 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Higher-order Object Interactions for Keypoint-based Video Understanding
May 16, 2023
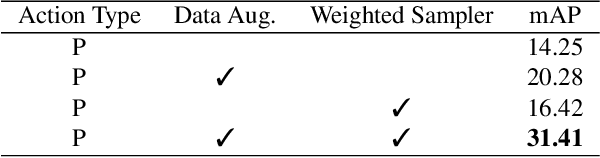
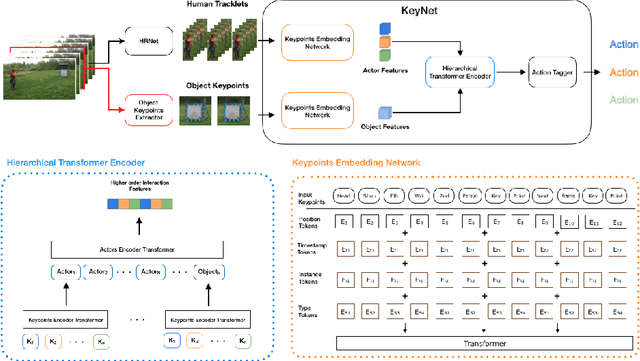

Action recognition is an important problem that requires identifying actions in video by learning complex interactions across scene actors and objects. However, modern deep-learning based networks often require significant computation, and may capture scene context using various modalities that further increases compute costs. Efficient methods such as those used for AR/VR often only use human-keypoint information but suffer from a loss of scene context that hurts accuracy. In this paper, we describe an action-localization method, KeyNet, that uses only the keypoint data for tracking and action recognition. Specifically, KeyNet introduces the use of object based keypoint information to capture context in the scene. Our method illustrates how to build a structured intermediate representation that allows modeling higher-order interactions in the scene from object and human keypoints without using any RGB information. We find that KeyNet is able to track and classify human actions at just 5 FPS. More importantly, we demonstrate that object keypoints can be modeled to recover any loss in context from using keypoint information over AVA action and Kinetics datasets.
COMPOSER: Compositional Learning of Group Activity in Videos
Dec 11, 2021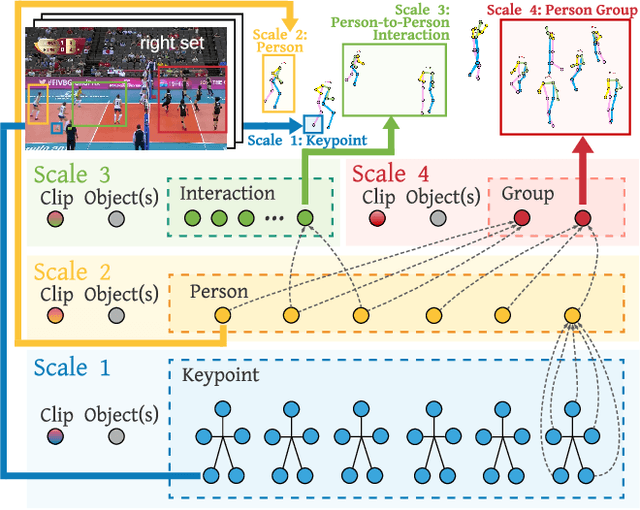
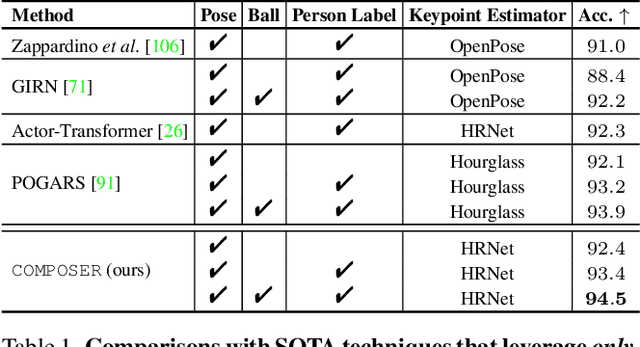
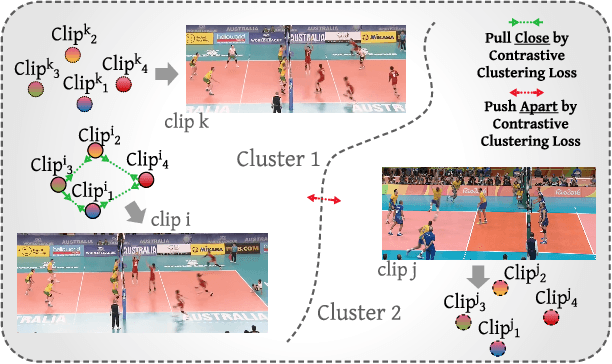
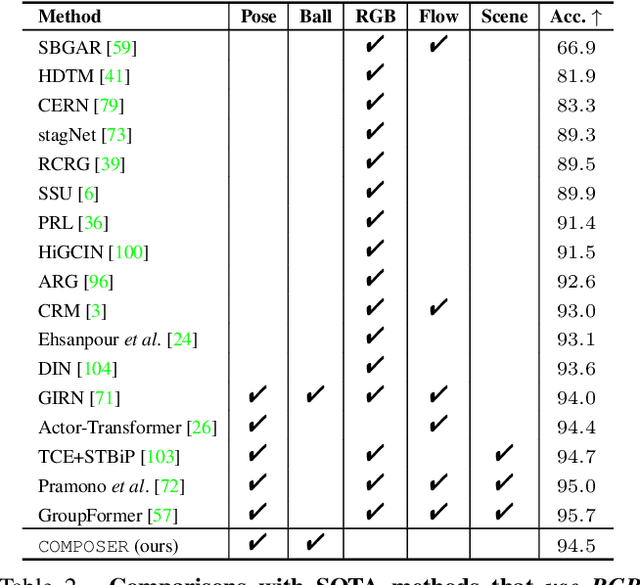
Group Activity Recognition (GAR) detects the activity performed by a group of actors in a short video clip. The task requires the compositional understanding of scene entities and relational reasoning between them. We approach GAR by modeling the video as a series of tokens that represent the multi-scale semantic concepts in the video. We propose COMPOSER, a Multiscale Transformer based architecture that performs attention-based reasoning over tokens at each scale and learns group activity compositionally. In addition, we only use the keypoint modality which reduces scene biases and improves the generalization ability of the model. We improve the multi-scale representations in COMPOSER by clustering the intermediate scale representations, while maintaining consistent cluster assignments between scales. Finally, we use techniques such as auxiliary prediction and novel data augmentations (e.g., Actor Dropout) to aid model training. We demonstrate the model's strength and interpretability on the challenging Volleyball dataset. COMPOSER achieves a new state-of-the-art 94.5% accuracy with the keypoint-only modality. COMPOSER outperforms the latest GAR methods that rely on RGB signals, and performs favorably compared against methods that exploit multiple modalities. Our code will be available.
Hopper: Multi-hop Transformer for Spatiotemporal Reasoning
Mar 22, 2021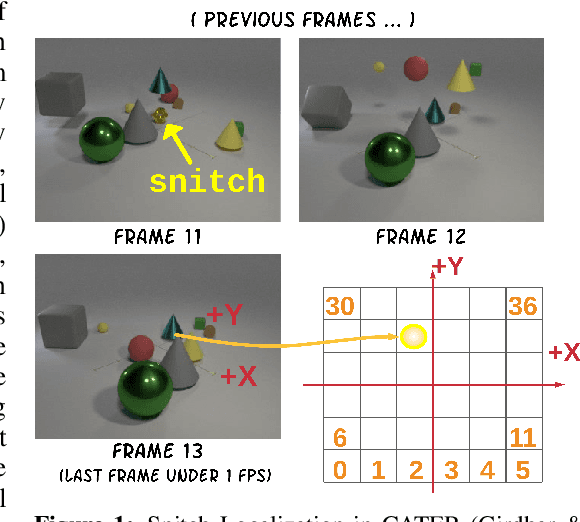
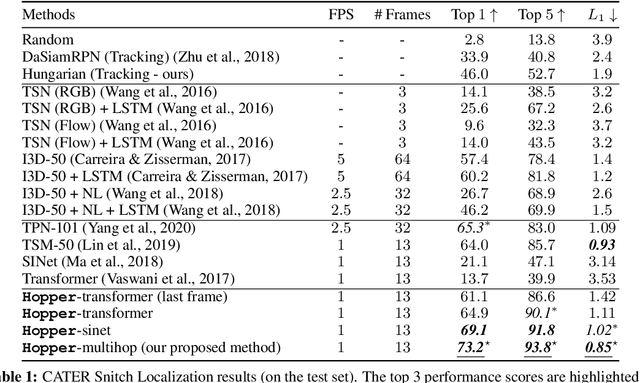
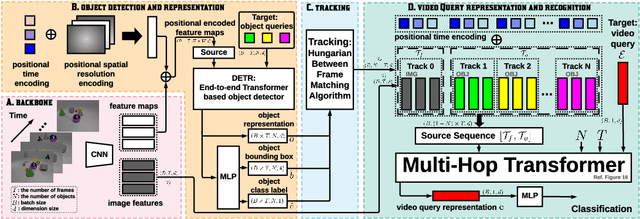
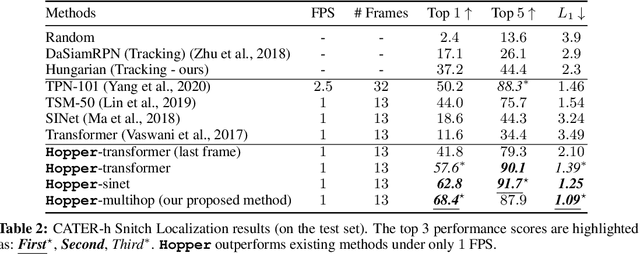
This paper considers the problem of spatiotemporal object-centric reasoning in videos. Central to our approach is the notion of object permanence, i.e., the ability to reason about the location of objects as they move through the video while being occluded, contained or carried by other objects. Existing deep learning based approaches often suffer from spatiotemporal biases when applied to video reasoning problems. We propose Hopper, which uses a Multi-hop Transformer for reasoning object permanence in videos. Given a video and a localization query, Hopper reasons over image and object tracks to automatically hop over critical frames in an iterative fashion to predict the final position of the object of interest. We demonstrate the effectiveness of using a contrastive loss to reduce spatiotemporal biases. We evaluate over CATER dataset and find that Hopper achieves 73.2% Top-1 accuracy using just 1 FPS by hopping through just a few critical frames. We also demonstrate Hopper can perform long-term reasoning by building a CATER-h dataset that requires multi-step reasoning to localize objects of interest correctly.
S3VAE: Self-Supervised Sequential VAE for Representation Disentanglement and Data Generation
May 23, 2020

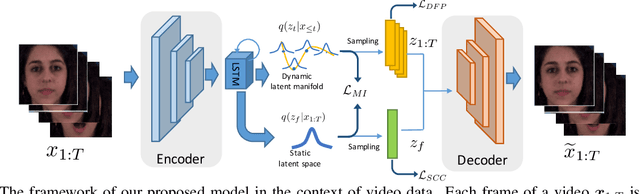
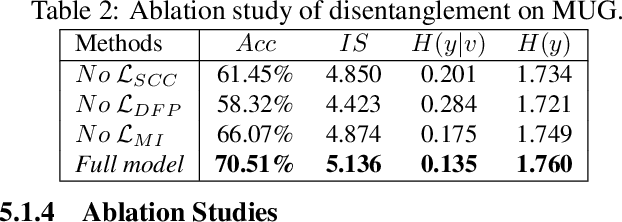
We propose a sequential variational autoencoder to learn disentangled representations of sequential data (e.g., videos and audios) under self-supervision. Specifically, we exploit the benefits of some readily accessible supervisory signals from input data itself or some off-the-shelf functional models and accordingly design auxiliary tasks for our model to utilize these signals. With the supervision of the signals, our model can easily disentangle the representation of an input sequence into static factors and dynamic factors (i.e., time-invariant and time-varying parts). Comprehensive experiments across videos and audios verify the effectiveness of our model on representation disentanglement and generation of sequential data, and demonstrate that, our model with self-supervision performs comparable to, if not better than, the fully-supervised model with ground truth labels, and outperforms state-of-the-art unsupervised models by a large margin.
15 Keypoints Is All You Need
Dec 05, 2019
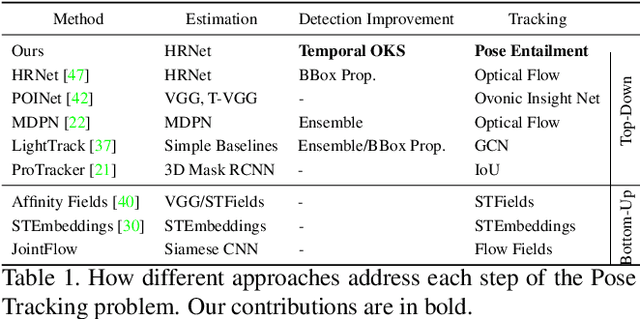

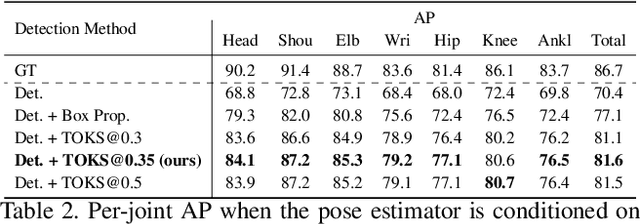
Pose tracking is an important problem that requires identifying unique human pose-instances and matching them temporally across different frames of a video. However, existing pose tracking methods are unable to accurately model temporal relationships and require significant computation, often computing the tracks offline. We present an efficient Multi-person Pose Tracking method, KeyTrack, that only relies on keypoint information without using any RGB or optical flow information to track human keypoints in real-time. Keypoints are tracked using our Pose Entailment method, in which, first, a pair of pose estimates is sampled from different frames in a video and tokenized. Then, a Transformer-based network makes a binary classification as to whether one pose temporally follows another. Furthermore, we improve our top-down pose estimation method with a novel, parameter-free, keypoint refinement technique that improves the keypoint estimates used during the Pose Entailment step. We achieve state-of-the-art results on the PoseTrack'17 and the PoseTrack'18 benchmarks while using only a fraction of the computation required by most other methods for computing the tracking information.
Tripping through time: Efficient Localization of Activities in Videos
Apr 25, 2019



Localizing moments in untrimmed videos via language queries is a new and interesting task that requires the ability to accurately ground language into video. Previous works have approached this task by processing the entire video, often more than once, to localize relevant activities. In the real world applications that this task lends itself to, such as surveillance, efficiency a is pivotal trait of a system. In this paper, we present TripNet, an end-to-end system that uses a gated attention architecture to model fine-grained textual and visual representations in order to align text and video content. Furthermore, TripNet uses reinforcement learning to efficiently localize relevant activity clips in long videos, by learning how to intelligently skip around the video. In our evaluation over Charades-STA, ActivityNet Captions and the TACoS dataset, we find that TripNet achieves high accuracy and saves processing time by only looking at 32-41% of the entire video.
Attend and Interact: Higher-Order Object Interactions for Video Understanding
Mar 20, 2018



Human actions often involve complex interactions across several inter-related objects in the scene. However, existing approaches to fine-grained video understanding or visual relationship detection often rely on single object representation or pairwise object relationships. Furthermore, learning interactions across multiple objects in hundreds of frames for video is computationally infeasible and performance may suffer since a large combinatorial space has to be modeled. In this paper, we propose to efficiently learn higher-order interactions between arbitrary subgroups of objects for fine-grained video understanding. We demonstrate that modeling object interactions significantly improves accuracy for both action recognition and video captioning, while saving more than 3-times the computation over traditional pairwise relationships. The proposed method is validated on two large-scale datasets: Kinetics and ActivityNet Captions. Our SINet and SINet-Caption achieve state-of-the-art performances on both datasets even though the videos are sampled at a maximum of 1 FPS. To the best of our knowledge, this is the first work modeling object interactions on open domain large-scale video datasets, and we additionally model higher-order object interactions which improves the performance with low computational costs.
Grounded Objects and Interactions for Video Captioning
Nov 16, 2017


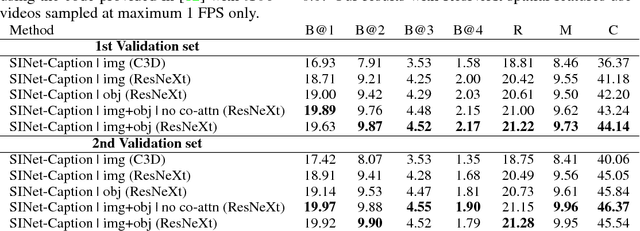
We address the problem of video captioning by grounding language generation on object interactions in the video. Existing work mostly focuses on overall scene understanding with often limited or no emphasis on object interactions to address the problem of video understanding. In this paper, we propose SINet-Caption that learns to generate captions grounded over higher-order interactions between arbitrary groups of objects for fine-grained video understanding. We discuss the challenges and benefits of such an approach. We further demonstrate state-of-the-art results on the ActivityNet Captions dataset using our model, SINet-Caption based on this approach.
Pruning Filters for Efficient ConvNets
Mar 10, 2017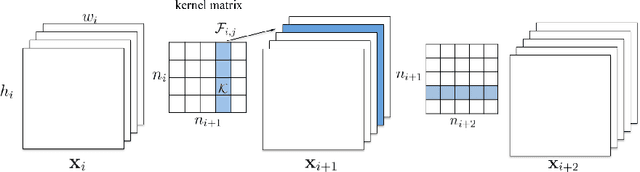
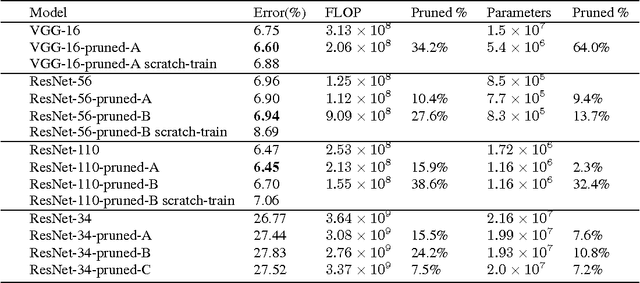
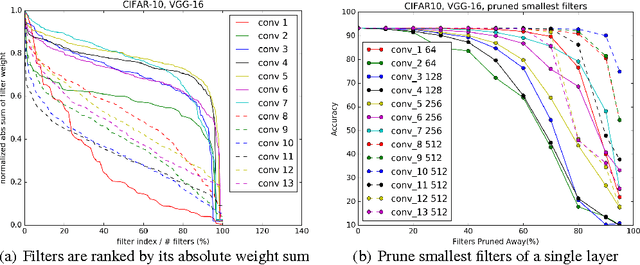
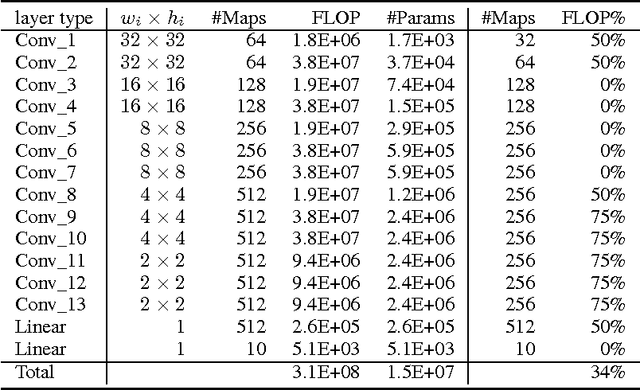
The success of CNNs in various applications is accompanied by a significant increase in the computation and parameter storage costs. Recent efforts toward reducing these overheads involve pruning and compressing the weights of various layers without hurting original accuracy. However, magnitude-based pruning of weights reduces a significant number of parameters from the fully connected layers and may not adequately reduce the computation costs in the convolutional layers due to irregular sparsity in the pruned networks. We present an acceleration method for CNNs, where we prune filters from CNNs that are identified as having a small effect on the output accuracy. By removing whole filters in the network together with their connecting feature maps, the computation costs are reduced significantly. In contrast to pruning weights, this approach does not result in sparse connectivity patterns. Hence, it does not need the support of sparse convolution libraries and can work with existing efficient BLAS libraries for dense matrix multiplications. We show that even simple filter pruning techniques can reduce inference costs for VGG-16 by up to 34% and ResNet-110 by up to 38% on CIFAR10 while regaining close to the original accuracy by retraining the networks.