 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNationality Classification Using Name Embeddings
Paper and Code
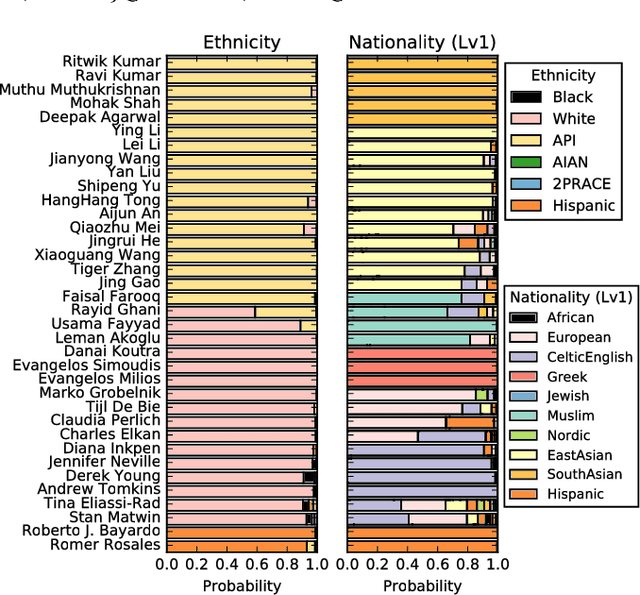


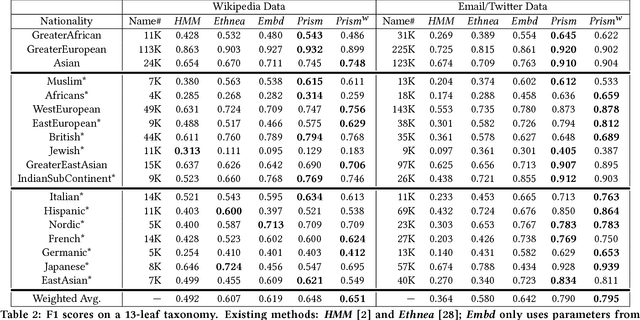
Nationality identification unlocks important demographic information, with many applications in biomedical and sociological research. Existing name-based nationality classifiers use name substrings as features and are trained on small, unrepresentative sets of labeled names, typically extracted from Wikipedia. As a result, these methods achieve limited performance and cannot support fine-grained classification. We exploit the phenomena of homophily in communication patterns to learn name embeddings, a new representation that encodes gender, ethnicity, and nationality which is readily applicable to building classifiers and other systems. Through our analysis of 57M contact lists from a major Internet company, we are able to design a fine-grained nationality classifier covering 39 groups representing over 90% of the world population. In an evaluation against other published systems over 13 common classes, our F1 score (0.795) is substantial better than our closest competitor Ethnea (0.580). To the best of our knowledge, this is the most accurate, fine-grained nationality classifier available. As a social media application, we apply our classifiers to the followers of major Twitter celebrities over six different domains. We demonstrate stark differences in the ethnicities of the followers of Trump and Obama, and in the sports and entertainments favored by different groups. Finally, we identify an anomalous political figure whose presumably inflated following appears largely incapable of reading the language he posts in.