 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgroup Discovery with the Cox Model
Dec 23, 2025



We study the problem of subgroup discovery for survival analysis, where the goal is to find an interpretable subset of the data on which a Cox model is highly accurate. Our work is the first to study this particular subgroup problem, for which we make several contributions. Subgroup discovery methods generally require a "quality function" in order to sift through and select the most advantageous subgroups. We first examine why existing natural choices for quality functions are insufficient to solve the subgroup discovery problem for the Cox model. To address the shortcomings of existing metrics, we introduce two technical innovations: the *expected prediction entropy (EPE)*, a novel metric for evaluating survival models which predict a hazard function; and the *conditional rank statistics (CRS)*, a statistical object which quantifies the deviation of an individual point to the distribution of survival times in an existing subgroup. We study the EPE and CRS theoretically and show that they can solve many of the problems with existing metrics. We introduce a total of eight algorithms for the Cox subgroup discovery problem. The main algorithm is able to take advantage of both the EPE and the CRS, allowing us to give theoretical correctness results for this algorithm in a well-specified setting. We evaluate all of the proposed methods empirically on both synthetic and real data. The experiments confirm our theory, showing that our contributions allow for the recovery of a ground-truth subgroup in well-specified cases, as well as leading to better model fit compared to naively fitting the Cox model to the whole dataset in practical settings. Lastly, we conduct a case study on jet engine simulation data from NASA. The discovered subgroups uncover known nonlinearities/homogeneity in the data, and which suggest design choices which have been mirrored in practice.
DiscussLLM: Teaching Large Language Models When to Speak
Aug 25, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and generating human-like text, yet they largely operate as reactive agents, responding only when directly prompted. This passivity creates an "awareness gap," limiting their potential as truly collaborative partners in dynamic human discussions. We introduce $\textit{DiscussLLM}$, a framework designed to bridge this gap by training models to proactively decide not just $\textit{what}$ to say, but critically, $\textit{when}$ to speak. Our primary contribution is a scalable two-stage data generation pipeline that synthesizes a large-scale dataset of realistic multi-turn human discussions. Each discussion is annotated with one of five intervention types (e.g., Factual Correction, Concept Definition) and contains an explicit conversational trigger where an AI intervention adds value. By training models to predict a special silent token when no intervention is needed, they learn to remain quiet until a helpful contribution can be made. We explore two architectural baselines: an integrated end-to-end model and a decoupled classifier-generator system optimized for low-latency inference. We evaluate these models on their ability to accurately time interventions and generate helpful responses, paving the way for more situationally aware and proactive conversational AI.
MCTR: Multi Camera Tracking Transformer
Aug 23, 2024

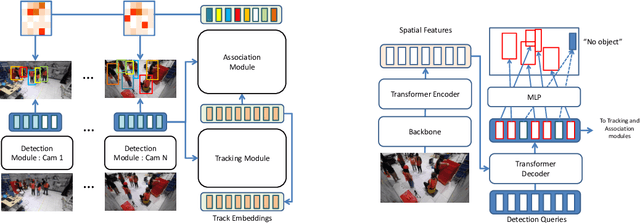

Multi-camera tracking plays a pivotal role in various real-world applications. While end-to-end methods have gained significant interest in single-camera tracking, multi-camera tracking remains predominantly reliant on heuristic techniques. In response to this gap, this paper introduces Multi-Camera Tracking tRansformer (MCTR), a novel end-to-end approach tailored for multi-object detection and tracking across multiple cameras with overlapping fields of view. MCTR leverages end-to-end detectors like DEtector TRansformer (DETR) to produce detections and detection embeddings independently for each camera view. The framework maintains set of track embeddings that encaplusate global information about the tracked objects, and updates them at every frame by integrating the local information from the view-specific detection embeddings. The track embeddings are probabilistically associated with detections in every camera view and frame to generate consistent object tracks. The soft probabilistic association facilitates the design of differentiable losses that enable end-to-end training of the entire system. To validate our approach, we conduct experiments on MMPTrack and AI City Challenge, two recently introduced large-scale multi-camera multi-object tracking datasets.
Attend and Interact: Higher-Order Object Interactions for Video Understanding
Mar 20, 2018



Human actions often involve complex interactions across several inter-related objects in the scene. However, existing approaches to fine-grained video understanding or visual relationship detection often rely on single object representation or pairwise object relationships. Furthermore, learning interactions across multiple objects in hundreds of frames for video is computationally infeasible and performance may suffer since a large combinatorial space has to be modeled. In this paper, we propose to efficiently learn higher-order interactions between arbitrary subgroups of objects for fine-grained video understanding. We demonstrate that modeling object interactions significantly improves accuracy for both action recognition and video captioning, while saving more than 3-times the computation over traditional pairwise relationships. The proposed method is validated on two large-scale datasets: Kinetics and ActivityNet Captions. Our SINet and SINet-Caption achieve state-of-the-art performances on both datasets even though the videos are sampled at a maximum of 1 FPS. To the best of our knowledge, this is the first work modeling object interactions on open domain large-scale video datasets, and we additionally model higher-order object interactions which improves the performance with low computational costs.
Grounded Objects and Interactions for Video Captioning
Nov 16, 2017


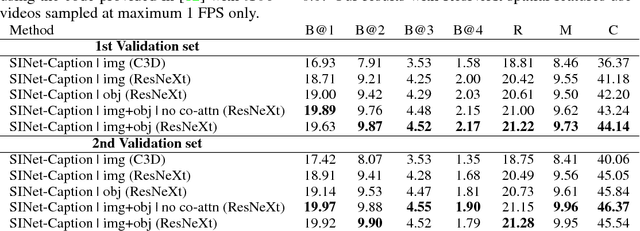
We address the problem of video captioning by grounding language generation on object interactions in the video. Existing work mostly focuses on overall scene understanding with often limited or no emphasis on object interactions to address the problem of video understanding. In this paper, we propose SINet-Caption that learns to generate captions grounded over higher-order interactions between arbitrary groups of objects for fine-grained video understanding. We discuss the challenges and benefits of such an approach. We further demonstrate state-of-the-art results on the ActivityNet Captions dataset using our model, SINet-Caption based on this approach.