 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCTR: Multi Camera Tracking Transformer
Aug 23, 2024

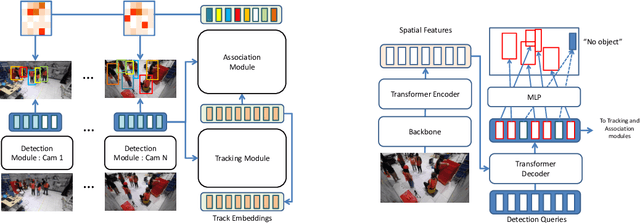

Multi-camera tracking plays a pivotal role in various real-world applications. While end-to-end methods have gained significant interest in single-camera tracking, multi-camera tracking remains predominantly reliant on heuristic techniques. In response to this gap, this paper introduces Multi-Camera Tracking tRansformer (MCTR), a novel end-to-end approach tailored for multi-object detection and tracking across multiple cameras with overlapping fields of view. MCTR leverages end-to-end detectors like DEtector TRansformer (DETR) to produce detections and detection embeddings independently for each camera view. The framework maintains set of track embeddings that encaplusate global information about the tracked objects, and updates them at every frame by integrating the local information from the view-specific detection embeddings. The track embeddings are probabilistically associated with detections in every camera view and frame to generate consistent object tracks. The soft probabilistic association facilitates the design of differentiable losses that enable end-to-end training of the entire system. To validate our approach, we conduct experiments on MMPTrack and AI City Challenge, two recently introduced large-scale multi-camera multi-object tracking datasets.
Hopper: Multi-hop Transformer for Spatiotemporal Reasoning
Mar 22, 2021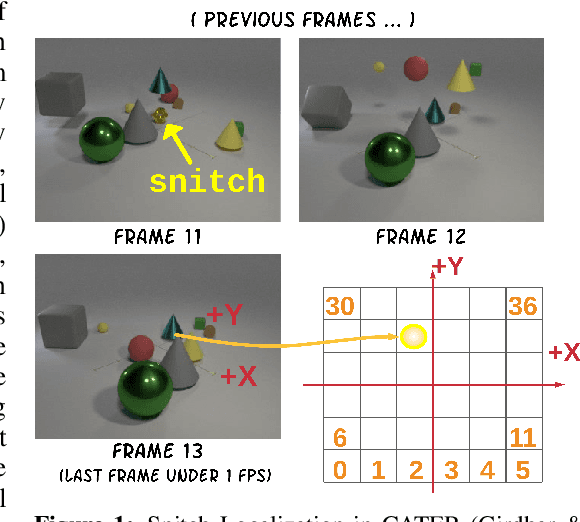
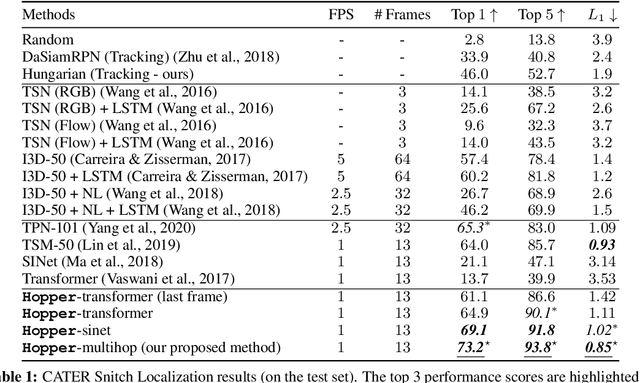
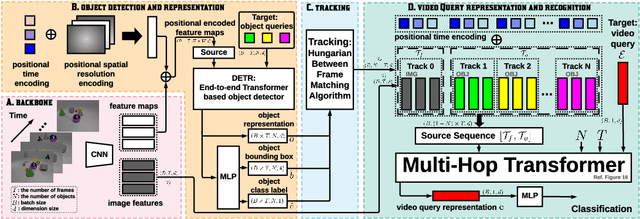
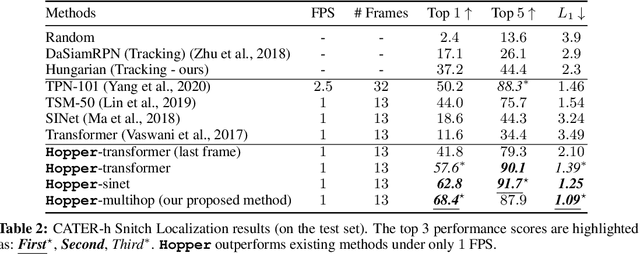
This paper considers the problem of spatiotemporal object-centric reasoning in videos. Central to our approach is the notion of object permanence, i.e., the ability to reason about the location of objects as they move through the video while being occluded, contained or carried by other objects. Existing deep learning based approaches often suffer from spatiotemporal biases when applied to video reasoning problems. We propose Hopper, which uses a Multi-hop Transformer for reasoning object permanence in videos. Given a video and a localization query, Hopper reasons over image and object tracks to automatically hop over critical frames in an iterative fashion to predict the final position of the object of interest. We demonstrate the effectiveness of using a contrastive loss to reduce spatiotemporal biases. We evaluate over CATER dataset and find that Hopper achieves 73.2% Top-1 accuracy using just 1 FPS by hopping through just a few critical frames. We also demonstrate Hopper can perform long-term reasoning by building a CATER-h dataset that requires multi-step reasoning to localize objects of interest correctly.
Supervised Feature Subset Selection and Feature Ranking for Multivariate Time Series without Feature Extraction
May 01, 2020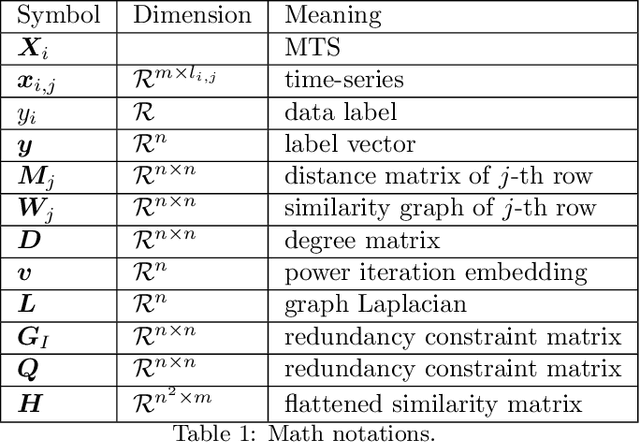
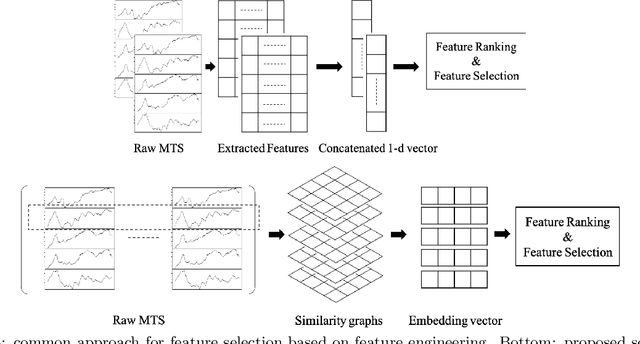
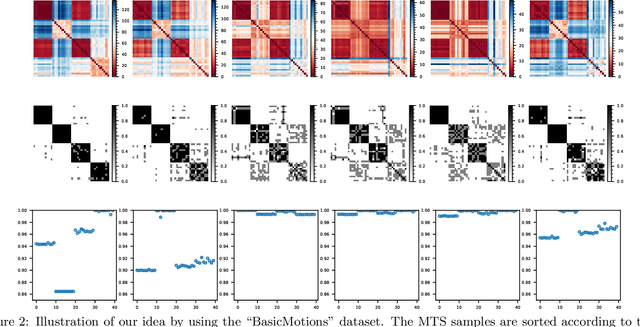
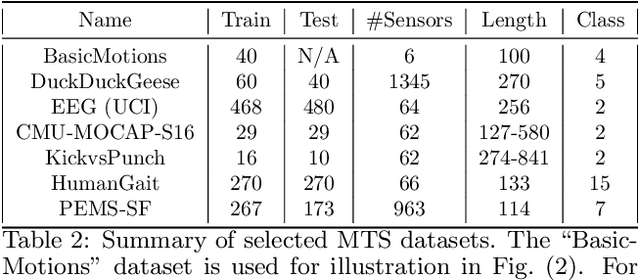
We introduce supervised feature ranking and feature subset selection algorithms for multivariate time series (MTS) classification. Unlike most existing supervised/unsupervised feature selection algorithms for MTS our techniques do not require a feature extraction step to generate a one-dimensional feature vector from the time series. Instead it is based on directly computing similarity between individual time series and assessing how well the resulting cluster structure matches the labels. The techniques are amenable to heterogeneous MTS data, where the time series measurements may have different sampling resolutions, and to multi-modal data.
Controlling the Precision-Recall Tradeoff in Differential Dependency Network Analysis
Jul 09, 2013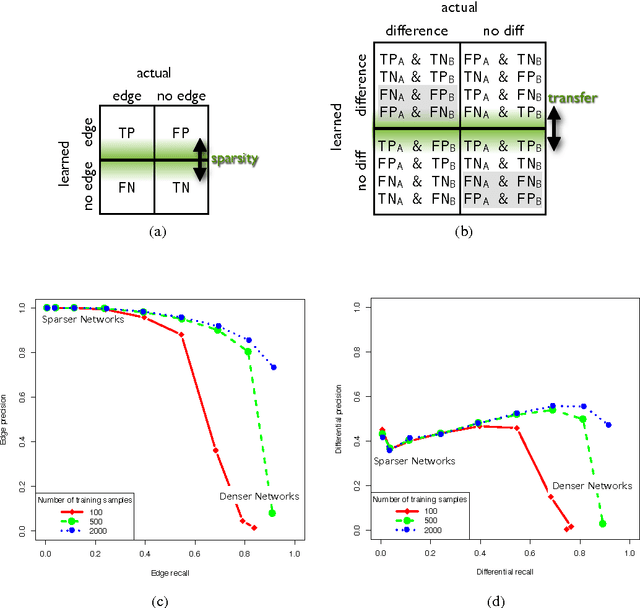

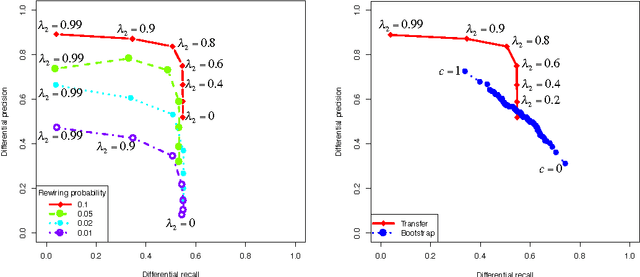
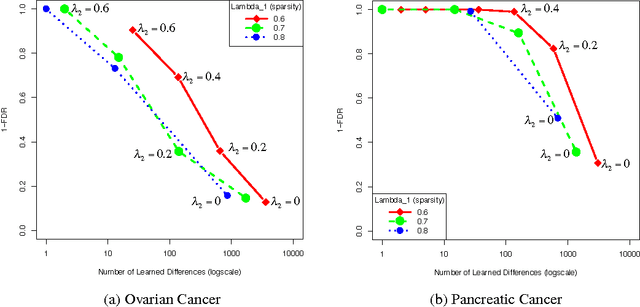
Graphical models have gained a lot of attention recently as a tool for learning and representing dependencies among variables in multivariate data. Often, domain scientists are looking specifically for differences among the dependency networks of different conditions or populations (e.g. differences between regulatory networks of different species, or differences between dependency networks of diseased versus healthy populations). The standard method for finding these differences is to learn the dependency networks for each condition independently and compare them. We show that this approach is prone to high false discovery rates (low precision) that can render the analysis useless. We then show that by imposing a bias towards learning similar dependency networks for each condition the false discovery rates can be reduced to acceptable levels, at the cost of finding a reduced number of differences. Algorithms developed in the transfer learning literature can be used to vary the strength of the imposed similarity bias and provide a natural mechanism to smoothly adjust this differential precision-recall tradeoff to cater to the requirements of the analysis conducted. We present real case studies (oncological and neurological) where domain experts use the proposed technique to extract useful differential networks that shed light on the biological processes involved in cancer and brain function.
Obtaining Calibrated Probabilities from Boosting
Jul 04, 2012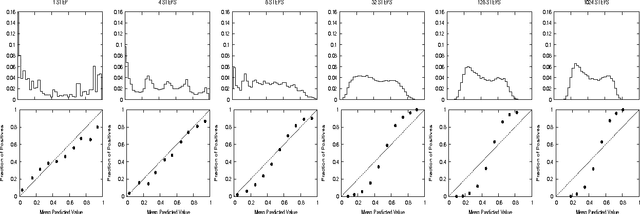

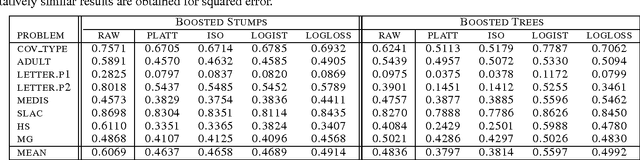

Boosted decision trees typically yield good accuracy, precision, and ROC area. However, because the outputs from boosting are not well calibrated posterior probabilities, boosting yields poor squared error and cross-entropy. We empirically demonstrate why AdaBoost predicts distorted probabilities and examine three calibration methods for correcting this distortion: Platt Scaling, Isotonic Regression, and Logistic Correction. We also experiment with boosting using log-loss instead of the usual exponential loss. Experiments show that Logistic Correction and boosting with log-loss work well when boosting weak models such as decision stumps, but yield poor performance when boosting more complex models such as full decision trees. Platt Scaling and Isotonic Regression, however, significantly improve the probabilities predicted by
A Binary Classification Framework for Two-Stage Multiple Kernel Learning
Jun 27, 2012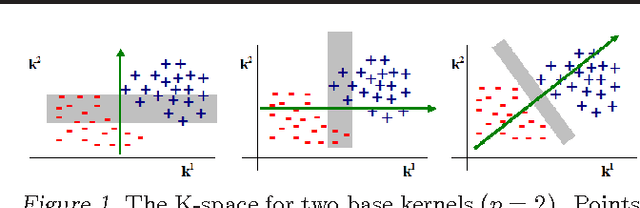
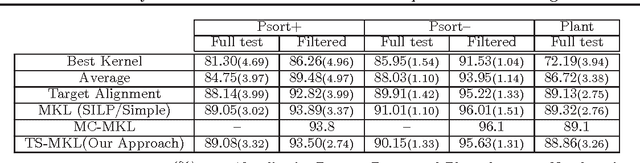

With the advent of kernel methods, automating the task of specifying a suitable kernel has become increasingly important. In this context, the Multiple Kernel Learning (MKL) problem of finding a combination of pre-specified base kernels that is suitable for the task at hand has received significant attention from researchers. In this paper we show that Multiple Kernel Learning can be framed as a standard binary classification problem with additional constraints that ensure the positive definiteness of the learned kernel. Framing MKL in this way has the distinct advantage that it makes it easy to leverage the extensive research in binary classification to develop better performing and more scalable MKL algorithms that are conceptually simpler, and, arguably, more accessible to practitioners. Experiments on nine data sets from different domains show that, despite its simplicity, the proposed technique compares favorably with current leading MKL approaches.