 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Feature Subset Selection and Feature Ranking for Multivariate Time Series without Feature Extraction
May 01, 2020
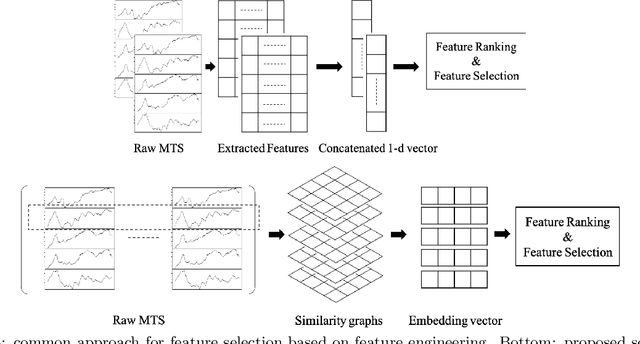
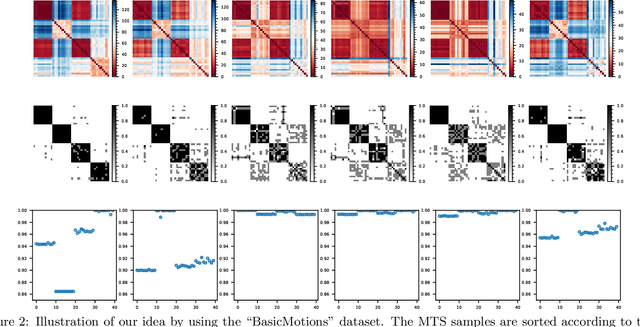
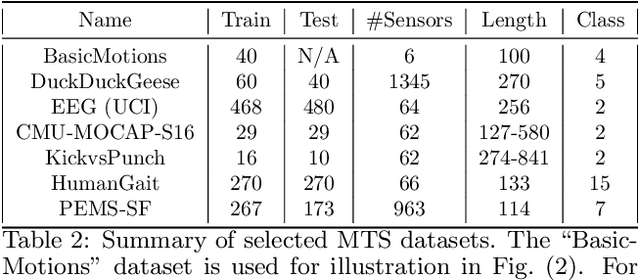
We introduce supervised feature ranking and feature subset selection algorithms for multivariate time series (MTS) classification. Unlike most existing supervised/unsupervised feature selection algorithms for MTS our techniques do not require a feature extraction step to generate a one-dimensional feature vector from the time series. Instead it is based on directly computing similarity between individual time series and assessing how well the resulting cluster structure matches the labels. The techniques are amenable to heterogeneous MTS data, where the time series measurements may have different sampling resolutions, and to multi-modal data.
Nationality Classification Using Name Embeddings
Aug 25, 2017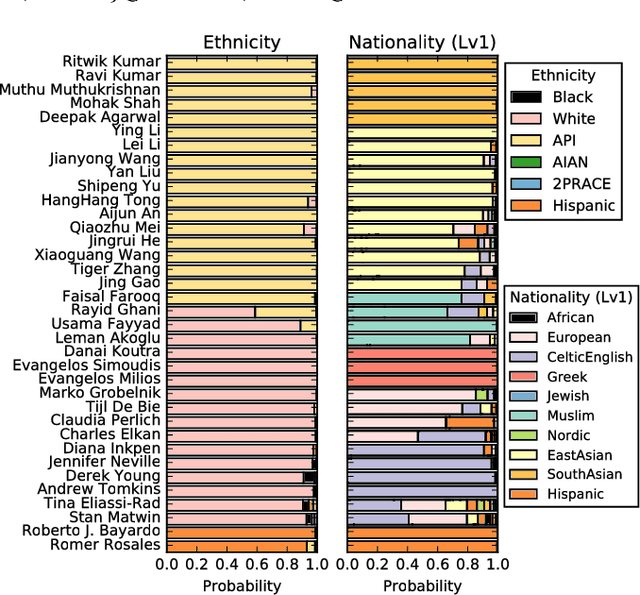


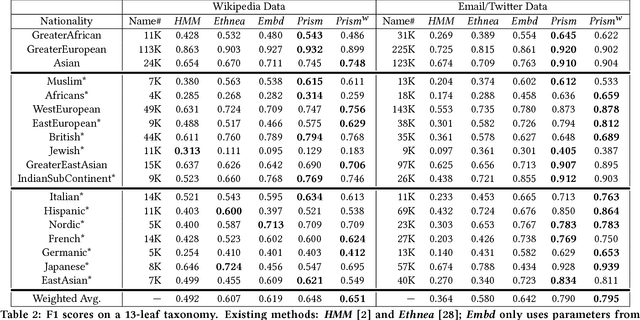
Nationality identification unlocks important demographic information, with many applications in biomedical and sociological research. Existing name-based nationality classifiers use name substrings as features and are trained on small, unrepresentative sets of labeled names, typically extracted from Wikipedia. As a result, these methods achieve limited performance and cannot support fine-grained classification. We exploit the phenomena of homophily in communication patterns to learn name embeddings, a new representation that encodes gender, ethnicity, and nationality which is readily applicable to building classifiers and other systems. Through our analysis of 57M contact lists from a major Internet company, we are able to design a fine-grained nationality classifier covering 39 groups representing over 90% of the world population. In an evaluation against other published systems over 13 common classes, our F1 score (0.795) is substantial better than our closest competitor Ethnea (0.580). To the best of our knowledge, this is the most accurate, fine-grained nationality classifier available. As a social media application, we apply our classifiers to the followers of major Twitter celebrities over six different domains. We demonstrate stark differences in the ethnicities of the followers of Trump and Obama, and in the sports and entertainments favored by different groups. Finally, we identify an anomalous political figure whose presumably inflated following appears largely incapable of reading the language he posts in.
Automatically Redundant Features Removal for Unsupervised Feature Selection via Sparse Feature Graph
Jun 30, 2017



The redundant features existing in high dimensional datasets always affect the performance of learning and mining algorithms. How to detect and remove them is an important research topic in machine learning and data mining research. In this paper, we propose a graph based approach to find and remove those redundant features automatically for high dimensional data. Based on the sparse learning based unsupervised feature selection framework, Sparse Feature Graph (SFG) is introduced not only to model the redundancy between two features, but also to disclose the group redundancy between two groups of features. With SFG, we can divide the whole features into different groups, and improve the intrinsic structure of data by removing detected redundant features. With accurate data structure, quality indicator vectors can be obtained to improve the learning performance of existing unsupervised feature selection algorithms such as multi-cluster feature selection (MCFS). Our experimental results on benchmark datasets show that the proposed SFG and feature redundancy remove algorithm can improve the performance of unsupervised feature selection algorithms consistently.