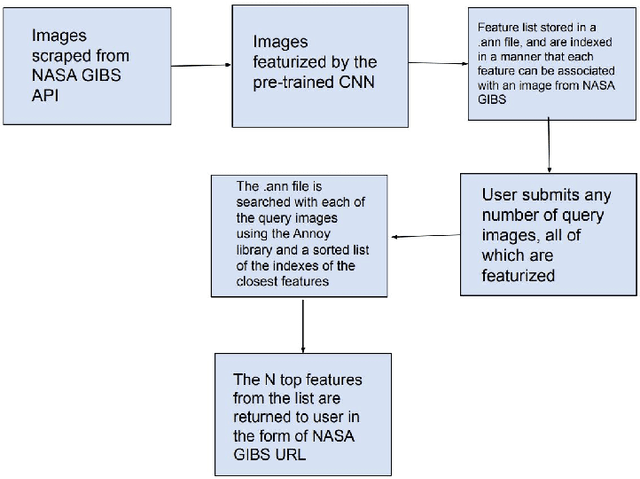
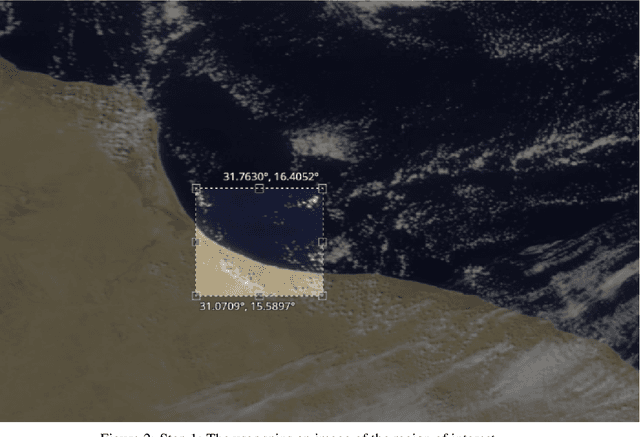


Researchers often spend weeks sifting through decades of unlabeled satellite imagery(on NASA Worldview) in order to develop datasets on which they can start conducting research. We developed an interactive, scalable and fast image similarity search engine (which can take one or more images as the query image) that automatically sifts through the unlabeled dataset reducing dataset generation time from weeks to minutes. In this work, we describe key components of the end to end pipeline. Our similarity search system was created to be able to identify similar images from a potentially petabyte scale database that are similar to an input image, and for this we had to break down each query image into its features, which were generated by a classification layer stripped CNN trained in a supervised manner. To store and search these features efficiently, we had to make several scalability improvements. To improve the speed, reduce the storage, and shrink memory requirements for embedding search, we add a fully connected layer to our CNN make all images into a 128 length vector before entering the classification layers. This helped us compress the size of our image features from 2048 (for ResNet, which was initially tried as our featurizer) to 128 for our new custom model. Additionally, we utilize existing approximate nearest neighbor search libraries to significantly speed up embedding search. Our system currently searches over our entire database of images at 5 seconds per query on a single virtual machine in the cloud. In the future, we would like to incorporate a SimCLR based featurizing model which could be trained without any labelling by a human (since the classification aspect of the model is irrelevant to this use case).
Scalable Data Balancing for Unlabeled Satellite Imagery
Jul 07, 2021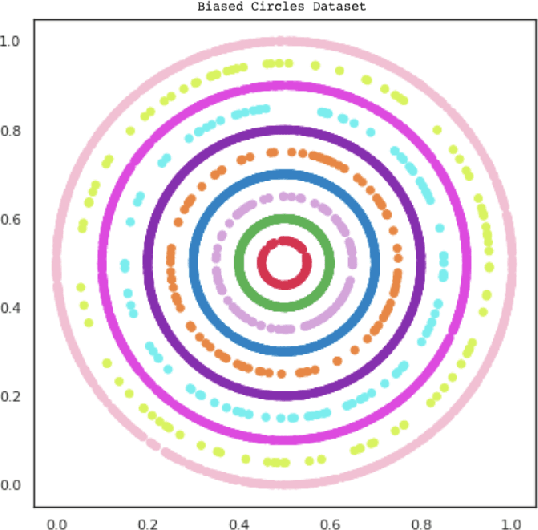
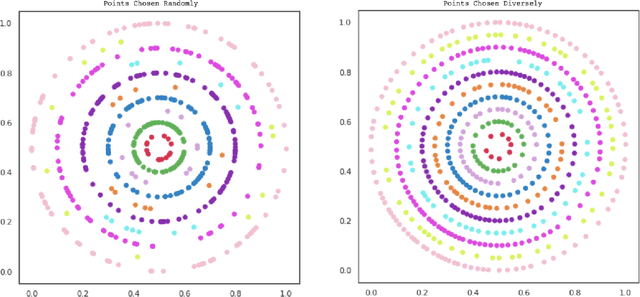
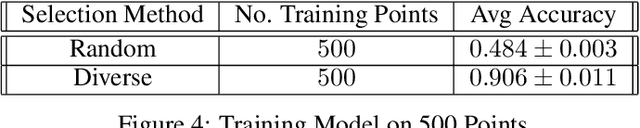
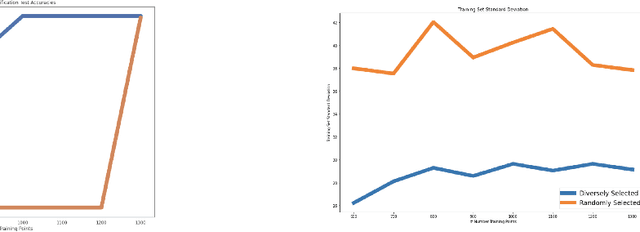
Data imbalance is a ubiquitous problem in machine learning. In large scale collected and annotated datasets, data imbalance is either mitigated manually by undersampling frequent classes and oversampling rare classes, or planned for with imputation and augmentation techniques. In both cases balancing data requires labels. In other words, only annotated data can be balanced. Collecting fully annotated datasets is challenging, especially for large scale satellite systems such as the unlabeled NASA's 35 PB Earth Imagery dataset. Although the NASA Earth Imagery dataset is unlabeled, there are implicit properties of the data source that we can rely on to hypothesize about its imbalance, such as distribution of land and water in the case of the Earth's imagery. We present a new iterative method to balance unlabeled data. Our method utilizes image embeddings as a proxy for image labels that can be used to balance data, and ultimately when trained increases overall accuracy.
Reducing Effects of Swath Gaps on Unsupervised Machine Learning Models for NASA MODIS Instruments
Jun 13, 2021



Due to the nature of their pathways, NASA Terra and NASA Aqua satellites capture imagery containing swath gaps, which are areas of no data. Swath gaps can overlap the region of interest (ROI) completely, often rendering the entire imagery unusable by Machine Learning (ML) models. This problem is further exacerbated when the ROI rarely occurs (e.g. a hurricane) and, on occurrence, is partially overlapped with a swath gap. With annotated data as supervision, a model can learn to differentiate between the area of focus and the swath gap. However, annotation is expensive and currently the vast majority of existing data is unannotated. Hence, we propose an augmentation technique that considerably removes the existence of swath gaps in order to allow CNNs to focus on the ROI, and thus successfully use data with swath gaps for training. We experiment on the UC Merced Land Use Dataset, where we add swath gaps through empty polygons (up to 20 percent areas) and then apply augmentation techniques to fill the swath gaps. We compare the model trained with our augmentation techniques on the swath gap-filled data with the model trained on the original swath gap-less data and note highly augmented performance. Additionally, we perform a qualitative analysis using activation maps that visualizes the effectiveness of our trained network in not paying attention to the swath gaps. We also evaluate our results with a human baseline and show that, in certain cases, the filled swath gaps look so realistic that even a human evaluator did not distinguish between original satellite images and swath gap-filled images. Since this method is aimed at unlabeled data, it is widely generalizable and impactful for large scale unannotated datasets from various space data domains.
Learn-to-Race: A Multimodal Control Environment for Autonomous Racing
Mar 31, 2021
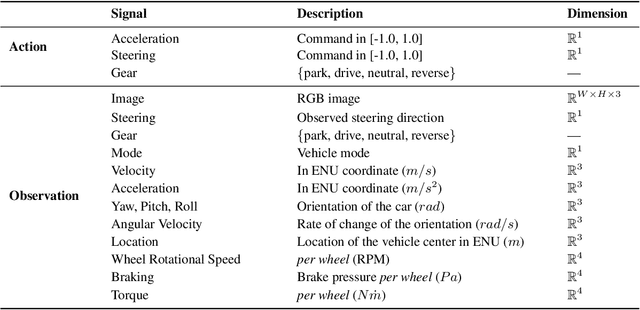
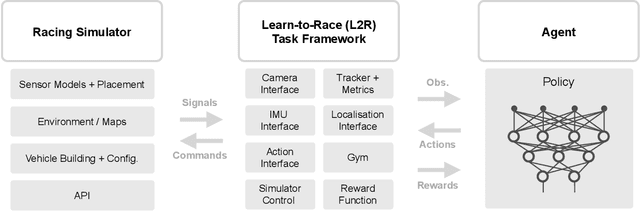

Existing research on autonomous driving primarily focuses on urban driving, which is insufficient for characterising the complex driving behaviour underlying high-speed racing. At the same time, existing racing simulation frameworks struggle in capturing realism, with respect to visual rendering, vehicular dynamics, and task objectives, inhibiting the transfer of learning agents to real-world contexts. We introduce a new environment, where agents Learn-to-Race (L2R) in simulated competition-style racing, using multimodal information--from virtual cameras to a comprehensive array of inertial measurement sensors. Our environment, which includes a simulator and an interfacing training framework, accurately models vehicle dynamics and racing conditions. In this paper, we release the Arrival simulator for autonomous racing. Next, we propose the L2R task with challenging metrics, inspired by learning-to-drive challenges, Formula-style racing, and multimodal trajectory prediction for autonomous driving. Additionally, we provide the L2R framework suite, facilitating simulated racing on high-precision models of real-world tracks, such as the famed Thruxton Circuit and the Las Vegas Motor Speedway. Finally, we provide an official L2R task dataset of expert demonstrations, as well as a series of baseline experiments and reference implementations. We make all code available: https://github.com/hermgerm29/learn-to-race
Space ML: Distributed Open-source Research with Citizen Scientists for the Advancement of Space Technology for NASA
Dec 27, 2020Traditionally, academic labs conduct open-ended research with the primary focus on discoveries with long-term value, rather than direct products that can be deployed in the real world. On the other hand, research in the industry is driven by its expected commercial return on investment, and hence focuses on a real world product with short-term timelines. In both cases, opportunity is selective, often available to researchers with advanced educational backgrounds. Research often happens behind closed doors and may be kept confidential until either its publication or product release, exacerbating the problem of AI reproducibility and slowing down future research by others in the field. As many research organizations tend to exclusively focus on specific areas, opportunities for interdisciplinary research reduce. Undertaking long-term bold research in unexplored fields with non-commercial yet great public value is hard due to factors including the high upfront risk, budgetary constraints, and a lack of availability of data and experts in niche fields. Only a few companies or well-funded research labs can afford to do such long-term research. With research organizations focused on an exploding array of fields and resources spread thin, opportunities for the maturation of interdisciplinary research reduce. Apart from these exigencies, there is also a need to engage citizen scientists through open-source contributors to play an active part in the research dialogue. We present a short case study of Space ML, an extension of the Frontier Development Lab, an AI accelerator for NASA. Space ML distributes open-source research and invites volunteer citizen scientists to partake in development and deployment of high social value products at the intersection of space and AI.
Learnings from Frontier Development Lab and SpaceML -- AI Accelerators for NASA and ESA
Nov 09, 2020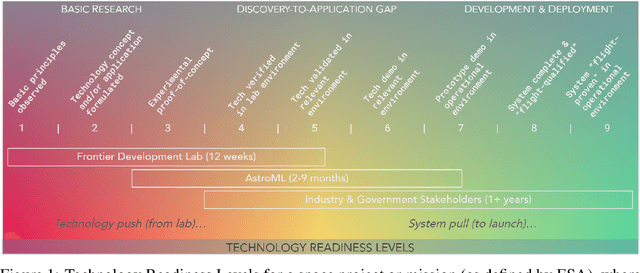
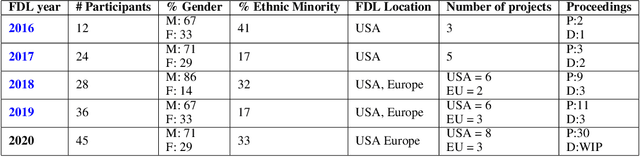
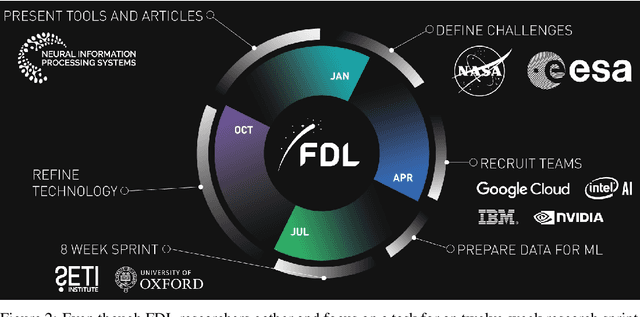
Research with AI and ML technologies lives in a variety of settings with often asynchronous goals and timelines: academic labs and government organizations pursue open-ended research focusing on discoveries with long-term value, while research in industry is driven by commercial pursuits and hence focuses on short-term timelines and return on investment. The journey from research to product is often tacit or ad hoc, resulting in technology transition failures, further exacerbated when research and development is interorganizational and interdisciplinary. Even more, much of the ability to produce results remains locked in the private repositories and know-how of the individual researcher, slowing the impact on future research by others and contributing to the ML community's challenges in reproducibility. With research organizations focused on an exploding array of fields, opportunities for the handover and maturation of interdisciplinary research reduce. With these tensions, we see an emerging need to measure the correctness, impact, and relevance of research during its development to enable better collaboration, improved reproducibility, faster progress, and more trusted outcomes. We perform a case study of the Frontier Development Lab (FDL), an AI accelerator under a public-private partnership from NASA and ESA. FDL research follows principled practices that are grounded in responsible development, conduct, and dissemination of AI research, enabling FDL to churn successful interdisciplinary and interorganizational research projects, measured through NASA's Technology Readiness Levels. We also take a look at the SpaceML Open Source Research Program, which helps accelerate and transition FDL's research to deployable projects with wide spread adoption amongst citizen scientists.