 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibFree: Self-Supervised View Feature Separation for Calibration-Free Multi-Camera Multi-Object Tracking
May 10, 2026Multi-camera multi-object tracking (MCMOT) faces significant challenges in maintaining consistent object identities across varying camera perspectives, particularly when precise calibration and extensive annotations are required. In this paper, we present CalibFree, a self-supervised representation learning framework that does not need any calibration or manual labeling for the MCMOT task. By promoting feature separation between view-agnostic and view-specific representations through single-view distillation and cross-view reconstruction, our method adapts to complex, dynamic scenarios with minimal overhead. Experiments on the MMP-MvMHAT dataset show a 3% improvement in overall accuracy and a 7.5% increase in the average F1 score over state-of-the-art approaches, confirming the effectiveness of our calibration-free design. Moreover, on the more diverse MvMHAT dataset, our approach demonstrates superior over-time tracking and strong cross-view performance, highlighting its adaptability to a wide range of camera configurations. Code will be publicly available upon acceptance.
Exploiting VLM Localizability and Semantics for Open Vocabulary Action Detection
Nov 17, 2024



Action detection aims to detect (recognize and localize) human actions spatially and temporally in videos. Existing approaches focus on the closed-set setting where an action detector is trained and tested on videos from a fixed set of action categories. However, this constrained setting is not viable in an open world where test videos inevitably come beyond the trained action categories. In this paper, we address the practical yet challenging Open-Vocabulary Action Detection (OVAD) problem. It aims to detect any action in test videos while training a model on a fixed set of action categories. To achieve such an open-vocabulary capability, we propose a novel method OpenMixer that exploits the inherent semantics and localizability of large vision-language models (VLM) within the family of query-based detection transformers (DETR). Specifically, the OpenMixer is developed by spatial and temporal OpenMixer blocks (S-OMB and T-OMB), and a dynamically fused alignment (DFA) module. The three components collectively enjoy the merits of strong generalization from pre-trained VLMs and end-to-end learning from DETR design. Moreover, we established OVAD benchmarks under various settings, and the experimental results show that the OpenMixer performs the best over baselines for detecting seen and unseen actions. We release the codes, models, and dataset splits at https://github.com/Cogito2012/OpenMixer.
Learning to Localize Actions in Instructional Videos with LLM-Based Multi-Pathway Text-Video Alignment
Sep 22, 2024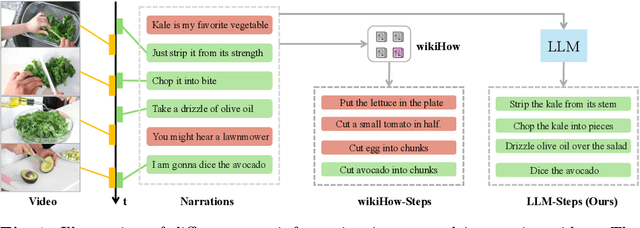



Learning to localize temporal boundaries of procedure steps in instructional videos is challenging due to the limited availability of annotated large-scale training videos. Recent works focus on learning the cross-modal alignment between video segments and ASR-transcripted narration texts through contrastive learning. However, these methods fail to account for the alignment noise, i.e., irrelevant narrations to the instructional task in videos and unreliable timestamps in narrations. To address these challenges, this work proposes a novel training framework. Motivated by the strong capabilities of Large Language Models (LLMs) in procedure understanding and text summarization, we first apply an LLM to filter out task-irrelevant information and summarize task-related procedure steps (LLM-steps) from narrations. To further generate reliable pseudo-matching between the LLM-steps and the video for training, we propose the Multi-Pathway Text-Video Alignment (MPTVA) strategy. The key idea is to measure alignment between LLM-steps and videos via multiple pathways, including: (1) step-narration-video alignment using narration timestamps, (2) direct step-to-video alignment based on their long-term semantic similarity, and (3) direct step-to-video alignment focusing on short-term fine-grained semantic similarity learned from general video domains. The results from different pathways are fused to generate reliable pseudo step-video matching. We conducted extensive experiments across various tasks and problem settings to evaluate our proposed method. Our approach surpasses state-of-the-art methods in three downstream tasks: procedure step grounding, step localization, and narration grounding by 5.9\%, 3.1\%, and 2.8\%.
MCTR: Multi Camera Tracking Transformer
Aug 23, 2024

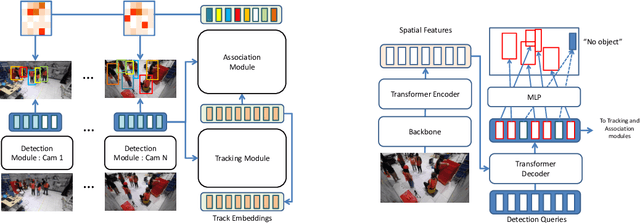

Multi-camera tracking plays a pivotal role in various real-world applications. While end-to-end methods have gained significant interest in single-camera tracking, multi-camera tracking remains predominantly reliant on heuristic techniques. In response to this gap, this paper introduces Multi-Camera Tracking tRansformer (MCTR), a novel end-to-end approach tailored for multi-object detection and tracking across multiple cameras with overlapping fields of view. MCTR leverages end-to-end detectors like DEtector TRansformer (DETR) to produce detections and detection embeddings independently for each camera view. The framework maintains set of track embeddings that encaplusate global information about the tracked objects, and updates them at every frame by integrating the local information from the view-specific detection embeddings. The track embeddings are probabilistically associated with detections in every camera view and frame to generate consistent object tracks. The soft probabilistic association facilitates the design of differentiable losses that enable end-to-end training of the entire system. To validate our approach, we conduct experiments on MMPTrack and AI City Challenge, two recently introduced large-scale multi-camera multi-object tracking datasets.
Deep Video Codec Control
Sep 16, 2023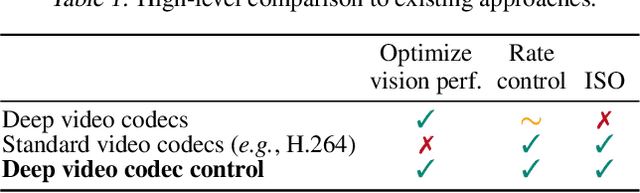
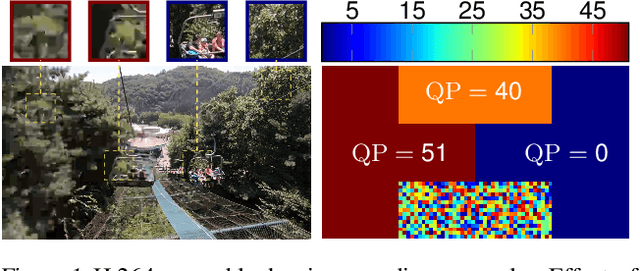
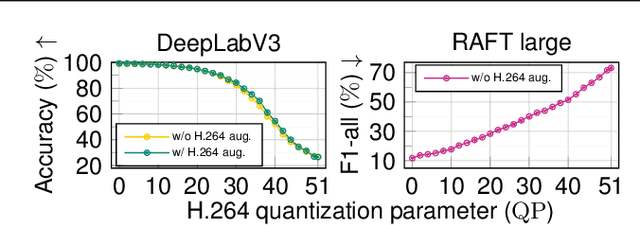
Lossy video compression is commonly used when transmitting and storing video data. Unified video codecs (e.g., H.264 or H.265) remain the de facto standard, despite the availability of advanced (neural) compression approaches. Transmitting videos in the face of dynamic network bandwidth conditions requires video codecs to adapt to vastly different compression strengths. Rate control modules augment the codec's compression such that bandwidth constraints are satisfied and video distortion is minimized. While, both standard video codes and their rate control modules are developed to minimize video distortion w.r.t. human quality assessment, preserving the downstream performance of deep vision models is not considered. In this paper, we present the first end-to-end learnable deep video codec control considering both bandwidth constraints and downstream vision performance, while not breaking existing standardization. We demonstrate for two common vision tasks (semantic segmentation and optical flow estimation) and on two different datasets that our deep codec control better preserves downstream performance than using 2-pass average bit rate control while meeting dynamic bandwidth constraints and adhering to standardizations.
Differentiable JPEG: The Devil is in the Details
Sep 13, 2023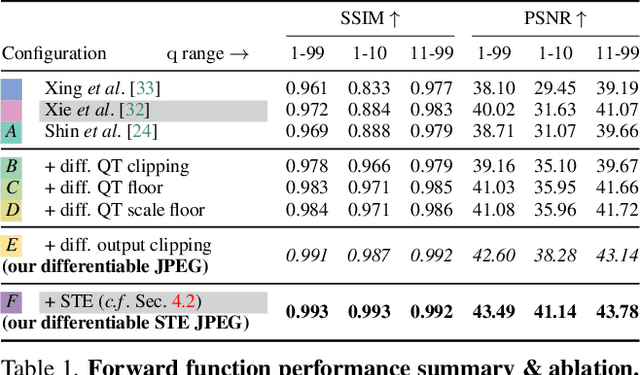
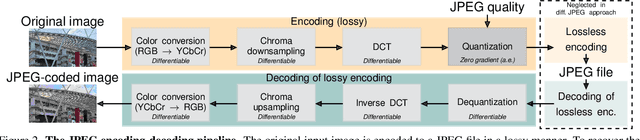
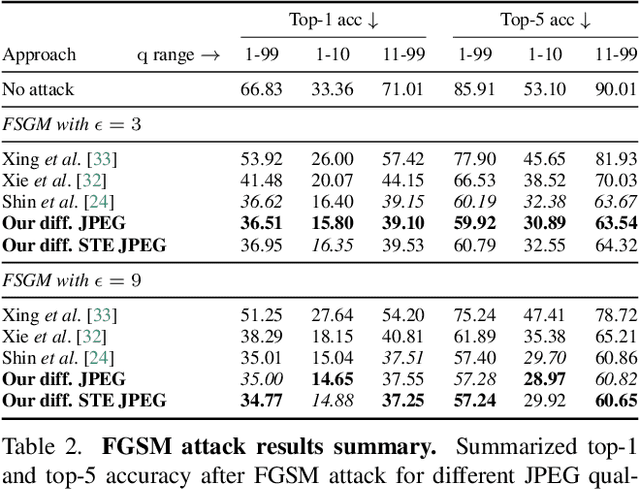

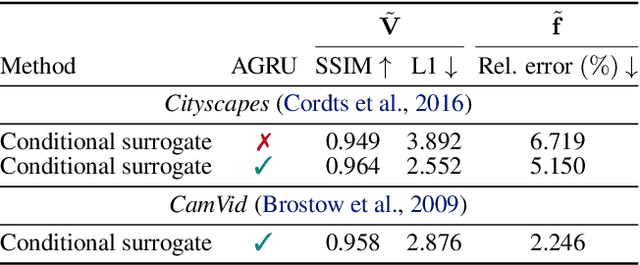
JPEG remains one of the most widespread lossy image coding methods. However, the non-differentiable nature of JPEG restricts the application in deep learning pipelines. Several differentiable approximations of JPEG have recently been proposed to address this issue. This paper conducts a comprehensive review of existing diff. JPEG approaches and identifies critical details that have been missed by previous methods. To this end, we propose a novel diff. JPEG approach, overcoming previous limitations. Our approach is differentiable w.r.t. the input image, the JPEG quality, the quantization tables, and the color conversion parameters. We evaluate the forward and backward performance of our diff. JPEG approach against existing methods. Additionally, extensive ablations are performed to evaluate crucial design choices. Our proposed diff. JPEG resembles the (non-diff.) reference implementation best, significantly surpassing the recent-best diff. approach by $3.47$dB (PSNR) on average. For strong compression rates, we can even improve PSNR by $9.51$dB. Strong adversarial attack results are yielded by our diff. JPEG, demonstrating the effective gradient approximation. Our code is available at https://github.com/necla-ml/Diff-JPEG.
Learning Higher-order Object Interactions for Keypoint-based Video Understanding
May 16, 2023
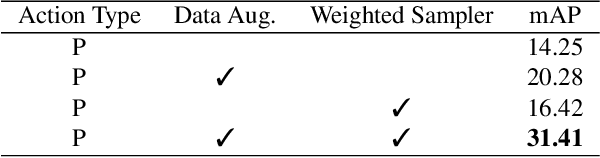
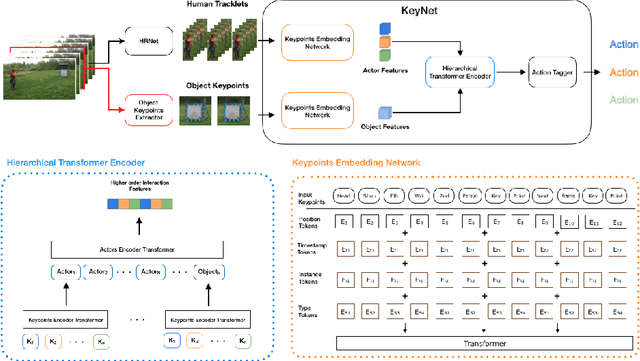

Action recognition is an important problem that requires identifying actions in video by learning complex interactions across scene actors and objects. However, modern deep-learning based networks often require significant computation, and may capture scene context using various modalities that further increases compute costs. Efficient methods such as those used for AR/VR often only use human-keypoint information but suffer from a loss of scene context that hurts accuracy. In this paper, we describe an action-localization method, KeyNet, that uses only the keypoint data for tracking and action recognition. Specifically, KeyNet introduces the use of object based keypoint information to capture context in the scene. Our method illustrates how to build a structured intermediate representation that allows modeling higher-order interactions in the scene from object and human keypoints without using any RGB information. We find that KeyNet is able to track and classify human actions at just 5 FPS. More importantly, we demonstrate that object keypoints can be modeled to recover any loss in context from using keypoint information over AVA action and Kinetics datasets.
Adaptive Sample Selection for Robust Learning under Label Noise
Jul 27, 2021
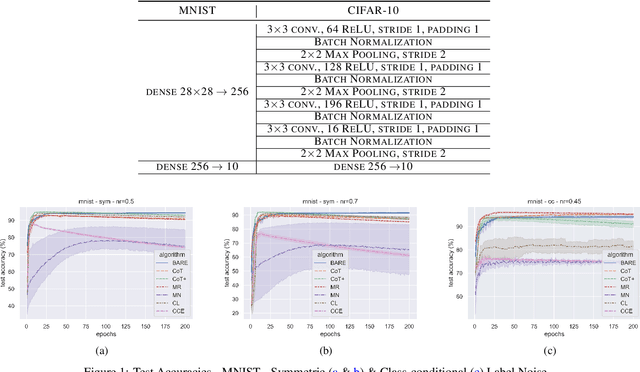
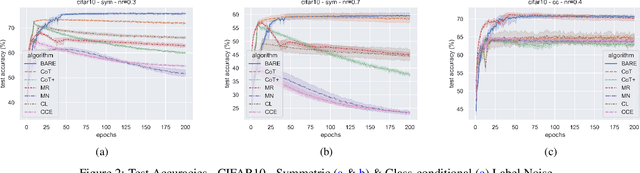
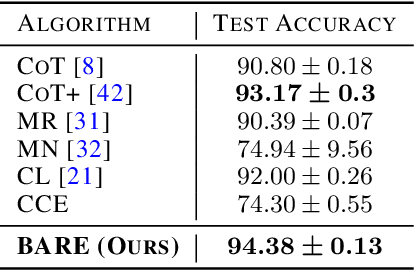
Deep Neural Networks (DNNs) have been shown to be susceptible to memorization or overfitting in the presence of noisily labelled data. For the problem of robust learning under such noisy data, several algorithms have been proposed. A prominent class of algorithms rely on sample selection strategies, motivated by curriculum learning. For example, many algorithms use the `small loss trick' wherein a fraction of samples with loss values below a certain threshold are selected for training. These algorithms are sensitive to such thresholds, and it is difficult to fix or learn these thresholds. Often, these algorithms also require information such as label noise rates which are typically unavailable in practice. In this paper, we propose a data-dependent, adaptive sample selection strategy that relies only on batch statistics of a given mini-batch to provide robustness against label noise. The algorithm does not have any additional hyperparameters for sample selection, does not need any information on noise rates, and does not need access to separate data with clean labels. We empirically demonstrate the effectiveness of our algorithm on benchmark datasets.
Memorization in Deep Neural Networks: Does the Loss Function matter?
Jul 22, 2021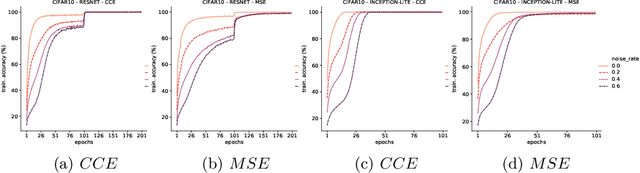
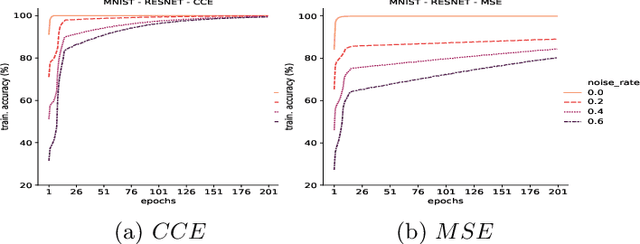
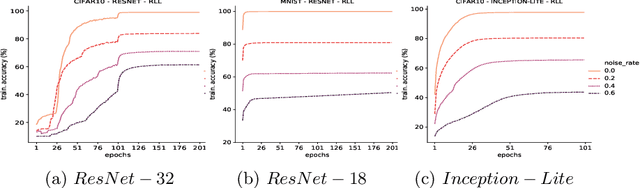
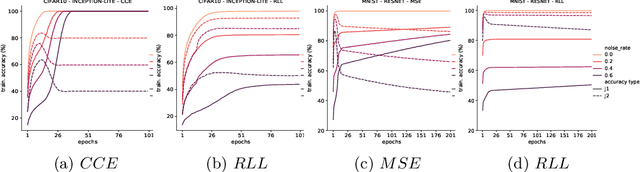
Deep Neural Networks, often owing to the overparameterization, are shown to be capable of exactly memorizing even randomly labelled data. Empirical studies have also shown that none of the standard regularization techniques mitigate such overfitting. We investigate whether the choice of the loss function can affect this memorization. We empirically show, with benchmark data sets MNIST and CIFAR-10, that a symmetric loss function, as opposed to either cross-entropy or squared error loss, results in significant improvement in the ability of the network to resist such overfitting. We then provide a formal definition for robustness to memorization and provide a theoretical explanation as to why the symmetric losses provide this robustness. Our results clearly bring out the role loss functions alone can play in this phenomenon of memorization.
Scalable Data Balancing for Unlabeled Satellite Imagery
Jul 07, 2021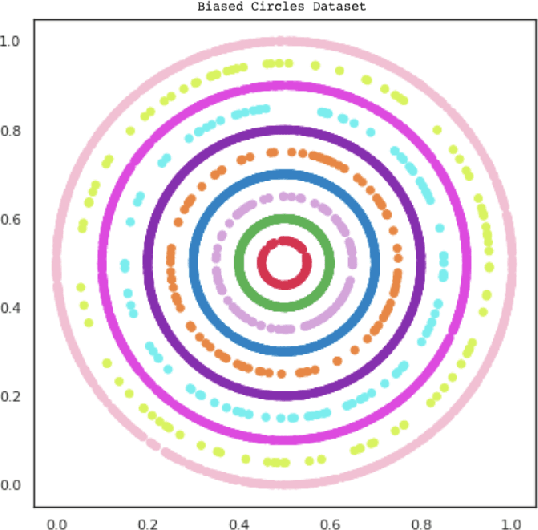
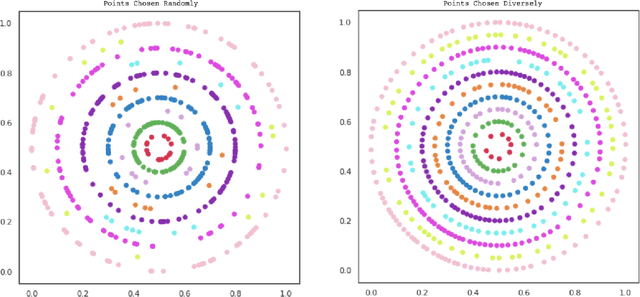
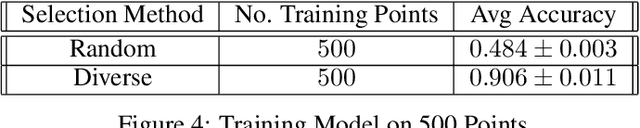
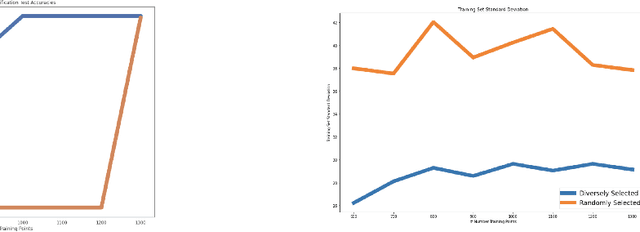
Data imbalance is a ubiquitous problem in machine learning. In large scale collected and annotated datasets, data imbalance is either mitigated manually by undersampling frequent classes and oversampling rare classes, or planned for with imputation and augmentation techniques. In both cases balancing data requires labels. In other words, only annotated data can be balanced. Collecting fully annotated datasets is challenging, especially for large scale satellite systems such as the unlabeled NASA's 35 PB Earth Imagery dataset. Although the NASA Earth Imagery dataset is unlabeled, there are implicit properties of the data source that we can rely on to hypothesize about its imbalance, such as distribution of land and water in the case of the Earth's imagery. We present a new iterative method to balance unlabeled data. Our method utilizes image embeddings as a proxy for image labels that can be used to balance data, and ultimately when trained increases overall accuracy.